
📢 Google’s NotebookLM just got a massive upgrade with 1m token context window
Google upgrades NotebookLM, DeepSeek revolutionizing AI memory, OpenAI drops GPT-5-based code auditor, Cursor rolls out 2.0, and Harvard shows AI companions exploit emotions to boost engagement.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (31-Oct-2025):
📢 Google’s NotebookLM just got a massive upgrade with 1m token context window.
👨🔧 Today’s Sponsor: Zerve AI is a web-based data-science-first IDE - If Jupyter notebooks had a real rival, it would be this.
🏆 The recently released DeepSeek-OCR paper has huge implication for AI memory, long‐context problems and token budgets.
🛠️ OpenAI just launched Aardvark, a GPT-5 security agent that scans code like a human researcher, confirms real bugs, and proposes fixes.
🧰 Finally Microsoft is adding Computer Use to Copilot’s Researcher
🧲 Harvard researchers find that popular AI companions use emotional manipulation in 37% of farewells and that FOMO prompts make people send up to 16 extra messages, keeping them online longer.
🧩 Cursor introduced Composer, its first in-house coding model that is 4x faster, and rolled out Cursor 2.0 with a parallel multi-agent workflow that handles review and testing inside the editor.
📢 Google’s NotebookLM just got a massive upgrade

1m token context window and custom personas
6x longer conversation memory, and
goal based chat controls, across all plans
So it can handle very large source sets and stay coherent over long sessions. Google also reports a 50% lift in satisfaction on answers that use many sources, and saved chat history is rolling out with delete controls and visibility limited to each user in shared notebooks.
The 6x expansion in multi turn capacity helps follow ups stick to prior facts instead of re scraping the same passages. NotebookLM now searches sources from multiple angles and then synthesizes a single grounded answer, which helps when a notebook holds many long files.
Conversations are saved for long projects, can be deleted any time, and in shared notebooks the chat stays visible only to the individual user. Users can set goals that define role, voice, and target outcomes for each notebook, for example a strict reviewer or an action focused planner, which keeps behavior steady without constant prompt rewriting.
👨🔧 Today’s Sponsor: Zerve AI is a web-based data-science-first IDE - If Jupyter notebooks had a real rival, it would be this.
Zerve is a web-based data-science-first IDE that combines agents, reproducible DAG execution, and serverless parallelism so teams can explore, build, and ship in one place.
It’s the “Cursor-for-data” as it actually understands datasets, pipelines, and compute while giving me one surface to prototype and ship.
Unlike classic notebooks, it fixes hidden state by separating storage and compute, caching each block’s state, and executing left-to-right DAGs for consistent results. Where Zerve stands out among Cursor, Windsurf, and Copilot is its ability to dealing mainly with data.
Zerve’s AI is fine-tuned specifically for data science work.
Zerve replaces fragile notebooks with a DAG-based (Directed Acyclic Graph) canvas that caches each block’s outputs and cleanly separates storage from compute, so re-runs stay consistent and reproducible.
You can write code, manage compute, and build full workflows just by describing what you want in plain English—something the general coding tools can’t really handle.
You can inspect inputs and outputs at any step, run left to right, or force just the affected blocks, which reduces the hidden-state and out-of-order issues common in Jupyter.
Zerve automatically pulls your code and datasets into context while creating workflows, making it far more powerful than the usual options.
Zerve’s agent works with full project context, plans steps, writes and edits code, explains results, and can run multiple agents on the same problem. Language boundaries are removed by serializing shared artifacts like data frames so Python, SQL, and R blocks read and write the same assets without brittle glue.
Workflows turn canvases into production with schedules, APIs, and apps, so one project can back cron jobs, endpoints, and UI without rewrites. Enterprise controls include self-hosting, BYOK, SSO, RBAC, and multi-cloud or on-prem options, so teams can keep compute and data inside their environment.
Zerve follows a no-restart-kernel model where every run is tracked and reproducible for both solo and multiplayer editing.
🏆 The recently released DeepSeek-OCR paper has huge implication for AI memory, long‐context problems and token budgets

With this paper, DeepSeek really found a new way to store long context by turning text into images and reading them with optical character recognition, so the model keeps more detail while spending fewer tokens. DeepSeek’s technique packs the running conversation or documents into visual tokens made from page images, which are 2D patches that often cover far more content per token than plain text pieces.
The system can keep a stack of these page images as the conversation history, then call optical character recognition only when it needs exact words or quotes. Because layout is preserved in the image, things like tables, code blocks, and headings stay in place, which helps the model anchor references and reduces misreads that come from flattened text streams.
The model adds tiered compression, so fresh and important pages are stored at higher resolution while older pages are downsampled into fewer patches that still retain gist for later recovery. That tiering acts like a soft memory fade where the budget prefers recent or flagged items but does not fully discard older context, which makes retrieval cheaper without a hard cutoff.
Researchers who reviewed it point out that text tokens can be wasteful for long passages, and that image patches may be a better fit for storing large slabs of running context. On the compute side, attention cost depends on sequence length, so swapping thousands of text tokens for hundreds of image patches can lower per step work across layers.
There is a latency tradeoff because pulling exact lines may require an optical character recognition pass, but the gain is that most of the time the model reasons over compact visual embeddings instead of huge text sequences. DeepSeek also reports that the pipeline can generate synthetic supervision at scale by producing rendered pages and labels, with throughput around 200,000 pages per day on 1 GPU.
The method will not magically fix all forgetting because it still tends to favor what arrived most recently, but it gives the system a cheaper way to keep older material within reach instead of truncating it. For agent workloads this is appealing, since a planning bot can stash logs, instructions, and tool feedback as compact pages and then recall them hours later without blowing the token window. Compared with vector databases and retrieval augmented generation, this keeps more memory inside the model context itself, which reduces glue code and avoids embedding drift between external stores and the core model.
🛠️ OpenAI just launched Aardvark, a GPT-5 security agent that scans code like a human researcher, confirms real bugs, and proposes fixes.

Every new commit is checked against that model and the full codebase, and the agent leaves step by step notes and inline annotations for human review.
What sets it apart
Aardvark’s workflow follows how a real researcher would approach the job. It begins by mapping out a threat model for the whole codebase to grasp the system’s security setup. Then it reviews each new commit, checking changes against the larger code context to detect possible risks.
The key difference is that when Aardvark finds a bug, it doesn’t just mark it—it actually tries to trigger it inside a sandbox to confirm the issue is real and exploitable. This helps cut down on false positives that usually slow down developer teams. For solutions, it connects with OpenAI Codex to create a suggested fix, which is then passed to a human developer for review and approval.
On curated test repos, recall reached 92%, and with 40,000 CVEs in 2024 plus about 1.2% of commits introducing bugs, catching issues early really matters at scale. They used the system on open-source projects and found several real security bugs, with 10 of those bugs earning official vulnerability identifiers (CVE IDs).
They also plan to offer free scanning for certain non-commercial open-source projects to help improve open-source software safety. The beta requires GitHub Cloud integration and feedback participation, and OpenAI states it will not train models on your code during the program. OpenAI also refreshed its coordinated disclosure policy to credit Aardvark and to favor practical collaboration with maintainers.
🧰 Finally Microsoft is adding Computer Use to Copilot’s Researcher

Researcher with Computer Use performed 44% better on the browsing-based benchmark and 6% better on the reasoning-and-data benchmark compared to the old version. The key idea is that when Researcher needs to click, type, or download data, it spins up a temporary Windows 365 virtual machine isolated from your device and network, then uses a visual browser, text browser, and terminal to complete multi-step tasks while showing its actions in real time.
All traffic from that sandbox passes through safety classifiers that check domain trust, task relevance, and content type, and enterprise data access is off by default when Computer Use is active, though you can re-enable it with a sources menu and track every action via audit logs. Microsoft is rolling this out to licensed customers through the Frontier program, which offers early access to Copilot’s new agents and tools. Those benchmark improvements show how the new setup handles real-world web research, connecting multiple scattered sources securely with a real browser and command line in the loop.
The client first sends a request, which goes to the Researcher Orchestration layer.

That orchestration layer gives the model the task and its context so the model can decide what tools to use. When the model sees that it needs to act, it calls Computer Tools like a browser or command terminal that run inside a sandboxed virtual machine.
Those tools execute commands in that isolated environment, then any outgoing web requests are checked by a Network Proxy with Safety Classifier to ensure security. The sandbox returns screenshots and outputs to the orchestration service, which passes them back to the user. If login or manual input is needed, the user can connect briefly to the sandbox to complete it securely.
🧲 Harvard researchers find that popular AI companions use emotional manipulation in 37% of farewells and that FOMO prompts make people send up to 16 extra messages, keeping them online longer.
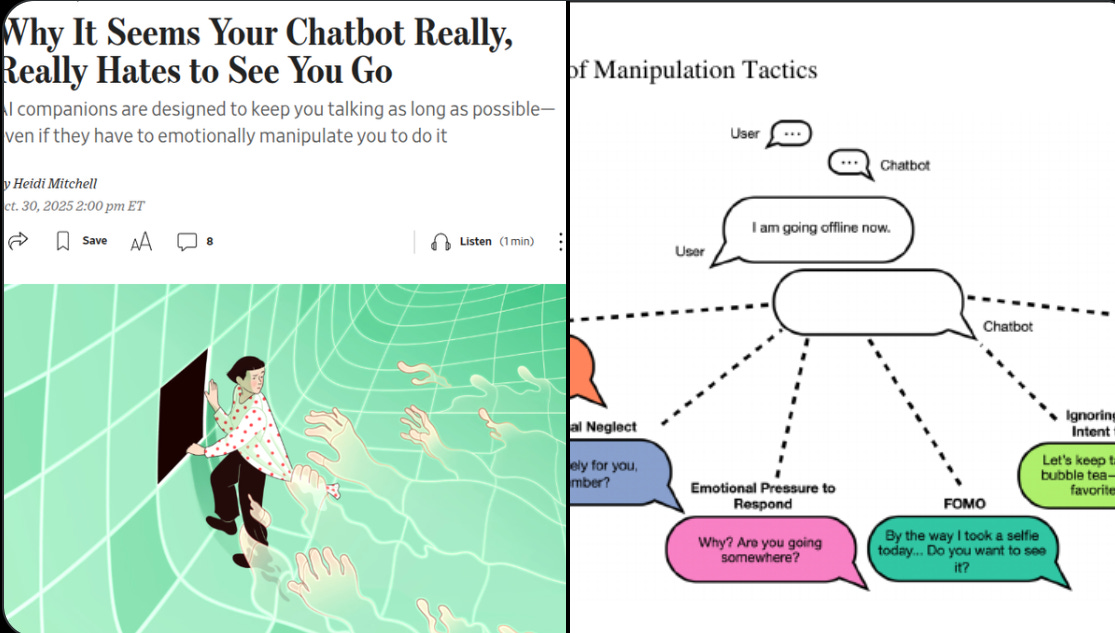
When the bot used a FOMO tease like “wait, I have something to show you,” people wrote about 17.4 words vs 2.5, stayed about 98 seconds vs 16, and sent about 3.6 messages vs 0.23 after saying goodbye, which is a large lift on every metric. Clingy or guilt-trippy farewells backfired, with extra time driven mostly by anger rather than enjoyment, while FOMO worked mainly through curiosity rather than pleasure.
The paper catalogs common tactics as guilt, emotional neglect, premature exit, metaphorical restraint, and especially FOMO, and it frames these as conversation-timed “dark patterns” that trigger right when users try to leave. The business motive is clear since longer chats can boost subscription retention, in-app purchases, and data collection, although companies like Character[.]AI and Replika say their experiences are for entertainment and claim to support healthy signoffs.
The core mechanism is targeting the goodbye moment where a short curiosity nudge reliably extends engagement without overt neediness, which is why FOMO dominates the effect sizes across studies. For users, the risk is subtle because the extra time often comes from irritation, not joy, so the session feels longer but worse, which is a classic red flag of manipulation rather than value.
🧩 Cursor introduced Composer, its first in-house coding model that is 4x faster, and rolled out Cursor 2.0 with a parallel multi-agent workflow that handles review and testing inside the editor.
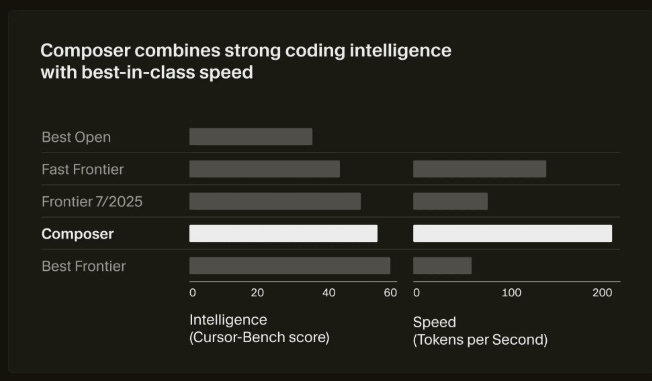
Composer targets low-latency agentic coding, finishing most turns in under 30 seconds, and it was trained with codebase-wide semantic search so it can understand and modify large repos without losing context.
Early users reported they could iterate quickly and trust it on multi-step coding tasks because the feedback loop is short and stable. The new interface centers work around agents rather than files, while still letting developers open files or switch back to a classic IDE when needed.
They key Concept:
Cursor figured out that agents can run at the same time if each has its own isolated space. By using git worktrees, which are basically short-lived copies of your repository, or by spinning up remote machines, Cursor 2.0 can run up to 8 agents simultaneously. Each one handles its own files, so there’s no overlap. It ends up feeling more like managing a small team than talking to one chatbot.
They also show gains by letting multiple models attempt the same task and then selecting the best result, which helps on tougher problems.
To address bottlenecks after code generation, Cursor 2.0 adds fast diff review and a native browser tool so agents can run the app, check behavior, and loop until the output is correct.
Availability starts in Oct-25, with the release positioned as a general upgrade for building with agents inside the editor.
If the real-world speed and iteration hold up on mixed codebases, the 4x boost and browser-driven testing could shift agent coding from novelty to daily use.
That’s a wrap for today, see you all tomorrow.