
🧮 Google’s ‘Deep Think’ AI that earned Olympiad medals, is now available for everyone
Google’s medal-winning Deep Think goes public, leaked GPT 5 features, Qwen3-Coder-Flash released, Jensen Huang defends Meta’s $1B talent grab, Andrew Ng argues China could outrun US.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (1-Aug-2025):
🧮 Google’s ‘Deep Think’ AI that earned Olympiad medals, is now available for everyone
✂️ OpenAI disabled a ChatGPT feature when it found that private conversations were being indexed by Google
🦥 China’s Qwen just released their sixth model Qwen3-Coder-Flash: Qwen3-Coder-30B-A3B-Instruct
🗞️ Byte-Size Briefs:
OpenAI’s mysterious new model, “Horizon-alpha,” has quietly appeared on OpenRouter, setting off a wave of speculation.
Jensen Huang explained why Meta paying the rumored $1B package is justified. "A 150 or so AI researchers.
In a long post, AndrewYNg made the case that China has a growing shot at beating the U.S.
🧑🎓 The Humble Path from GPT 4.5 to 5: The Story Behind
🧮 Google’s ‘Deep Think’ AI that earned Olympiad medals, is now available for everyone
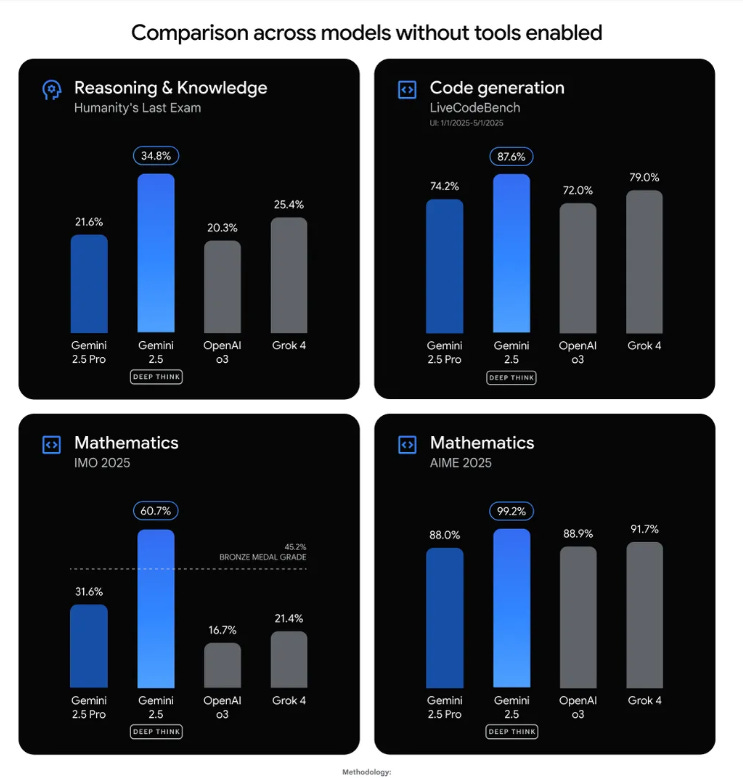
If you’re a Google AI Ultra subscriber, you can use Deep Think in the Gemini app today with a fixed set of prompts a day by toggling “Deep Think” in the prompt bar when selecting 2.5 Pro in the model drop down.
Google calls this release a “Bronze” variant because it runs faster and suits daily work, yet it trails the “Gold” version that scored 35 ⁄ 42 at the 2025 International Mathematical Olympiad. Access is gated behind the AI Ultra plan that costs $124.99 per month for the first 3 months and $249.99 per month afterward, and you switch it on by choosing Gemini 2.5 Pro in the app and toggling Deep Think.
Google explains that only a small group of mathematicians will experiment with the full Gold model while general subscribers receive Bronze. The Bronze release still clears internal Bronze-level IMO tests, but it sacrifices some depth to keep latency low. This staged rollout lets Google gather feedback from professional mathematicians on the high-end system while ordinary customers try a version that responds within practical time limits.
Deep Think builds on Gemini’s parallel thinking method, where the model spawns many candidate ideas at once and refines them during longer inference windows. Reinforcement learning then guides it toward stronger multi-step reasoning. In benchmark trials such as LiveCodeBench V6 and Humanity’s Last Exam it beats Gemini 2.5 Pro, GPT-4, and Grok 4 by double-digit margins, especially in coding, science, and advanced math.
Subscribers get a fixed number of Deep Think prompts per day, and each run can call tools like code execution and Google Search while producing longer answers than the standard model. Google says API access with and without tool integrations will reach trusted external testers in the next few weeks, and it highlights improved safety even though refusal rates on benign questions rise compared with Pro.
For enterprise and research leaders, Bronze Deep Think offers a practical preview of Olympiad-grade reasoning that can already assist with algorithm design, scientific literature analysis, and iterative product development. Meanwhile, the limited Gold pilot will reveal how far large-scale mathematical reasoning can advance when time constraints are removed, pointing to future high-precision AI services that go beyond today’s consumer models.
Availability: This bronze model is accessible to subscribers of Google’s most expensive individual AI plan, AI Ultra, which costs $249.99 per month with a 3-month starting promotion at a reduced rate of $124.99/month for new subscribers.
Why Gemini’s ‘Deep Think’ packs so much brainpower
Gemini 2.5 Deep Think builds on the original Gemini LLMs with some serious upgrades focused on complex problem solving. It brings in “parallel thinking,” where the model can juggle multiple ideas at once, plus reinforcement learning that keeps sharpening its reasoning over time.
It’s especially made for tasks that need longer, thoughtful processing—like scientific discovery, working through math problems, designing algorithms, or refining things like code and design ideas.
Some early users, including mathematician Michel van Garrel, have already pushed it into exploring tough problems and generating new proof ideas.
Architectural innovations
Deep Think’s defining feature is parallel thinking, where the model spawns many candidate reasoning paths at once during an extended “thinking time,” then merges the strongest ones into a final answer. Google couples this with novel reinforcement learning objectives that reward multi-step consistency and correctness rather than single-step fluency, so the model gradually prefers chains that lead to verifiable solutions.
A 1M-token context window lets the system ingest long papers, data dumps, images, audio, and video, while outputs can reach 192 000 tokens, enabling detailed proofs or large blocks of generated code. Under the hood it is a sparse MoE Transformer, so only the most relevant experts activate for each token, which decouples total parameter count from per-token compute cost.
Training relied on a broad multimodal corpus plus a specialized repository of mathematics and theorem-proving solutions that teach the network how to handle symbolic reasoning steps.
Training hardware and efficiency
Google trained Deep Think on TPU pods orchestrated by Pathways, which supply the high bandwidth memory and parallelism needed for long contexts and large expert sets. Extended inference time gives the model room to reason more deeply, but it also slows responses, so the bronze build caps this period to balance power and user experience.
✂️ OpenAI disabled a ChatGPT feature when it found that private conversations were being indexed by Google

❌ OpenAI pulled a ChatGPT sharing toggle after Google indexed thousands of shared chats. The slip proved how fragile trust is when privacy guardrails rely on a single checkbox.
Users discovered that a simple search query exposed shared chats, revealing names, job details, and personal health worries. The checkbox flow seemed safe on paper yet failed because many people skim warnings and hit share without thinking about search crawlers.
The issue started when users found out they could Google “site:chatgpt.com/share” and instantly access thousands of chat histories with the AI — many of them full of personal or private stuff.

People had shared everything from home improvement advice to confidential health concerns and even work-related info like resume edits, often including names and locations. Because of that, VentureBeat stayed away from linking to or describing any of the actual conversations.
OpenAI’s security team later said on X that the feature just left too much room for people to accidentally share things they didn’t want out in public.
“ This feature required users to opt-in, first by picking a chat to share, then by clicking a checkbox for it to be shared with search engines (see below).”

In September 2023 the same flaw hit Google Bard, and Meta’s assistant leaked chats soon after. Fast product cycles chase headlines but keep recycling the same privacy gap, showing that lessons from one launch rarely carry over to the next.
Enterprises leaning on AI, must nail down contracts covering retention, search blocking, and incident response. Secure defaults, harder-to-flip sharing toggles, and stricter review boards cost little but stop data spills before regulators call.
OpenAI halted the feature within hours, yet the event shows every AI team should ask how their tool behaves when a tired intern mis-clicks at 2 AM.
🦥 China’s Qwen just released their sixth model Qwen3-Coder-Flash: Qwen3-Coder-30B-A3B-Instruct

🚀 Qwen’s latest Coder-Flash packs 30.5B parameters but activates only 3.3B at runtime, letting a 64GB laptop host a snappy agent that reads 256K tokens natively and 1M with Yarn, while topping open-source coding benchmarks.
The Mixture-of-Experts design holds 128 experts but wakes just 8 per token, so compute stays low without shrinking overall capacity.
It stacks 48 transformer layers and splits attention into 32 query heads plus 4 key-value heads, a layout tuned for fast inference. The model runs smoothly on a 64GB Mac, and even on 32GB once quantized, thanks to that slim 3.3B active slice.
Custom function-call formatting and tight integration with Qwen Code and CLINE prime it for multi-step tool use in agent workflows. On SWE-Bench Verified and agentic browser tasks it edges other open models, matching Claude Sonnet and trailing only top proprietary giants.
NOTE: This model supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
🗞️ Byte-Size Briefs
OpenAI’s mysterious new model, “Horizon-alpha,” has quietly appeared on OpenRouter, setting off a wave of speculation. Many think it’s an unreleased OpenAI model, maybe an early version of GPT-5 or a smaller experimental variant. In early tests, somebody found it weak on LisanBench and not great at reasoning. But once reasoning mode was turned on, things shifted — the model could casually multiply 20-digit numbers, took ages to process its thoughts, and actually matched or beat Gemini 2.5 Pro on LisanBench. It also seems unusually good at generating SVGs. According to @teortaxesTex, it shines on abstract or poetic tasks, calling it a possible Sonnet replacement.
Jensen Huang explained why Meta paying the rumored $1B package is justified. "A 150 or so AI researchers, with enough funding behind them, can create an OpenAI. If you're willing to pay say $20B, $30B to buy a startup with 150 AI researchers. Why wouldn't you pay one?"
In a long post, AndrewYNg made the case that China has a growing shot at beating the U.S. in AI. He pointed to a thriving scene of open-weight models and serious momentum in semiconductor work. Even though the U.S. leads in closed models, many of the top open ones are now Chinese.
"There is now a path for China to surpass the U.S. in AI. Even though the U.S. is still ahead, China has tremendous momentum with its vibrant open-weights model ecosystem and aggressive moves in semiconductor design and manufacturing. While both the U.S. and China are behemoths, China’s hypercompetitive business landscape and rapid diffusion of knowledge give it tremendous momentum."- Andrew Ng
🧑🎓 The Humble Path from GPT 4.5 to 5: The Story Behind

Last minute GPT-5 analysis.
🔍 What went wrong with GPT‑4.5
Orion started life as the original GPT‑5 candidate, yet early tests showed only tiny bumps over GPT‑4o. Data quality held it back. Good web text is thinning out, and tricks that helped smaller research models quit working once the team scaled them. The company shipped the model anyway in Feb 2025 under the GPT‑4.5 name, but users moved on fast because they could not spot a clear step up.
🚀 How GPT‑5 changes course
Leadership ditched the dream of another GPT‑3 style leap and went for everyday usefulness. GPT‑5 will write cleaner, more complete code and handles math problems without odd corner‑case glitches. When you hand it a long to‑do list, it will keep track of edge cases like refund approvals or partial shipments instead of collapsing into generic answers. Under the hood it squeezes more work out of each floating‑point operation, so quality rises without a big jump in compute cost.
🛠️ Universal Verifier inside GPT‑5
The big architectural tweak is a reinforcement learning loop powered by a new Universal Verifier. Think of the verifier as a second model that sits beside the generator. After the main GPT‑5 draft lands, the verifier re‑reads the chain‑of‑thought and the final answer, then pushes back a single reward number. A high score keeps the draft, a low score triggers another try. This is called reinforcement learning with verifiable rewards (RLVR). The verifier patches that gap by acting as a tireless grader during fine‑tuning.
Recent leaks and research updates give pretty solid breadcrumbs that OpenAI really did bolt a “Universal Verifier” onto the GPT-5 training loop. OpenAI’s own researchers published Prover-Verifier Games Improve Legibility of LLM Outputs in Apr-2025, showing a production-ready pipeline where a verifier model scores each reasoning chain and feeds that reward back into policy updates. The paper is explicit that the verifier is small enough for large-scale rollout and is “designed for future GPT deployments,” a clear nod to the flagship model.
🛡️ Why OpenAI Needs a Universal Verifier: The o‑series taught engineers that raw reasoning strength fades once the chat layer is added. A universal verifier keeps that reasoning pressure on the chat student all the way through fine‑tuning. Unlike human preference models, it does not drift or get hacked as easily, and unlike domain‑specific rule sets, it can grade any topic the user throws at ChatGPT.
⚙️ Technical hurdles behind the scenes
Student chat models still show a dip in raw reasoning compared with their teacher models, and the pretraining pipeline is brushing up against the ceiling of usable public text. Synthetic data helps but carries its own bias problems, so engineers keep juggling filters and mixture‑of‑experts routing tricks to stay ahead.
🤝 People and politics shaping the roadmap
Morale took a hit when several senior researchers accepted big retention offers from Meta. Slack threads show head of research Mark Chen clashing with VP Jerry Tworek over resource allocations, and team shuffles added more tension. Some departures trace back to disagreements about how closely the lab should anchor to Microsoft versus keeping wider partnerships.
💼 Microsoft, money, and strategy
Microsoft holds exclusive rights to GPT models until 2030 and is negotiating roughly a 33% stake in the profit arm. At the same time OpenAI lawyers explore an IPO route, so both sides are sweating the term sheet wording. That financial dance partly explains the tilt toward commercially safe, incremental upgrades instead of risky moonshots right now.
GPT‑5 may not wow on benchmark headlines, yet its steadier code, tighter verifier loop, and leaner compute profile line up with what paying users actually need today.
That’s a wrap for today, see you all tomorrow.
Appreciate the insights on GPT 5. Interesting that benchmark expectations may not be a clear win with such a system. Especially with the Gemini Deep Think drop. Seems that Google has preempted OpenAI for once with parallel evaluations.