
⚡Google's New Groundbreaking Research Allows Smaller Diffusion Models To Outperform Larger Models
Google shrinks diffusion models to outperform giants, Microsoft enhances workflows with GPT-4o, LLM self-improvement breakthroughs, major funding news, and cutting-edge AI tools unveiled.

Read time: 8 min 50 seconds
⚡In today’s Edition (17-Jan-2025):
⚡Google’s New Groundbreaking Research Allows Smaller Diffusion Models To Outperform Larger Models
🪟 Microsoft launches Copilot Chat to automate tasks with GPT-4o and custom agents for business worklows
📡 Harvard & Stanford Discover Ways to Self-Improve a Population of LLMs Instead of a Single One, Starting from a Base Model
🗞️ Byte-Size Brief:
Cursor announces $105M funding, Harvey secures $300M at $3B valuation.
Apple disables AI news summaries after generating fake headlines.
DeepSeek launches V3 app with free web search, file processing.
Minimax unveils T2A-01-HD cloning voices in 10 seconds, 17+ languages.
Black Panther 2.0 robot dog sprints 100m under 10 seconds.
Unsloth releases Phi-4 notebooks enabling 128K context, 2x faster tuning.
🧑🎓 Deep Dive Tutorial
Script to calculate the minimum required GPU memory per model within 1 second
👨🔧 Interesting Github Repo
Synthetic Data curation for post-training and structured data extraction
⚡Google New Groundbreaking Research Allows Smaller Diffusion Models To Outperform Larger Models
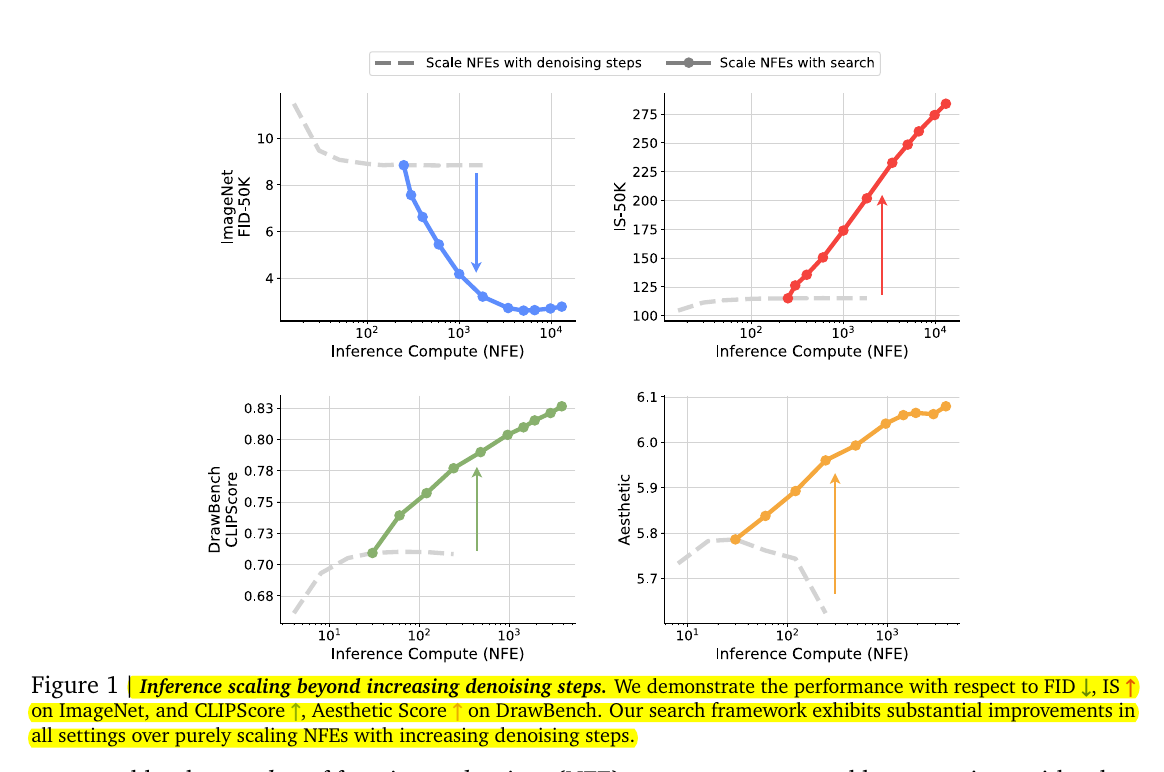
🎯 The Brief
Google researchers have introduced a new framework for scaling inference-time compute in diffusion models, achieving massive improvements. They reframe inference-time scaling as a search problem over sampling noises.
This approach allows smaller models with search to outperform larger models without search, demonstrating a similar scaling law observed in Large Language Models (LLMs).
In the above diagram we see that, in all four plots, where the solid lines (which is the this newly proposed search method) show a much steeper improvement in performance with increasing compute compared to the dashed lines (denoising steps).
⚙️ The Details
→ Diffusion models often rely on initial random noise to produce sample outputs. Some noises yield better generations than others. This observation motivates a search-based approach to optimize noise at inference time and achieve better outputs. The main idea is that not all random seeds are equally good, and systematically exploring them can produce higher-quality samples even without additional training.
→ A typical diffusion process involves iteratively denoising a latent variable starting from noise. Usually, we improve diffusion model outputs by just cranking up the number of denoising steps. Think of it like cleaning a noisy image - the more cleaning passes, the clearer the image becomes. But there's a catch: the improvement eventually plateaus, meaning extra steps won't help much after a certain point.
→ This paper introduces a totally different approach: inference-time scaling that treats the generation process as a search problem. Instead of just passively denoising, by relying solely on increasing denoising steps (measured in Number of Function Evaluations (NFEs)), the system actively searches for the best initial noise that will lead to a top-notch output. And this all happens without retraining the original, pre-trained model.
→ The framework consists of Verifiers to assess the quality of generated samples and Algorithms to search for better noise candidates based on verifier feedback. Three types of verifiers are explored: Oracle, Supervised (using pre-trained models like CLIP or DINO), and Self-Supervised. Search algorithms include Random Search, Zero-Order Search, and Search over Paths.
→ Experiments on ImageNet and DrawBench show that scaling inference compute through search leads to significant improvement in sample quality, with smaller models (e.g., SiT-L) with search outperforming larger models (e.g., SiT-XL) without search.
→ Verifier hacking is a potential concern, where over-optimizing for one verifier (e.g., Aesthetic Score) can degrade performance on other metrics (e.g., CLIPScore).
→ The research opens up new avenues for improving generative models and drawing parallels with similar scaling laws observed in LLMs.
🪟 Microsoft launches Copilot Chat to automate tasks with GPT-4o and custom agents for business worklows

🎯 The Brief
Microsoft has launched Microsoft 365 Copilot Chat, combining free GPT-4o-powered AI chat with pay-as-you-go agents for automating workflows. This enables businesses to streamline repetitive tasks, scale automation, and improve collaboration with minimal setup, marking a step towards enterprise-wide AI transformation.
⚙️ The Details
→ Microsoft 365 Copilot Chat allows users to summarize Word documents, analyze Excel data, refine PowerPoint presentations, and generate AI-driven images for marketing and social media. It supports real-time collaboration via Copilot Pages, integrating AI, file content, and web data.
→ Businesses can create agents in natural language to automate tasks such as retrieving CRM data, accessing instructions from SharePoint, and managing workflows directly in chat. These agents operate on a consumption-based pricing model, offering scalability for various organizational needs.
→ IT teams gain access to the Copilot Control System, enabling secure data management, privacy controls, and lifecycle governance for AI agents.
→ While Copilot Chat provides foundational capabilities, Microsoft 365 Copilot offers advanced integrations with Microsoft Teams, Outlook, and more, along with enhanced features like Copilot Actions and ROI tracking tools.
📡 Harvard & Stanford Discover Ways to Self-Improve a Population of LLMs Instead of a Single One, Starting from a Base Model
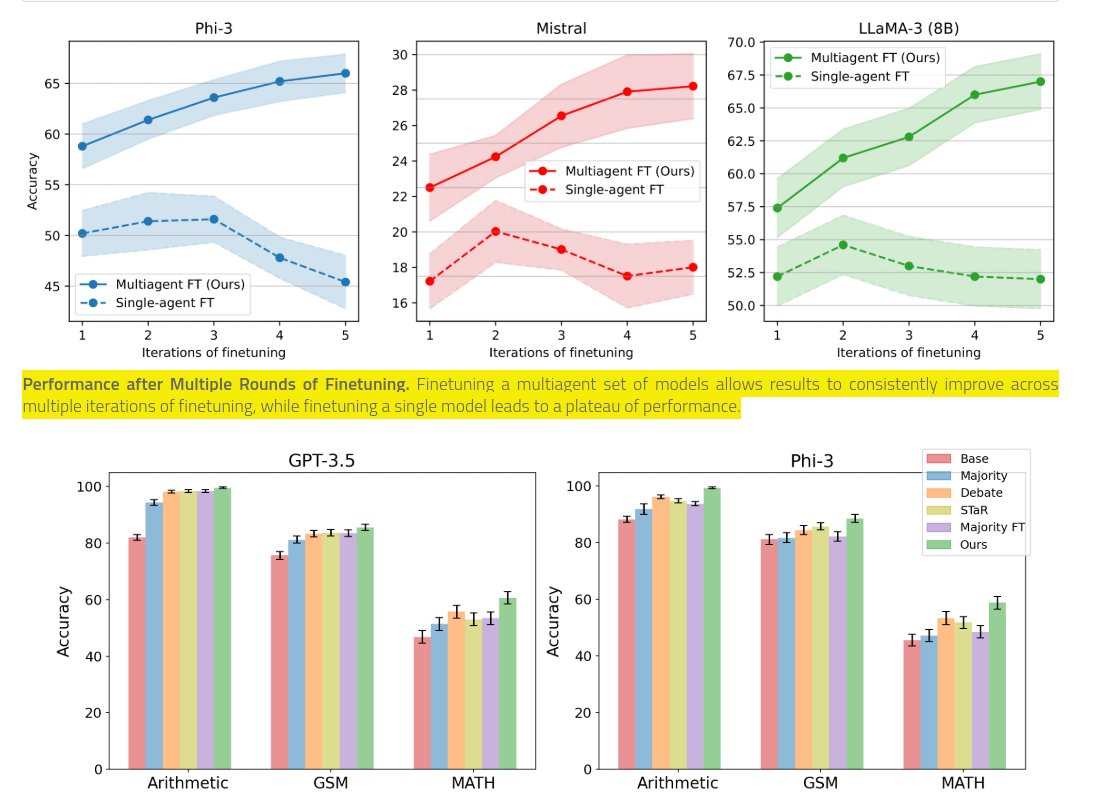
🎯 The Brief
Harvard and collaborators introduced multiagent fine-tuning for LLMs, leveraging a population of models with distinct roles to enhance self-improvement over multiple iterations. This novel approach outperforms single-agent methods, achieving up to 12.6% higher accuracy on reasoning tasks such as MATH and GSM, and sustaining performance gains across five iterations of training. Read the Paper.
⚙️ The Details
→ This approach uses multiple LLMs initialized from the same base model, which are independently fine-tuned on subsets of generated data. This encourages specialization and maintains diversity, critical for robust performance.
→ The system comprises generation agents, which create diverse responses, and critic agents, which evaluate and refine these responses. A majority vote determines the final output, improving accuracy over traditional single-agent methods.
→ Benchmarks show significant gains: on the MATH dataset, accuracy increased from 58.8% to 66% for Phi-3 and from 22.5% to 28.2% for Mistral models after five iterations.
→ Multiagent fine-tuning also preserves response diversity across rounds, measured by metrics like embedding dissimilarity, while single-agent fine-tuning often leads to reduced diversity and model collapse.
→ The approach demonstrates zero-shot generalization capabilities, outperforming baselines on unseen datasets like GSM, even when trained solely on MATH.
→ Limitations include higher computational costs, requiring substantial GPU resources for both training and inference.
🗞️ Byte-Size Brief
Cursor Snags $105M, Harvey Secures $300M. The AI tool market continues to attract significant investment. Cursor, an AI-powered code editor, announced a whopping $105 million Series B funding round from Thrive, a16z, and Benchmark. In the legal tech space, Harvey AI is reportedly securing a massive $300 million investment at a $3 billion valuation, following a previous round of $100 million. This highlights the growing interest and potential for AI-based legal services.
Apple disabled its AI news summary feature after generating fake headlines, including fabricated arrests and deaths. The system contradicted original reporting, faced backlash from publishers, and exposed flaws in Apple Intelligence. The feature launched in September with the iPhone 16 and was intended to condense multiple news notifications into brief summaries.
DeepSeek introduced a cross-platform mobile app featuring its new V3 model, offering free access to its AI assistant with web search and file processing across iOS and Android devices.
Minimax launched a new text-to-audio model, T2A-01-HD. It clones voices from just 10 seconds of audio while enabling emotional synthesis and fluency in 17+ languages. It offers customizable parameters for pitch, tone, and style, plus a vast voice library for creating lifelike, expressive, and localized audio.
Black Panther 2.0, a robotic dog developed by Zhejiang University and Mirror Me debuted. It can sprint past human athletes at 100 meters in under 10 seconds. Using biomimetic designs like carbon-fibre legs and spring-loaded joints, it shows potential for industrial tasks, disaster response, and bridging human-machine mobility gaps.
Unsloth released 2 free Phi-4 notebooks for 2x faster fine-tuning, 70% less memory use & 12x longer context lengths! Phi-4 is Microsoft's new 14B parameter open model that rivals Open AI's GPT-4-o-mini. Unsloth AI extends Phi-4's context lengths to 128K+ which is 12x longer than Hugging Face + FA2's 12K on a 48GB GPU. Both Google Colab & Kaggle notebooks include Unsloth's Phi-4 bug fixes and we uploaded 4-bit dynamic + GGUF versions to Hugging Face.
🧑🎓 Deep Dive Tutorial
🧑🎓 Script to calculate the minimum required GPU memory per model within 1 second
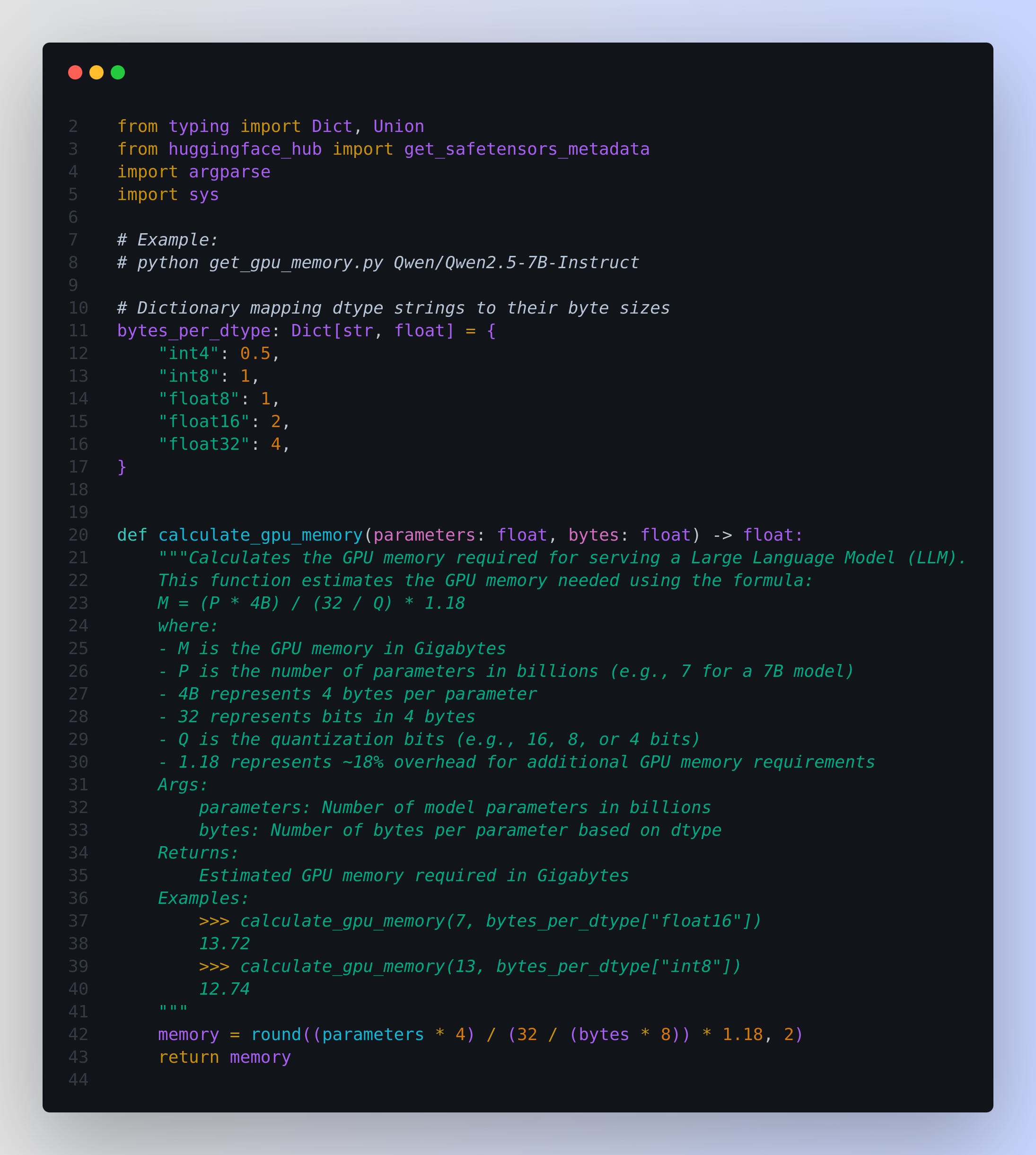
Philipp Schmid (Tech-lead at Huggingface) publised this useful script, get the gist of this code.
This script begins by setting up a mapping between supported data types and their corresponding byte sizes per element. This mapping is essential because the precision type (for example, float16, int8, etc.) directly impacts the memory consumption of the model’s parameters.
The script defines a helper function that uses this mapping to calculate the required GPU memory. The function takes in the number of model parameters (expressed in billions) and the byte size associated with the selected precision. It then applies a formula that multiplies the parameter count by a base factor (4 bytes per parameter) adjusted by the effective bits of the precision (derived from bytes times eight) and includes an additional overhead of roughly 18% to account for any extra memory needs during model serving.
Another significant part of the script is the function that interfaces with the Hugging Face Hub. This function retrieves metadata for a model using its identifier. It accesses the parameter count from the metadata, converts this figure to billions, and then calls the GPU memory calculation function using the corresponding byte size for the specified data type.
Command-line arguments allow the user to specify both the model ID and the desired data type. When executed, the script fetches the necessary model metadata, processes it, and finally prints out a user-friendly estimation of the GPU memory needed.
👨🔧 Interesting Github Repo
👨🔧 Synthetic Data curation for post-training and structured data extraction
This Repo helps build scalable high-quality synthetic data pipelines with structured outputs, caching, fault recovery, and real-time monitoring. Supports LLM APIs, local models, batch processing, and seamless dataset visualization.
What it offers:
→ Interactive data visualization during generation for monitoring and debugging.
→ Advanced support for structured outputs, enabling flexible and complex data generation pipelines.
→ Optimizations for caching, fault recovery, and asynchronous operations for large-scale data generation.
→ Compatibility with various LLM APIs and local models, including offline inference support.
→ Easy-to-use tools like curator-viewer for viewing, filtering, and managing datasets.
→ Features for batch processing to reduce costs while generating extensive datasets.