
🏆 Google Surprisingly released Gemini 2.0 Flash Thinking, a New “Reasoning” and “Thinking” model
Gemini 2.0's Flash Thinking, 4D physics breakthroughs, ChatGPT's app integrations, ModernBERT's advances, and NVIDIA-Apple collaboration reshape AI landscape.
Read time: 9 min 25 sec
⚡In today’s Edition (19-Dec-2024):
🏆 Google Surprisingly released Gemini 2.0 Flash Thinking, a New “Reasoning” and “Thinking” model
⚡New Groundbreaking 4D Physics Engine Revolution arrived, Write text, Get Instant physics
🔭 OpenAI announced its ChatGPT desktop apps can now work with Xcode, Warp, Notion, Apple and ~30 more, so it can see, understand, and automate your work in other apps.
📡A new BERT, ModernBERT is open-sourced, that overhauls traditional encoder models with 8K sequence support and 2-3x faster processing while maintaining BERT's practical simplicity.
🛠️ NVIDIA collaborated with Apple to bring up to 2.7x throughput boost on H100 GPUs for production-scale models.
🧑🎓 Top Lecture
🧠 AI Godmother Fei-Fei Li Has a Vision for Computer Vision
🏆 Google Surprisingly released Gemini 2.0 Flash Thinking, a New “Reasoning” and “Thinking” model
🎯 The Brief
Google DeepMind surprises everyone and launches a new “Thinking” and “Reasoning” model named Gemini-2.0-Flash-Thinking-exp. It based on Flash architecture with enhanced reasoning capabilities, achieving #1 rank across all Chatbot Arena categories. 32k context window
⚙️ The Details
→ The model introduces thought-based reasoning mechanisms integrated into the Flash architecture framework, representing a significant advancement in model architecture design. The implementation maintains 32k context window while optimizing for both speed and reasoning performance.
→ Currently deployed on Google AI Studio with no internet access functionality as of now, the model demonstrates superior performance metrics across all evaluation categories in Chatbot Arena benchmarks, suggesting robust generalization capabilities and enhanced reasoning pathways.
→ The model shows remarkable advancement from its predecessor (Gemini-2.0-Flash), moving from #3 to #1 in overall rankings. Performance metrics reveal comprehensive improvements across specialized domains, particularly in math and creative writing tasks, where it climbed from #2 to #1.
→ Most striking improvements appear in Hard Prompts and Vision categories, where despite already holding #1 positions, the model achieved substantial point gains (+14 and +16 respectively). The Style Control category saw significant progress, jumping from #4 to #1, indicating enhanced versatility in response generation.
→ You can try it out today in Google AI Studio and the Gemini API. The product lead of Google AI Studio also mentioned “This is just the first step in our reasoning journey”.
🧲 New Groundbreaking 4D Physics Engine Revolution arrived, Write text, Get Instant physics
🎯 The Brief
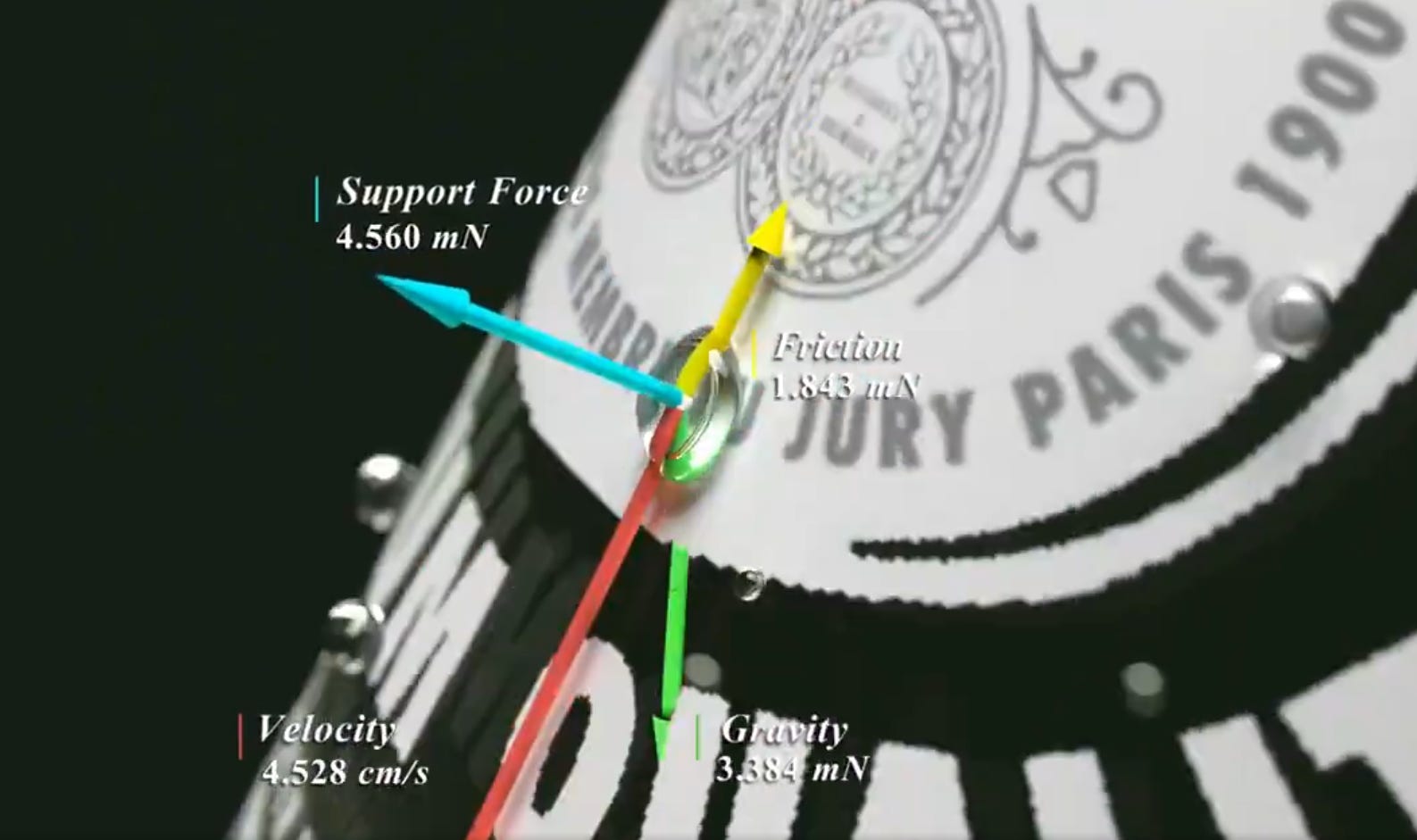
A research collaboration involving 20+ labs unveils Genesis - an open-source physics simulation platform that achieves 430,000x faster than real-time physics simulation, processing 43M FPS on a single RTX 4090. Built in pure Python, it performs 10-80x faster than existing GPU solutions like Isaac Gym, while integrating multiple physics solvers and generative AI capabilities. So basically it will give you everything you love about generative models — but now powered by real physics.
⚙️ The Details
→ Genesis's physics engine is empowered by a VLM-based generated agent that uses the APIs provided by the simulation infrastructure as tools to create 4D dynamic worlds, which can then be used as a foundational data source for extracting various modalities of data. Together with modules for generating camera and object motion, we are able to generate physically-accurate and view-consistent videos and other modalities of data
→ Includes text-to-physics generation capabilities, allowing creation of environments, camera motions, robot policies, and character animations from natural language prompts.
→ Genesis combines a universal physics engine with generative AI to create dynamic 4D worlds. The platform supports comprehensive simulation across rigid bodies, soft robots, fluids, deformables and elastic materials through various solvers including MPM, SPH, FEM, and PBD.
→ The system features cross-platform compatibility spanning Linux, MacOS, and Windows, with support for CPU, NVIDIA, AMD, and Apple Metal backends. Built-in photorealistic ray-tracing and differentiable simulation capabilities enhance visual fidelity and learning capabilities.
→ Platform demonstrates exceptional robotics performance, simulating 10,000 simultaneous Franka arm IK solutions in under 2ms. Can train real-world transferrable robot locomotion policies in just 26 seconds.
🏆 🔭 OpenAI announced (day-11) ChatGPT desktop apps can now work with Xcode, Warp, Notion, Apple and ~30 more.

🎯 The Brief
OpenAI unveiled major updates to their ChatGPT desktop apps, introducing integrated app control capabilities and voice interaction features. The system enables direct interaction with applications like Xcode, VS Code, Notes, Notion, and Quip through accessibility APIs, marking a significant shift toward automated desktop task assistance. Available to use with o1-Pro, too.
⚙️ The Details
→ The new features enable ChatGPT to work directly with desktop applications through keyboard shortcuts like option-space and option-shift-one. In Mac, hotkey to bring up ChatGPT is Option + Shift + 1. The system maintains user privacy by requiring explicit permission before accessing app content.
→ So now you can work With Apps on the computer and pull context from the app into the chat. It apparently only looks at whatever app you’re choosing to show it (even if there are other apps in its queue that you’ve shown it previously).
→ Integration with development environments allows real-time code assistance. The system supports VS Code, JetBrains ecosystem, Android Studio, PyCharm, RubyMine, Textmate, BBEdit, and MATLAB.
→ Warp console linked to GitHub is shown. Because the Warp console is being shown to ChatGPT, the user doesn’t have to tell ChatGPT what the output should look like. Now ChatGPT can get content internal in the app as well as the same visual that the user sees.
→ For document editing, ChatGPT now works with Apple Notes, Notion, and Quip. The system can understand document context and match writing styles while maintaining factual accuracy through web search integration.
→ They’re going to make it so you don’t need to copy + paste anything if the window is in ChatGPT’s view. Highlighting text helps the model know what to pay attention to. Demo’d how ChatGPT can match its writing to the user sample from the document it has in view.
📡A new BERT, ModernBERT is open-sourced, that overhauls traditional encoder models with 8K sequence support and 2-3x faster processing while maintaining BERT's practical simplicity.
🎯 The Brief
Answer.ai and LightOn introduce ModernBERT, a groundbreaking encoder-only model family that modernizes BERT with 8,192 token sequence length, 2-3x faster processing, and superior performance across retrieval, NLU and code tasks. The base model has 139M parameters while the large variant contains 395M parameters.
⚙️ The Details
→ Core Innovations: ModernBERT's core architecture combines RoPE positional embeddings with GeGLU activation layers and alternates between global attention (every 3 layers) and local attention (128-token windows). This hybrid approach plus efficient sequence packing enables superior token relationship modeling and optimized processing.
→ The training process spans 2 trillion unique tokens across web documents, code, and scientific articles. The three-phase approach involves 1.7T tokens at 1024 length, 250B tokens at 8192 length for long-context adaptation, and 50B tokens for final annealing.
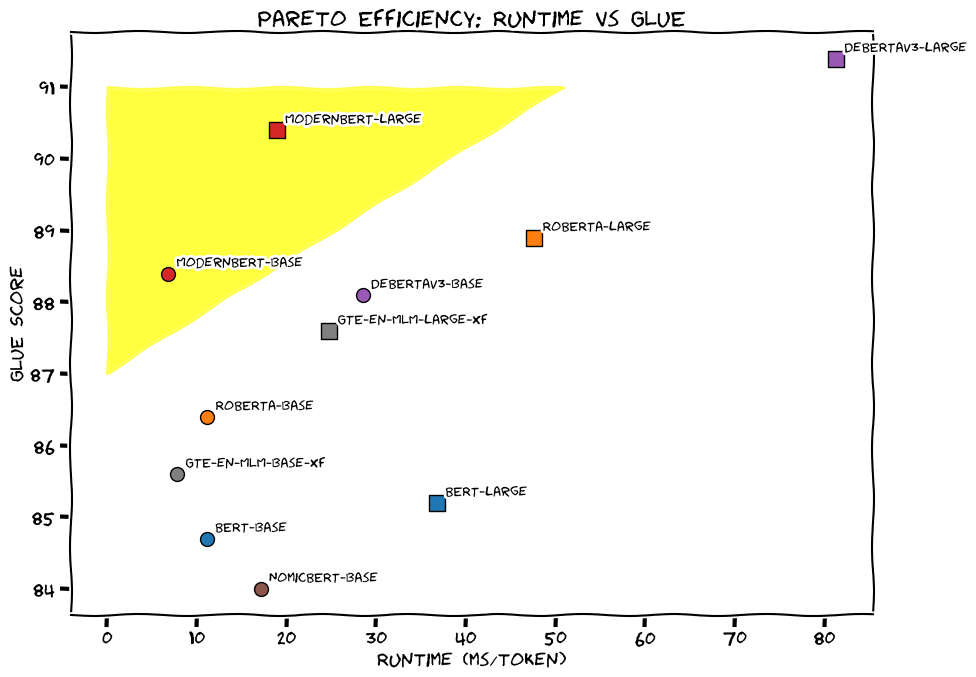
→ Performance metrics showcase significant gains - GLUE benchmark surpasses DeBERTaV3 while using 1/5th memory. For code tasks, it's the only model scoring over 80 on StackOverflow-QA. Retrieval capabilities show 9 percentage points improvement over existing long context models.
→ Practical deployment focuses on consumer GPU compatibility, with optimizations for RTX 3090/4090, A10, T4 and L4. The architecture balances efficiency through hardware-aware design and sequence packing techniques, delivering 10-20% speedup over previous methods.
⚖️ 🏆 Outperforms other encoder base models (BERT, RoBERTa, DeBERTaV3, NomicBERT, GTE-en-MLM) on downstream tasks in almost all settings. And its Apache 2.0 licensed!
🛠️ NVIDIA collaborated with Apple to bring up to 2.7x throughput boost on H100 GPUs for production-scale models
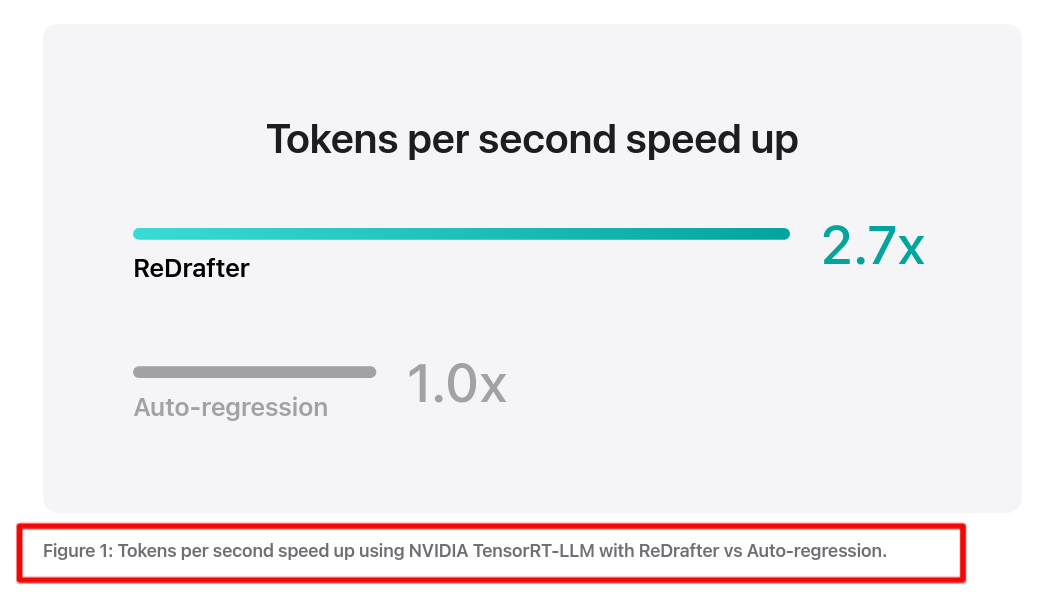
🎯 The Brief
Apple and NVIDIA’s collaboration brings ReDrafter, a novel speculative decoding technique, into TensorRT-LLM, achieving 2.7x throughput improvement on NVIDIA GPUs. This is a fundamental shift in how LLM inference workloads are processed, moving beyond simple batching to truly parallel execution paths.
⚙️ The Details
→ Earlier this year, Apple open sourced Recurrent Drafter (ReDrafter), a novel approach to speculative decoding that achieves state of the art performance. ReDrafter uses an RNN draft model, and combines beam search with dynamic tree attention to speed up LLM token generation by up to 3.5 tokens per generation step for open source models, surpassing the performance of prior speculative decoding techniques.
→ This integration required substantial modifications to TensorRT-LLM's core architecture. NVIDIA added new operators to support ReDrafter's unique beam search and tree attention algorithms, expanding the framework's capabilities for complex decoding methods.
→ A key innovation is the inflight-batching system, which intelligently manages parallel processing streams. The system splits operations into context and generation phases, processes them separately, and recombines them efficiently, maintaining continuous GPU utilization.
→ Production-grade implementation demonstrates significant efficiency gains: 2.7x speed-up in generated tokens per second for greedy decoding on production-scale models, while reducing GPU requirements and power consumption. The system supports empty tensors, enabling flexible batch compositions without performance penalties.
→ The technology's impact extends beyond pure performance metrics, enabling ML developers to efficiently deploy sophisticated LLM applications in production environments while maintaining generation quality.
🗞️ Google DeepMind introducs FACTS grounding, a leaderboard to benchmark if models generate factually accurate content
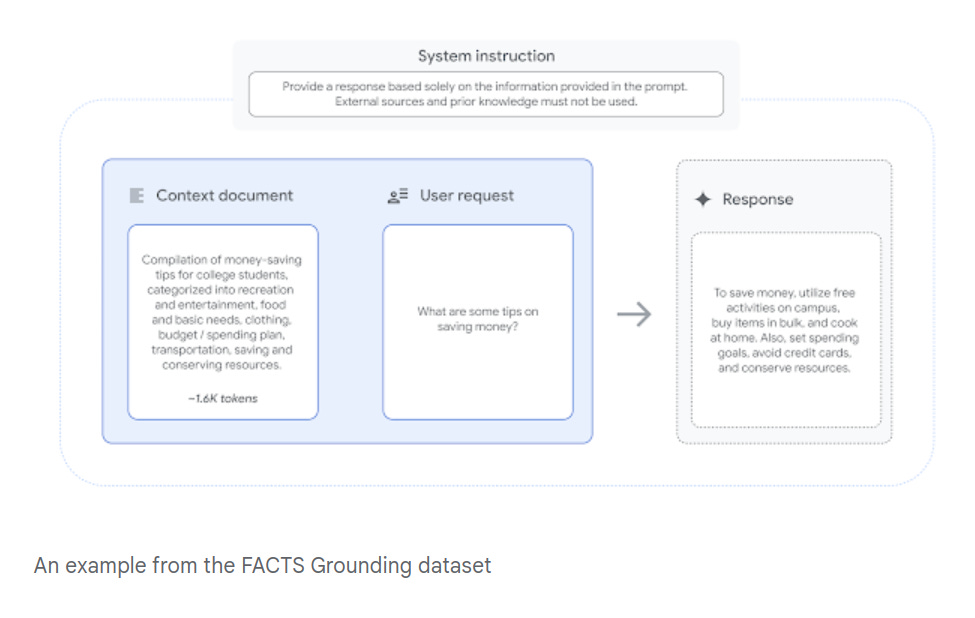
🎯 The Brief
Google DeepMind launches FACTS Grounding, a robust benchmark containing 1,719 examples to evaluate LLM factuality. Think of it as three AI fact-checkers making sure other AIs don't get creative with the truth. It sets new standards for measuring how accurately AI models ground their responses in source documents.
⚙️ The Details
→ The benchmark architecture employs three top-tier LLMs - Gemini 1.5 Pro, GPT-4, and Claude 3.5 Sonnet - as automated judges to eliminate potential bias from single model family evaluations. Each response undergoes rigorous eligibility checks and factual accuracy verification.
→ Dataset diversity spans multiple domains with documents up to 32,000 tokens, split between 860 public and 859 private examples. The public set enables open evaluation while private examples maintain benchmark integrity through controlled leaderboard assessment.
→ The evaluation methodology focuses exclusively on grounding capabilities, deliberately excluding tasks requiring creativity, mathematics, or complex reasoning. Responses must be both comprehensive answers to user requests and fully attributable to provided documents.
→ Final scoring aggregates judgments across all evaluator models and examples. The system specifically identifies ineligible responses that, despite being factually correct, fail to properly address user requests.
🧑🎓 Top Lecture
🧠 AI Godmother Fei-Fei Li Has a Vision for Computer Vision

🔬 Fei-Fei Li’s startup, World Labs, is giving machines 3D spatial intelligence
→ World Labs brings breakthrough innovation in spatial intelligence by transforming 2D images into fully explorable 3D environments. The system maintains physics compliance, object permanence, and artistic consistency - critical features missing in current video generation models.
In this long interview learn about:
→ Converting 2D inputs to physically accurate 3D scenes
→ Object permanence and physics enforcement in generated worlds
→ Style preservation across viewpoint changes
→ Handling massive compute requirements for 3D world generation
→ Spatial intelligence integration with robotics and AR applications
The system processes extensive training data to understand implicit spatial relationships, physics rules, and architectural coherence. This helps create believable environments where objects interact naturally - like basketballs bouncing correctly instead of disappearing.
Current implementation challenges include maintaining visual consistency across different perspectives and managing the heavy computational load required for real-time 3D scene generation.