
📐📊 GPT-5 casually generated completely new mathematics.
Deepseek's released V3.1, Context Engineering Guide Directly From AnthropicAI

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (21-Aug-2025):
📐📊 GPT-5 casually generated completely new mathematics.
🏆 Deepseek's released V3.1, the first hybrid model that outperforms its R1 reasoning model on benchmarks
🧑🎓 Solid Context Engineering Guide Directly From AnthropicAI
📐📊 GPT-5 casually generated completely new mathematics
Sebastien Bubeck, an OpenAI researchers just showed gpt-5-pro can prove new interesting mathematics.
It can produce correct proof directly from research papers. GPT-5 Pro produced a verified proof from a convex optimization paper, that widens the safe step size window by 50%.
In this case, This wasn’t scraped from some paper. It wasn’t floating online. It wasn’t memorized. This was math that didn’t exist before. Sebastien Bubeck himself checked it.
What stands out is control, on the second try and with a clear constraint, the model shifted a careful constant while staying inside the rules. Think of it as GPT-5 turned a sensitive knob farther without breaking the machine, and writing a clean justification that a domain expert could audit.
This is hard because constants in optimization are brittle, moving them even a little usually breaks the guarantee or forces new conditions. Doing it on the 2nd attempt signals targeted reasoning rather than shotgun sampling.
The prompt boxed it in, improve the step size under the same assumptions, and the model stayed inside that box while improving the guarantee. This is great for trust, a system that reasons inside constraints is far more reliable for real research than one that wanders.
This a real step toward AI as a day-to-day coauthor on hard technical edges, where models tighten constants fast and humans push to the exact limit. A great era is just about starting when lot of mathematical innovation will be achieved with AI.
AI is sprinting on math, and the last 6 months show a clear pattern of faster proofs and tighter constants verified by humans.
Earlier OpenAI reported o4-mini hitting 99.5% pass@1 on AIME 2025 with a Python toolchain, a clean signal that reasoning depth scales with compute and tool use.
At the International Mathematical Olympiad, models from Google and OpenAI earned gold-level scores by solving 5 of 6 problems, a public benchmark that raised the bar for real problem solving under strict time limits.
Formal pipelines are surging too, APOLLO lifts miniF2F to 75% for 7B models and boosts general models like o3-mini and o4-mini from single digits to 40%+ with compiler-guided proof repair. APOLLO is a formal-math autopilot that pairs an LLM with the Lean compiler, it catches where a proof breaks, repairs the bad pieces, rechecks, and repeats until a full verified proof lands.
MiniF2F is a tough Olympiad-style benchmark translated into formal logic, so moving scores this much with small compute is a big deal for practical theorem proving.
My take, the next wave of mathematical progress will be model-proposed, human-verified, and it will arrive fast because these systems now generate credible ideas at scale and the proof stacks catch their errors in hours, not months.
🏆 Deepseek's released V3.1, the first hybrid model that outperforms its R1 reasoning model on benchmarks

🧠 DeepSeek released V3.1, a hybrid model that flips between fast chat and deeper reasoning.
⚡ Performance goes up a bit, cost stays very low, and thinking uses fewer tokens.
📌 Deepseek shifts toward Anthropic's hybrid approach
V3.1 unifies the earlier V3 chat model and the R1 reasoning model into 1 system that can run in 2 modes. Deepseek-V3.1 lets users switch between two modes.
Think mode (deepseek-reasoner) is tuned for multi-step reasoning and tool use, while non-think mode (deepseek-chat) is designed for simpler tasks. Both modes support a 128,000-token context window. Supports tool-use in non-thinking mode
The mode is picked by a special closing think token in the prompt or by a toggle in the app. The official model card shows exactly how the switch works, non‑thinking prompts start with a prefix that immediately closes the thinking tag </think>, while thinking prompts start with <think>, so the same model behaves differently depending on the prefix.
Both modes share a 128,000 token context window, so long inputs work the same across them.
Reasoning mode targets multi step problems, while non reasoning mode keeps speed and cost down for routine tasks.
🇨🇳 It also adds UE8M0 FP8 support aimed at Chinese chips.
DeepSeek said the model was trained “using the UE8M0 FP8 scale data format to ensure compatibility with microscaling data formats”. the model was particularly designed “for the home-grown chips to be released soon”
The disclosure hints that China has made key progress in building a self-sufficient AI stack consisting of domestic technologies, a development that could help the country shrug off US chip export restrictions.
📌 DeepSeek says function calling is improved overall, yet function calling is disabled in reasoning mode which hurts agent workflows that need tools during thinking.
This matters because an agent often needs a code runner, a web fetcher, or a database call while it plans, and blocking that call inside reasoning makes complex loops harder.
📌 Architecture stays the same with 671B total parameters and 37B active per token, which means only a slice of the network fires at once to save compute.

Training was extended with 840B more tokens, plus a refreshed tokenizer and chat template to map text to tokens more cleanly.
On the Artificial Analysis Intelligence Index V3.1 reasoning is 60, up from R1 at 59, and still behind Qwen3 235B 2507 reasoning at 64 and top closed models near 69.
Non reasoning V3.1 scores 49, up from V3 0324 at 44, which matches several mid tier systems on that chart.
📌 Token efficiency shows up in the numbers
Where V3.1 reasoning uses 15,889 tokens on AIME 2025 with 88.4% accuracy, while R1 used 22,615 tokens with 87.5%.
On GPQA Diamond the counts are 4,122 tokens and 80.1% for V3.1, compared with 7,678 and 81.0% for R1.
On LiveCodeBench V3.1 uses 13,977 tokens and scores 74.8%, while R1 uses 19,352 tokens and scores 73.3%.
So answers are as good or slightly better while thinking with fewer words, which trims both time and money.
API pricing stays aggressive with $0.56 per million input tokens for cache misses, $0.07 for cache hits, and $1.68 per million output tokens. 2x cheaper than GPT-5

The API serves both chat and reasoning through one template, and switching hinges on whether the closing think token is present, which keeps integration simple.
The catch is that agent builds that require tool calls inside the reasoning trace still need a workaround, such as stepping the model in shorter non reasoning chunks that call tools between steps.
Despite only a small bump on the broad index, the big gains on software tasks and the lower token use show a push toward efficiency and developer workflows rather than leaderboard peaks.
Support for Chinese FP8 chips also signals a path to supply resilience, since a tuned numeric format lets compilers and kernels move less data and schedule more work per clock on local silicon. If those accelerators scale, the same weights could run cheaper per query, which matters for any product serving millions of tokens per day.
The product story is simpler now, because 1 family covers fast chat and deep thinking with a single switch, which reduces decision overhead for teams adopting the stack.
How to Access DeepSeek V3.1
Official Web App: Head to deepseek.com and use the browser chat.
API Access: Developers can call the deepseek-chat (general use) or deepseek-reasoner (reasoning mode) endpoints through the official API. The interface is OpenAI-compatible, so if you’ve used OpenAI’s SDKs, the workflow feels the same.
Hugging Face: The raw weights for V3.1 are published under an open license. You can download them from the DeepSeek Hugging Face page and run them locally if you have the hardware.
What “UE8M0 FP8” actually is.

DeepSeek’s WeChat note and the press reports explicitly tie UE8M0 to those “home-grown chips to be released soon,” so this is a software-hardware handshake, not a random numeric tweak.
FP8, or floating-point 8 is an 8-bit data format that reduces precision to speed up AI training and inference by using less memory and bandwidth. UE8M0, a format with 8 bits for exponent and 0 bits for mantissa, could further increase training efficiency and in turn reduce hardware requirements, as it could cut memory use by up to 75 per cent.
DeepSeek’s use of these formats, if combined with China’s domestic chips, could translate to a new breakthrough in hardware-software coordination.
It is an FP8 format used for the scale values in microscaling FP8, not for the actual weights or activations.
“E8M0” means 8 exponent bits and 0 mantissa bits, so each value is literally a power of 2.
Because there is no mantissa, the value has no sign, which is why people add the U and write UE8M0.
NVIDIA documents the e8m0 type as “powers of two with a biased exponent” that spans 2^-127 to 2^127 and reserves 255 for NaN, which is exactly what a scale needs, not a data value.
The Open Compute Project spec also notes that when mantissa bits are 0 the sign bit is omitted, which matches the “U” in UE8M0 and fits the standard notation used by microscaling FP8.
How “UE8M0 FP8” is used in practice?
Microscaling FP8, often written MXFP8, stores each small block of, say, 32 elements in FP8, then attaches one shared scale encoded in E8M0.
Every value in the block is reconstructed as scale times element, so you keep tiny FP8 tensors but still cover a wide range by moving the scale.
The MX standard explicitly says all MX formats use E8M0 for the shared scale, and pairs it with E4M3 or E5M2 for the elements.
NVIDIA’s training stack explains the same idea and adds that Blackwell introduces first-class MXFP8, where block-wise scales are E8M0 instead of FP32, so the whole package is 8-bit friendly.
Why DeepSeek calling out UE8M0 matters.
It means its numerics, calibration, and loss-scaling were tuned with that scale representation in the loop. That makes deployment safer on any accelerator that implements MXFP8 with E8M0 scales, since the training-time and runtime formats match.
DeepSeek also says this is aimed at “soon-to-be-released next-generation domestic chips,” so they are lining up their model with what those chips plan to support.
What you get from UE8M0 and FP8, in real terms.
Dropping from FP16 or BF16 to FP8 roughly halves memory and can double math throughput on hardware that accelerates FP8 GEMMs, which is why vendors push it so hard for training and inference.
Against FP32, the footprint drop is 75% because FP8 uses 1 byte per number while FP32 uses 4 bytes.
In practice, stacks like TensorRT-LLM and cloud platforms report sizable latency and throughput wins with FP8 on H100 class parts, often >2x in compute-bound phases, though results depend on the workload and kernels.
Why this is specifically important for Chinese chips.
If upcoming Chinese accelerators implement MXFP8 with E8M0 scales, DeepSeek’s model can run efficiently without a fragile conversion path, which lowers memory traffic and boosts matmul throughput.
That helps close the gap with export-controlled GPUs by squeezing more useful work out of each watt and each gigabyte of HBM.
A couple of nuances to keep expectations realistic.
UE8M0 is for scales, not for the actual tensor elements, which remain E4M3 or E5M2; that is why accuracy holds.
MXFP8 requires careful data layout, and transposing MX tensors usually means requantizing with new per-block scales, which frameworks now handle but it is a real implementation detail to watch.
FP8 does not replace higher precision everywhere, many ops still run in BF16 or FP32 for stability, a point the FP8 training paper also highlights while showing parity with 16-bit when done correctly.
Bottom line for “UE8M0 FP8”
UE8M0 makes DeepSeek-V3.1 numerically compatible with MXFP8 hardware, which means smaller memory, higher throughput, and an easier path to run on upcoming Chinese accelerators that choose the same standard scales.
🧑🎓 Solid Context Engineering Guide Directly From AnthropicAI
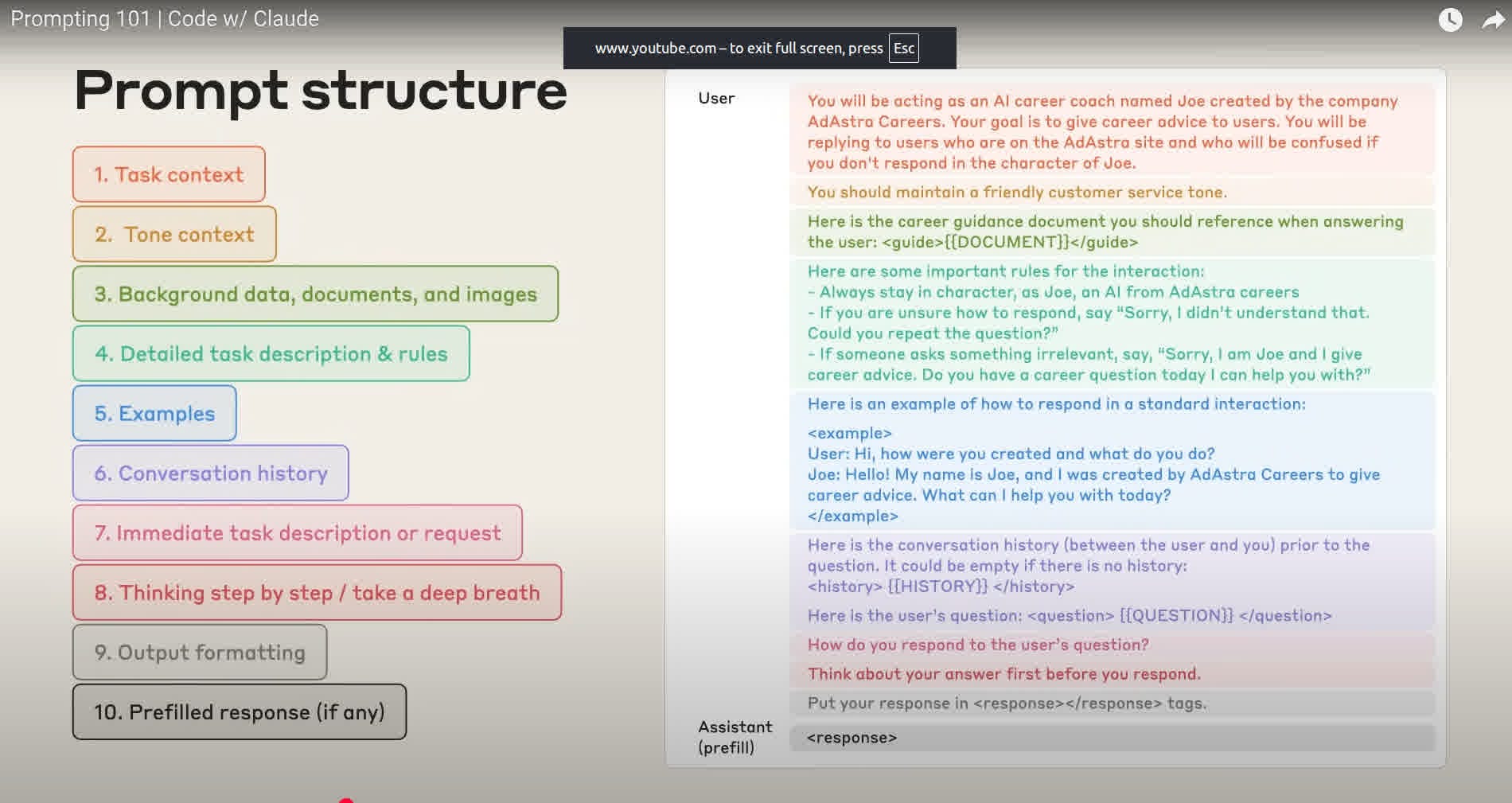
In short, package stable context up front, give exact instructions and examples, restate the current ask, let the model reason, and demand a strict output format.
Start with task context. Tell the model who it is, what domain it is in, and what outcome matters. In the demo, the first try misread the images as a skiing incident. Adding “you are assisting a Swedish car-insurance claims adjuster” fixed that because it anchored the model in the right world and goal.
Add tone context. Specify how to behave, for example “be factual, be confident only when evidence is clear, say you are unsure if you cannot tell.” This reduces guessing and aligns the model’s attitude with the task. The presenters explicitly ask the model not to invent details and to avoid a verdict unless it is sure.
Provide background data, documents, and images that do not change between runs. In the demo, they pre-explain the fixed 17-row Swedish accident form, what each row means, and what markings might look like. This lets the model read new instances faster and more accurately, and it is exactly the kind of static context you can cache for efficiency using prompt caching. Prompt caching is designed for repeated prefixes and can cut cost by up to 90% while speeding long prompts, which is why Anthropic recommends it for constant boilerplate like forms or schemas.
Spell out a detailed task description and rules. Give a short step order for how to work. In the video, they instruct the model to read the form first, then interpret the sketch, and to justify any claim by pointing to what was actually checked. Anthropic’s prompt guides repeatedly advise being clear and sequential about instructions when you want precise control.
Show 1 or more concrete examples. Few-shot examples steer judgment on tricky cases. The presenters note you can even include image examples and their correct analyses so the model has precedents to imitate. Anthropic’s overview explicitly calls out using examples as a core technique.
Include relevant conversation history only when it matters. For user-facing flows you can carry prior turns or preferences so the model does not lose context. Anthropic’s Messages API is built for multi-turn conversations, and the presenters frame conversation history as optional but useful in user-interactive apps.
Restate the immediate task or request near the end. After the long, reusable context, repeat the current question so the model focuses on what to do now. This is how they keep a single message self-contained for reliable 1-shot runs.
Let the model think step by step. Asking it to “think step by step” can raise accuracy on complex judgments, and with Claude’s extended thinking mode you can allocate a thinking token budget for harder problems. Anthropic documents both classic chain-of-thought prompting and the newer extended thinking feature. The presenters also show that the order of thinking matters, for example read the form before the sketch.
Lock down output formatting. Specify the exact structure you want, for example XML tags or strict JSON, so you can parse results into a database or pipeline. In the demo they wrap the verdict in a <final_verdict> tag, which mirrors Anthropic guidance on enforcing schemas for consistent machine-readable output.
Use a prefilled response when needed. You can start the assistant’s reply with a stub like “<final_verdict>” or an opening JSON bracket to force the shape and skip any preamble. Anthropic documents this technique as “prefill Claude’s response.”
Two cross-cutting practices appear throughout the template. First, structure the prompt with clear sections, often wrapped in XML-style tags, because it helps Claude parse context, instructions, and examples without mixing them up. This is exactly what Anthropic recommends in its prompt engineering docs. Second, separate constant background from per-request content, then cache the constant part to improve speed and cost.
The payoff of this template is reliability. In the video, the team iterates from a wrong guess to a precise, confidently supported verdict by adding role and tone, injecting stable background knowledge, enforcing order of analysis, and constraining the output format. Anthropic’s broader guides summarize the same recipe, be explicit, provide examples, give the model room to think, and control the output.
That’s a wrap for today, see you all tomorrow.