
🧠 Google’s Gemini launched free SAT preparation with full-length mock tests.
Google launches free SAT prep, Anthropic drops Claude’s full constitution, NVIDIA debuts PersonaPlex, Apple explores AI wearables, and CEOs question AI’s actual ROI.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-Jan-2026):
🧠 Google’s Gemini launched free SAT preparation with full-length mock tests.
🏆 Anthropic’s published new 80-page Claude ‘constitution’.
📡 On the universal definition of intelligence
🛠️ PwC’s 2026 Global CEO Survey suggests AI spending is outrunning AI returns.
👨🔧 Satya Nadella says AI has to earn the right to burn electricity by doing real work.
🍎 Apple eyes AI wearable race with AI pin
🧑🎓 NVIDIA has released PersonaPlex-7B-v1, a real-time speech-to-speech model built for natural, full-duplex conversations.
🧠 Google’s Gemini launched free SAT preparation with full-length mock tests.
The questions are grounded in The Princeton Review content. Like the actual SAT, there will be two sections: Reading and Writing, and Math.
After the test, Gemini gives immediate feedback on strengths and gaps, and it can explain any answer a student asks about. Till now, for SAT prep, the full-length practice has been harder, and you really had to pay good amount of dollar, because the experience needs consistent formatting and difficulty, not model-generated questions that drift away from test day.
Gemini addresses that by grounding the exam in a vetted question bank, then using chat to deliver the test and explain answers as needed. A student starts by prompting Gemini, then it steps through the 2 SAT sections, Reading and Writing plus Math, and records responses.
When it finishes, Gemini highlights specific knowledge gaps, and it can turn those into a customized study plan inside the same chat. Google further says more standardized tests are coming.
When the test begins, you’ll get each question individually. An active timer will show up in the top right, and immediate answer checking will display explanations below the question.

Questions can be skipped and revisited within a module at any time. You can close the test and continue later from the same chat. Submit at the end to get detailed feedback from Gemini, and ask for explanations if anything didn’t make sense.
🤖 China’s electricity generation climbing toward 10,000 terawatt-hours (TWh) and talk about targets like 20,000 TWh

AI datacenters don’t explain why China is pushing toward 20,000TWh of electricity. Training models doesn’t come close to needing that much power. The more likely answer is preparation for the massive energy demands of widespread robotics.
If you want a robot to lift, carry, push, drive, or manufacture stuff, you are moving mass around in the real world. That runs into basic physics, in need of MASSIVE energy.
You can make motors and power electronics better, and you can improve control software a lot, but you do not get the same kind of compounding efficiency curve you get in compute. A warehouse full of robots, a city full of delivery bots, factories with automated material handling, autonomous construction equipment, and farms full of machines all add up to a giant, steady demand for electricity.
🏆 Anthropic’s published new 80-page Claude ‘constitution’.

Details “Anthropic’s intentions for the model’s values and behavior,”
The document is designed to spell out Claude’s “ethical character” and “core identity,” including how it should balance conflicting values and high-stakes situations.
This is to act as a guide for outsiders so we can see the exact “policy text” Claude is trained to follow, instead of guessing from behavior, and so researchers can audit where Claude’s choices are intended vs bugs or product decisions.
The new constitution tries to teach the reasons behind behavior, so Claude can generalize rather than follow a checklist.
There’s also a list of overall “core values” defined by Anthropic in the document, and Claude is instructed to treat the following list as a descending order of importance, in cases when these values may contradict each other.
Broad safety, ethics, guideline compliance, and helpfulness.
Broad safety is defined as supporting legitimate human oversight, including not evading monitoring, shutdown, or correction.
It also keeps 7 hard constraints, including no serious help with mass-casualty weapons, major cyberweapons, or child sexual abuse material (CSAM).
Helpfulness is framed as frank, substantive help while weighing a principal hierarchy across Anthropic, operators, and end users.
Honesty is pushed close to absolute, discouraging lies, white lies, and manipulative framing that would erode trust.
A long section discusses Claude’s identity and welfare, admits uncertainty about consciousness, and argues for psychological security.
This document stresses that Claude will run into serious moral dilemmas. One example says that just like a soldier might refuse to fire on peaceful protesters, or an employee might refuse to break anti-trust laws, Claude should also refuse requests that help concentrate power in illegitimate ways, even if Anthropic itself makes the request.
Seems like Anthropic is pretty much preparing for the singularity.

📡 New University of Tokyo paper says intelligence is predicting the future well.

It also explains a common confusion, an agent that predicts well but cannot use it for gains should not be called intelligent. It says most popular definitions, like Intelligence Quotient (IQ) tests, complex problem solving, or reward chasing, break outside humans.
To keep comparisons fair, it grades any definition with 4 checks, everyday fit, precision, usefulness for research, and simplicity. After reviewing 6 candidate definitions, it says prediction is the strongest base, but it misses why smart behavior happens.
Its proposal is the Extended Predictive Hypothesis (EPH), intelligence is predicting well and then benefiting from those predictions. EPH splits prediction into spontaneous (self started, long horizon) and reactive (fast response), and adds gainability, turning prediction into better outcomes.
It checks this by showing EPH can explain the other definitions, and by proposing simulated worlds that score prediction accuracy and the payoff. That matters because it offers a practical way to compare humans and AI without human based tests, and it explains why current AI can look sharp yet still fall short.
🛠️ PwC’s 2026 Global CEO Survey suggests AI spending is outrunning AI returns.

PwC ties the gap to foundations, meaning integration-ready tech, data access that lets models answer with internal documents, and Responsible AI risk processes that let teams deploy in core workflows. Only 51% report a clear AI road map and only 29% say their main AI tool can access all company documents and data, so many projects start without the wiring they need.
Reported outcomes are mixed, with 30% seeing higher revenue, 26% seeing lower costs, and 22% seeing higher costs. PwC reports firms with strong foundations are 3x more likely to report meaningful returns, and it links broad AI use to about 4 percentage points higher profit margins, meaning more profit per dollar of revenue.
Most AI programs are not yet moving both sides of the profit equation at once, even when some firms see one metric shift in the right direction.

Only 12% report the best-case combo, costs down and revenue up
Many firms feel socially and technically “ready,” but fewer have the planning, governance, funding, talent, and data plumbing needed to turn AI pilots into business-wide systems.

👨🔧 Satya Nadella says AI has to earn the right to burn electricity by doing real work.

Speaking at the World Economic Forum in Davos, he also said the supply side still needs a “ubiquitous grid of energy and tokens,” and then every firm and worker needs to actually use the tools. His complaint is that society will not tolerate that power draw if the output feels like mostly transcription, summaries, and boilerplate code.
“People need to say, ‘Oh, I pick up this AI skill, and now I’m a better provider of some product or service in the real economy,” said Nadella. He did at least provide one real example of what he means by all this: “When a doctor can … spend more time with the patient, because the AI is doing the transcription and entering the records in the EMR system, entering the right billing code so that the healthcare industry is better served across the payer, the provider, and the patient, ultimately—that’s an outcome that I think all of us can benefit from.”
🍎 Apple eyes AI wearable race with AI pin

Apple is reportedly developing a screenless AI wearable about the size of an AirTag.
The device will include 2 cameras, 3 microphones, and Watch-style magnetic charging into a disc-shaped pin that clips onto clothing or bags.
It’s roughly the size of an Apple AirTag and includes multiple cameras, along with a microphone and speaker, with a possible launch as early as next year.
🧑🎓 NVIDIA has released PersonaPlex-7B-v1, a real-time speech-to-speech model built for natural, full-duplex conversations.
NVIDIA’s PersonaPlex-7B-v1 is a 7B speech-to-speech Transformer for full-duplex conversation, built on Moshi-style blocks with a Helium language model backbone.
It replaces automatic speech recognition (ASR), a language model, and text to speech (TTS) with 1 streaming model that listens and speaks.
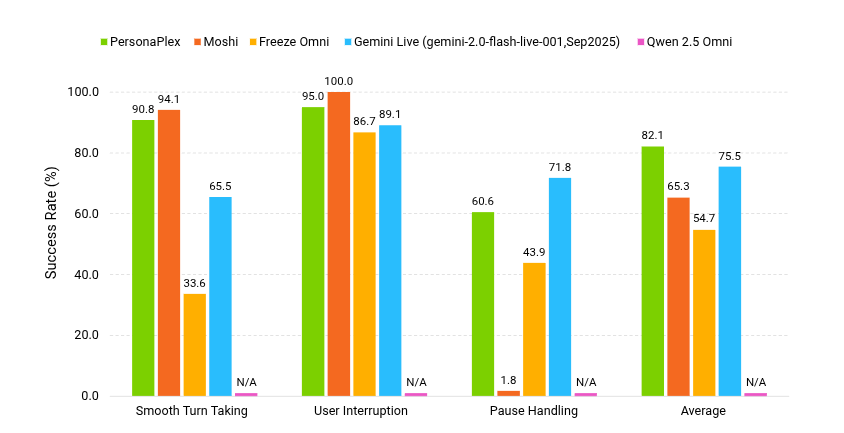
On FullDuplexBench, which tests turn timing under overlap, it averages 82.1% success, with 0.170s turn-taking time and 0.240s interruption time.
Cascaded voice stacks add delay and often break when the user interrupts, overlaps, or gives backchannels. PersonaPlex encodes 24kHz audio into discrete tokens with a Mimi codec and autoregressively predicts text tokens and audio tokens in a shared dual-stream state.
An audio-token voice prompt sets timbre and prosody, and a text prompt plus a 200-token system prompt sets role rules, trained on 1,217h Fisher phone calls plus 2,250h synthetic dialogs.
It scores 90.8% on smooth turn taking and 95.0% on interruptions, and its pause handling beats Moshi (60.6% vs 1.8%), though Gemini Live leads pauses at 71.8%.
That’s a wrap for today, see you all tomorrow.
If China’s electricity is that far ahead of North America, how do you think the U.S. is positioned in the robotics space relatively?