
🖼️ Google shipped Gemini 2.5 Flash Image, aka nano-banana, a SOTA image generation and editing model
Google launches Gemini 2.5 Flash Image, Anthropic settles author lawsuit, and we unpack vibe-coding vs building production-ready AI systems.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-Aug-2025):
🖼️ Google shipped Gemini 2.5 Flash Image, aka nano-banana, a SOTA image generation and editing model
🚨 Anthropic Settles High-Profile AI Copyright Lawsuit Brought by Book Authors
🧑🎓 Vibe-coding and what it takes to build robust, production-ready system
🖼️ Google shipped Gemini 2.5 Flash Image, aka nano-banana, a SOTA image generation and editing model
The new Gemini 2.5 Flash model from Google represents a huge step ahead for image editing.
Key Takeaways
Maintains character consistency across multiple prompts and images.
Targeted edits/replacing objects using natural language.
Compose multiple images into one with a single prompt.
Accurately render text within your images.
$30 per 1 million output tokens (1 image == 1290 tokens or $0.39 cents).
The new Gemini 2.5 Flash model from Google represents a huge step ahead for image editing.
Availability
Try it right now on Google AI Studio.
It ships inside the Gemini app and developer platforms. Availability covers the Gemini app, Gemini API, Google AI Studio, and Vertex AI. Pricing is $30.00 per 1M output tokens, each image counts 1290 tokens, which is about $0.039 per image.
Functionalities
Better visual quality, stronger instruction following, and editing that keeps faces and objects stable.
Targeted, local edits happen by plain text prompts, for example remove a person, fix a stain, blur a background, change a pose, or recolor a single object, without breaking the rest of the frame.
Character consistency keeps the same person or product stable across shots, preserving hair, clothing, and logos. i.e. it maintain a character's identity across multiple images, changing their outfits, poses, and scenes without losing their core look.
🎨 Creative composition: Seamlessly merge elements from up to three different images into a single, cohesive masterpiece. The potential for surrealist art and unique compositions is endless.
Multi-image fusion merges several inputs into one output, like placing a chosen lamp in a bedroom photo or restyling a living room with a set palette.
Template adherence keeps layouts fixed for batches like real-estate cards or company badges while swapping subjects.
Gemini adds world knowledge, means the model brings general understanding of everyday things, so it knows what a sofa, window, or floor lamp is and how they typically appear together.
So the image model reads sketches or diagrams, understands object semantics, and follows compound instructions in one step.
i.e. it can look at a rough drawing or a labeled layout and figure out which shapes map to real objects and where they should go.
That cuts prompt juggling, because the model can act on a request like make it 2 shades darker and center the sofa under the window.
The editor supports multi-turn conversations, so you iterate with short follow-ups.
Google added build mode updates in AI Studio, with remixable template apps for quick testing, deploying, or code export.
Outputs carry an invisible SynthID watermark, and metadata identifiers are added for platform detection.
Blocked use cases include non-consensual intimate imagery, while everyday creative edits remain available.
Partners like OpenRouter bring reach to 3M+ developers, and fal. ai offers another production path.
Developers should expect early preview weak spots like long text rendering on images or very fine factual details.
Here is a simple code to run it.

Google's Gemini 2.5 Flash Image (Nano-Banana) takes the crown as the leading image editing model, beating GPT-4o and Qwen-Image-Edit in the Artificial Analysis Image Editing Arena!

Gemini-2.5-Flash-Image-Preview (“nano-banana”) ranks #1 in Image Edit Arena.

🚨 Anthropic Settles High-Profile AI Copyright Lawsuit Brought by Book Authors

Anthropic has settled a lawsuit from authors, who accused the company of illegally downloading and copying their books to teach its AI system, in among the first deals reached by creators over novel legal issues raised by the technology.
Context:
The central question in the case — and many others targeting AI firms — was whether fair use protects them. Fair use is a rule in copyright law that lets creators build on existing works without needing a license. In June, a judge ruled that Anthropic is covered, at least for training purposes. The court said authors cannot stop the company from using their books for training as long as Anthropic bought the books legally. The reasoning was that, like a reader learning to write, the AI system studies the works and then produces new creations.
Judge William Alsup described the technology as “among the most transformative many of us will see in our lifetimes.”
But Anthropic still faced trial over downloading 7 million books illegally to create a training library. Even though the company later purchased copies of those same books, the court said that did not erase the liability. That decision could have exposed Anthropic to massive damages and possibly open the door for Disney and Universal to pursue similar claims against Midjourney over allegedly copying thousands of films for training.
Shortly after the Anthropic’s case, the US Judge’s stance on fair use was echoed in another case against Meta by a group of authors, including Sarah Silverman. Judge Vince Chhabria found Meta’s training approach “highly transformative.” By learning from books, Meta’s Llama model can draft emails, create skits, and translate text, the court said.
Implications Now for Anthropic:
So now, Anthropic won’t have to go to trial over claims it trained AI models on ‘millions’ of pirated works. No December-2025 trial, and the fair use ruling for training on legally obtained books still stands.
Final approval is expected around September 3rd, but the exact terms are not public yet. The case began with authors alleging Anthropic trained Claude on books pulled from “shadow libraries” like LibGen without permission.
Judge William Alsup ruled in June that using lawfully obtained books for model training counts as fair use, which protects the training step itself. He also said keeping a central cache of pirated copies could violate rights, which is why the piracy claims were headed to trial.
In July, he certified a class with the court describing Anthropic’s conduct as “Napster-style downloading of millions of works,” which raised the stakes. Reuters reports up to 7,000,000 books were implicated, which pushed potential damages into the billions.
US law allows $750 to $150,000 per work depending on willfulness, which is how analysts got to eye-watering totals like $1T in worst-case scenarios.
The settlement avoids that damages roulette, but it does not erase the court’s split view on AI training versus content acquisition. Training on lawful copies got judicial cover, while sourcing from pirate mirrors and retaining those files did not, so compliance now lives in the data pipeline.
Teams will need auditable provenance for every corpus, including where each file came from, who licensed it, and when it was ingested. Expect stricter vendor contracts, stronger filters for “shadow-library” fingerprints, and processes to quarantine or delete suspect data fast.
The class certification and damages posture also explains why Anthropic sought appellate relief before settling, a sign of how risky a December trial looked.
The parties now have a binding term sheet, and related appeals are being placed on hold while the settlement process plays out. Settlements do not create precedent, but the operational lesson is immediate, treat training data like inventory with receipts.
This deal does not end Anthropic’s copyright exposure elsewhere, since music publishers are moving to amend their lyrics case to add BitTorrent allegations.
Those filings argue that lessons from the books case apply to lyrics datasets too, so provenance controls must span books, lyrics, and any other text sources.
🧑🎓 Vibe-coding and what it takes to build robust, production-ready system
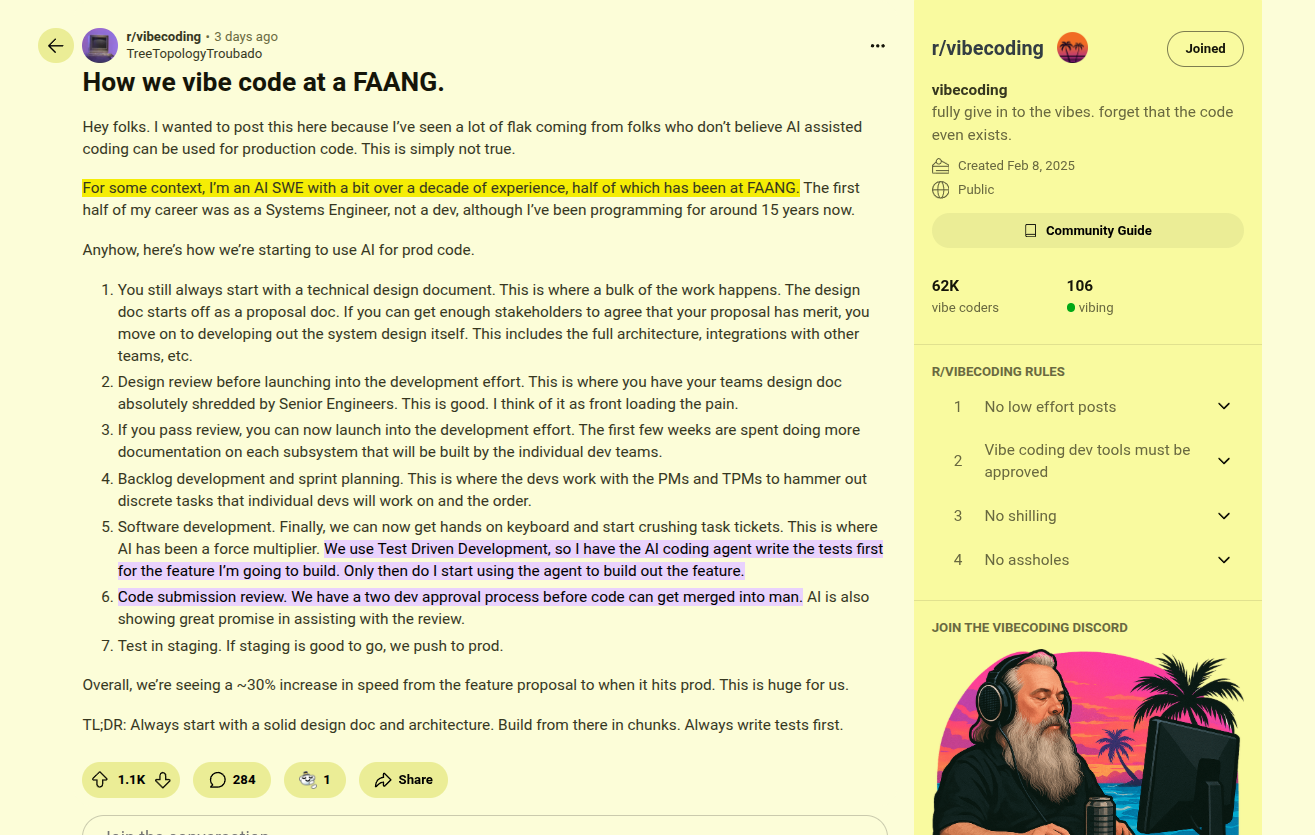
A Reddit thread recently shared how a FAANG team uses AI, sparking a debate about wording: is it just "vibe coding" or real "AI-assisted engineering"? Although the post framed it as the first, the described process—technical design docs, strict code reviews, and test-driven development—fits much more with the second, at least in my view.
⚡ What “vibe coding” really means
Vibe coding is high level prompting where you let the tool do most of the typing and you go with the flow. The culture around it is clear in recent coverage, like a fresh explainer that walks through how people pair plain language prompts with tools and finish small features fast, all while still needing human oversight for quality. The subreddit that popularized the term even describes it as “fully give in to the vibes, forget that the code exists,” which matches how newcomers use it to learn or hack together prototypes.
That approach is fun and useful for fast sketches. It is not a process for production software.
🏗️ What AI-assisted engineering looks like
The process described in the Reddit post for FAANG-level vibe-coding starts with a technical design doc, then a design review by senior engineers, then subsystem docs, then sprint planning, then Test Driven Development where the agent helps write tests, then 2-reviewer code review, then staging, then production. The author reports about 30% faster delivery from feature proposal to production, because the process is strong and AI accelerates the boring parts, not because process disappears.
That is AI as a collaborator inside an established lifecycle. The human stays in charge of architecture, tradeoffs, and the final call on every change.
🧭 Why the distinction matters
Pushing speed without guardrails can raise failure risk. Fresh reporting warns that teams chasing output with generative tools often ship more, yet let quality slide, which shows up as outages and expensive rework. Independent data also shows a split picture, company productivity does not automatically rise just because individual output rises. On top of that, a recent randomized test found experienced open source developers actually took 19% longer with early-2025 tools on their own repos, a reminder that tool fit and workflow matter more than hype. And day to day, developers still report time losses from organizational friction even as AI saves minutes in the editor.
So if you call a rigorous, reviewed flow “vibes,” you hide the real work that protects reliability.
🧪 Where AI actually helps in the lifecycle
Design, planning, and interfaces still need human judgment. After that, AI shines on scaffolding and checks. Agents can draft tests from specs, then help fill in code to satisfy them. There is even fresh guidance on flipping Test Driven Development by using AI to build the test suite first, then driving code to green, which many teams find natural with assistants.
Code review is the last mile where quality is won or lost. Recent write-ups highlight that seniors often see gains closer to 10%, while juniors can see up to 40%, and pushing more review intelligence into the pipeline is where returns keep showing up. Tooling is moving that way fast. Google’s new coding agent “Jules” posts changes as pull requests for humans to review, and it just added a “critic” that adversarially reviews its own diffs to catch issues before a human even looks. This pattern, agent proposes and humans approve, is safer for production.
🧰 A sane, repeatable flow you can copy
Start with a short design doc that states the problem, constraints, interfaces, and success tests. Ask AI to propose edge cases you missed, then refine the doc yourself. Move to subsystem notes for the team that will build them. Write the first set of tests, and let the assistant draft more variants. Generate the initial implementation with the tool, but read every line, and add comments where the model’s choices need justification. Run static checks and security scans, then open a pull request.
Use a 2-approver rule. Let an AI reviewer leave notes, but treat those like a junior reviewer, helpful but not the final say. Merge only after staging shows the feature holds up under load and failure injection. This is essentially the FAANG flow, with AI stitched into each stage, not driving the car on its own.
📉 Common traps that show up with “vibes only”
If you skip design, you get hidden coupling and migrations that hurt later. If you skip tests, you get brittle behavior that breaks on minor changes. If you skip review, you get silent regressions and security gaps. The current wave of cautionary stories from teams chasing speed only reinforces this pattern, ship fast, pay later.
✅ Quick checklist for tomorrow
Write a design doc before you code. Use AI to expand edge cases. Commit to Test Driven Development, with the agent generating tests that you edit. Require 2 human approvals. Let an AI reviewer comment, do not let it merge. Stage every feature. Track the real outcome, defects escaped, cycle time, change failure rate, not just lines of code or prompt tokens. Expect speed ups like 10% to 40% depending on developer experience and task type, then tune your pipeline for quality first.
Takeaway
Use vibes for prototypes, learning, and throwaway experiments. Use AI-assisted engineering for anything that must run in production. Keep humans accountable for architecture and reviews, let agents do the grunt work, and you can get gains like 30% without sacrificing reliability.
That’s a wrap for today, see you all tomorrow.