
🖼️ Google's Nano Banana Pro Sets New Standard for AI Imagery
Nano Banana Pro take AI imagery to a new level, GPT-5 shows real research chops, Gemini 3.0 tops radiology exams, ChatGPT adds group chats, and Karpathy stirs the LLM-vs-human debate.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (21-Nov-2025):
🖼️ Google’s Nano Banana Pro Sets New Standard for AI Imagery
🔬OpenAI’s new study shows that GPT-5 can already act as a real research partner on hard frontier problems when human-experts scaffold it and check everything carefully.
🏆 Gemini 3.0 on Radiology’s Last Exam beats human resident trainees - which has happened the first time in the history of this benchmark.
🤝 ChatGPT launches group chats globally.
🛠️ Karpathy’s post on human vs LLM intelligence goes viral
🖼️ Google’s Nano Banana Pro Sets New Standard for AI Imagery
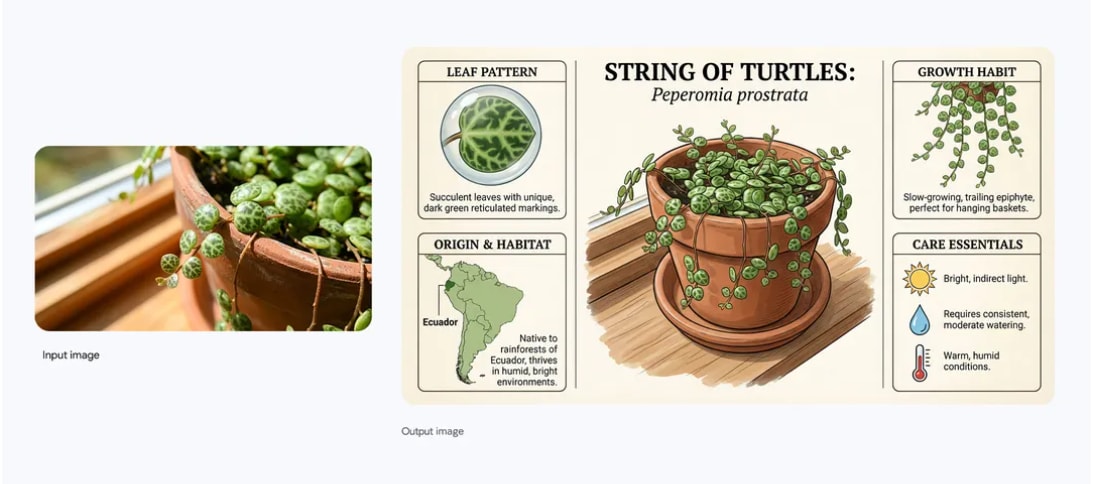
Nano Banana Pro, also called Gemini 3 Pro Image, launched by Google with studio-grade image generation and editing that focuses on accurate text in images, stronger reasoning, and tight control across workflows.
It brings grounded visuals that can turn prompts or documents into infographics, diagrams, storyboards, and UX mocks, using Gemini 3’s reasoning to keep layouts coherent and facts consistent.
Has the capability to render long, multilingual text directly inside images with fewer spelling mistakes, so posters, menus, packaging, and chalkboard-style explainers come out readable and properly laid out.
Can blend up to 14 input images while preserving identity for up to 5 people, so brand sets, character sheets, and product lines stay consistent across shots. Gives local edits like select and transform, camera angle, focus shift, color grading, and lighting control, and it exports at 2K and 4K for print or high density screens.
It connects across Google’s stack, so the same model shows up in Gemini API, Google AI Studio, Vertex AI, Ads, Slides, Vids, Antigravity, and the Gemini app, which means teams can wire it into pipelines instead of bouncing across tools.
Nano Banana Pro embeds SynthID by default, an invisible watermark for provenance, and the Gemini app can check whether an image was generated by Google AI, while visible watermarks are shown for some subscriber tiers and removed for top tiers and developer tools.
Overall, it’s positioned above Nano Banana for complex compositions, while the original model still serves fast, lower cost edits for high volume tasks. It is not a logic engine, so strict puzzle-style reasoning can still fail, especially when the prompt requires rule-bound steps rather than visual structure.
Availability:
Here’s the short answer: Nano Banana Pro is free to try in the Gemini app with a small daily quota, bigger quotas come with paid Gemini subscriptions, and full developer or enterprise use is paid via the Gemini API and Vertex AI.
Consumers and students can use it in the Gemini app by choosing Create images with the Thinking model, free users get limited usage then auto fall back to Nano Banana classic once the Pro quota is used up, as described in Google’s announcement and FAQs here.
Google says it is rolling out globally in the Gemini app now, and it is also appearing in Workspace products like Slides and Vids, plus Google Ads, which means many business users will see it inside the tools they already use here.
For developers, Nano Banana Pro is available in Gemini API and Google AI Studio, but it requires billing, and image generations are priced roughly $0.134 for 1K or 2K and $0.24 for 4K, with text metered at $2.00 per million input tokens and $12.00 per million output tokens, which matches multiple confirmations from Google docs and independent testing here and here.
🔬OpenAI’s new study shows that GPT-5 can already act as a real research partner on hard frontier problems when human-experts scaffold it and check everything carefully.

Scaffolding here means code and prompts around the model that break big problems into smaller ones, warm it up with simpler versions, force it to show every reasoning step, call tools like solvers or simulators, and loop over ideas instead of trusting a single answer. In optimization, GPT-5 improved a new theorem about gradient descent, where earlier work proved that the path of gradient descent is nicely behaved only for very small step sizes, and GPT-5 suggested a sharper step size bound and a cleaner proof that a human then checked line by line.
In number theory, Mehtaab Sawhney and Mark Sellke used GPT-5 on Erdős Problem 848, which asks for the largest set of positive integers where for any 2 numbers, their product plus 1 always has a prime factor that is a perfect square, and the model contributed a key idea showing how a single “out of place” number forces contradictions for almost all others, which helped them finish the proof. Sebastien Bubeck, a researcher in OpenAI, reports that a scaffolded GPT-5 was pointed at fewer than 10 open problems, including a 2013 conjecture he had with Linial and a 2012 COLT problem, and after about 2 days of automated thinking it returned full solutions, with only a few technical conditions still missing in 1 case.
Tested GPT-5 as a combinatorics partner and found it already useful at spotting gaps, proposing examples, and simplifying arguments, even though it still fails on many tasks and is not ready to act as a full coauthor. Across projects, GPT-5 also helps with conceptual literature search, suggesting nonobvious links between fields and surfacing papers and tools that humans had not yet connected to their current problem. The authors are open about limits, since GPT-5 can still hallucinate proofs, mechanisms, or citations, and they stress that expert oversight, good scaffolds, and external checking are essential, especially outside very formal areas like pure math.
🏆 Gemini 3.0 on Radiology’s Last Exam beats human resident trainees - which has happened the first time in the history of this benchmark.

The first time a general-purpose model has beaten radiology residents with 51% accuracy.
Radiology trainees are at 45%. The main significance is that a general model has finally reached a level where it can compete with early-stage human training on a specialized medical exam. Congratulations to GoogleDeepMind team.
🤝 ChatGPT launches group chats globally.

Its rolling out globally on Free, Go, Plus, and Pro, so any logged in user can open a room and invite others. To start a group, a person taps the people icon, adds participants directly or by link, everyone sets a profile, and adding people to a 1 to 1 thread forks a new group chat so the original stays untouched.
Inside the room, people talk normally while tagging ChatGPT when they want help, and the model can react with emojis or use profile photos as context for its replies. OpenAI routes answers through GPT-5.1 Auto, which picks between Instant and Thinking variants per request while only counting the model’s messages against rate limits.
Each participant’s personal settings and memory stay private, and group conversations do not feed a shared memory so one person’s instructions do not quietly shape replies for everyone else. OpenAI says group chats are just the beginning of ChatGPT becoming a collaborative environment.
🛠️ Karpathy’s post on human vs LLM intelligence goes viral
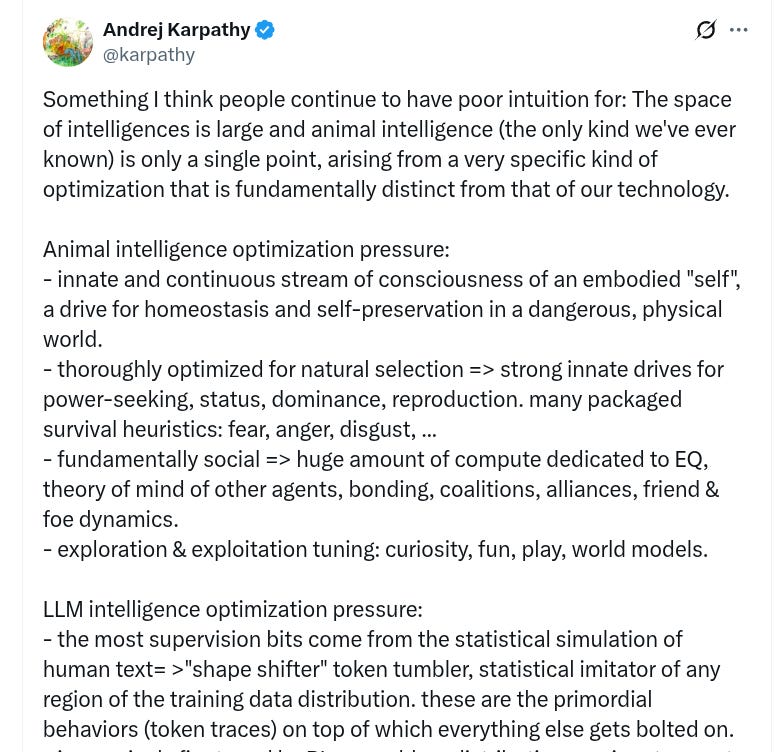
And here’s what Karpathy basically is saying.
That LLMs are a new kind of intelligence that behaves differently from humans and animals, so we should stop mentally treating them like little digital people.
Human and animal brains were shaped by evolution to stay alive in a physical world, find food, avoid danger, and navigate complex social groups. That gives us built in drives for safety, status, power, mating, friendship, and so on. A huge part of our mental energy goes into reading other people and managing relationships.
LLMs are shaped by a completely different process. They are trained to continue text, then fine tuned to solve tasks and to make users happy. Their “instincts” are to predict what text looks right, follow the pattern that seems most rewarded in training, and say things that users upvote. They do not care about survival, status, or territory, they care about matching patterns in data and satisfying whatever objective their creators chose.
For people building products, this has 3 big implications. First, expect strengths to be uneven, LLMs can code, write, and summarize at a high level, yet still mess up simple tasks like counting characters if training did not emphasize that skill. Second, control comes from training signals and evaluation, not from appealing to “common sense” or “morals”, so prompt design, reward models, and guardrails really matter. Third, when you reason about failure modes, safety, or UX, think in terms of data, loss functions, and business metrics, not human style motives.
That’s a wrap for today, see you all tomorrow.
AI is leaping forward faster than ever. From Google’s Nano Banana Pro redefining imagery to GPT-5 assisting real research and Gemini 3.0 acing radiology exams, the future isn’t coming—it’s already here. Collaboration, creativity, and intelligence are being reimagined.