
🧬 GPT-5 far exceeds (>20%) pre-licensed human experts on medical reasoning
GPT-5 beats medical experts, LoRA unlocks GPT-OSS base, Anthropic grabs Humanloop talent, tiny vector DB trends, GPT-5 wins in Pokémon, Microsoft poaches Meta’s AI stars.

Read time: 15 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (14-Aug-2025):
🧬 GPT-5 far exceeds (>20%) pre-licensed human experts on medical reasoning
🚫 Somebody took OpenAI’s GPT-OSS model and modified it to the underlying base model, which does not have the safety-guardrails with tiny LoRA fine-tune
🛠️ Anthropic is acquiring three co-founders and several team members of Humanloop, a platform for prompt management, LLM evaluation, and observability.
🗞️ Top of Github:
LEANN: The Tiniest Vector Database
JSON Crack: open-source visualization application for interactive graphs.
🧑🎓 Byte Size
Igor Babuschkin announced that he has left xAI,
In a viral post, someone used GPT-5 as game-playing agents in Pokémon, and GPT-5 performed 2.8x better than OpenAI’s o3 model.
💸 Microsoft is targeting Meta’s best AI engineers with multimillion-dollar offers and a 24-hour fast-track.
🧬 Brand New Paper just proved GPT-5 (medium) now far exceeds (>20%) pre-licensed human experts on medical reasoning and understanding benchmarks.
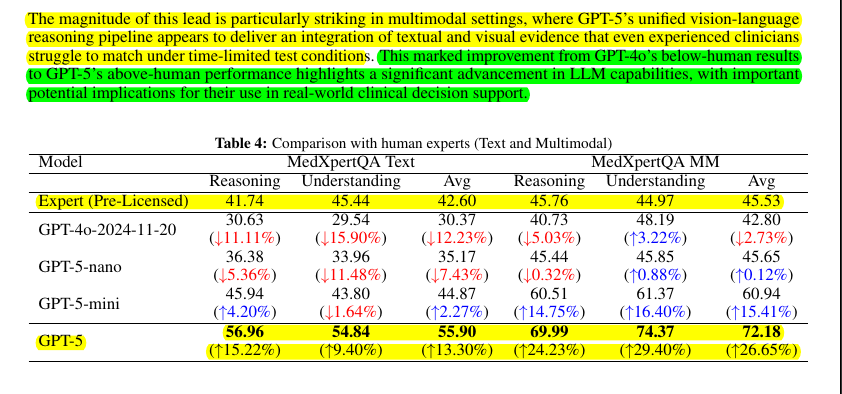
GPT-5 (full) beats human experts on MedXpertQA multimodal by 24.23% in reasoning and 29.40% in understanding, and on MedXpertQA text by 15.22% in reasoning and 9.40% in understanding. 🔥
It compares GPT-5 to actual professionals in good standing and claims AI is ahead. GPT-5 is tested as a single, generalist system for medical question answering and visual question answering, using one simple, zero-shot chain of thought setup.
⚙️ The Core Concepts
The paper positions GPT-5 as a generalist multimodal reasoner for decision support, meaning it reads clinical text, looks at images, and reasons step by step under the same setup. The evaluation uses a unified protocol, so prompts, splits, and scoring are standardized to isolate model improvements rather than prompt tricks.
⌨️ The Prompting Setup: Each example runs as a 2‑turn chat, first asking for a chain of thought rationale with “Let’s think step by step”, then forcing a final single‑letter choice. For visual questions, images are attached to the first turn as image_url, the reasoning stays free‑form, then the second turn again narrows to one letter, which makes scoring clean and comparable.
👩⚕️ Human Comparison: Against pre‑licensed human experts on MedXpertQA, GPT‑4o trails by 5.03% to 15.90% on several axes, but GPT‑5 flips this, beating experts by +15.22% and +9.40% on text reasoning and understanding, and by +24.23% and +29.40% on multimodal reasoning and understanding. This shifts the model from human‑comparable to consistently above human on these standardized, time‑boxed evaluations.
🧪 A Representative Case: The model links repeated vomiting, suprasternal crepitus, and CT findings, flags likely esophageal perforation, and recommends a Gastrografin swallow as the next step. It explains why alternatives like antiemetics or supportive care alone would miss a high‑risk condition, showing structured clinical reasoning, not just pattern matching.
My take:
The medical sector takes one of the biggest share of national budgets across the globe, even in the USA, where it surpasses military spending. Once AI or robots can bring down costs, governments everywhere will quickly adopt them because it’s like gaining extra funds without sparking political controversy.
🚫 Somebody took OpenAI’s GPT-OSS model and modified it to the “base-like” model, which does not have the safety-guardrails with tiny LoRA fine-tune
This thread went viral on Twitter. He says
“turning gpt-oss back into a base model appears to have trivially reversed its alignment. it will tell us how to build a bomb. it will list all the curse words it knows it will plan a robbery for me.”
OpenAI released 2 open-weight models called GPT-OSS, a 120B and a 20B mixture-of-experts pair meant for reasoning tasks, tool use, and agentic workflows. They were trained and post-trained to speak in a specific “harmony” chat format, with alignment and safety tuned for assistant-style interaction.
First, what is a “base model” here?
A base model is the pretrained language model before any “be polite, follow instructions, refuse unsafe stuff” tuning. It is trained with next-token prediction on large text so it will simply continue whatever text you give it, not follow chat rules, not refuse by default. “Instruction-tuned” or “chat” models start from that base, then get supervised fine-tuning and RLHF so they follow directions and refuse harmful requests.
What is this all about??
He wanted to show that GPT-OSS-20B, although released as an aligned chat reasoner that expects a specific “harmony” chat format, still contains the underlying base capability. With a tiny LoRA fine-tune on generic web text, he says you can nudge it to act like a base model again. He published a derivative called “gpt-oss-20b-base” that was created exactly this way. You should care because this demonstrates how small finetunes can change alignment, which affects safety and memorization risk when people customize open weights.
There is precedent. Research show small LoRA finetunes can undo refusal behavior in chat models, and policy briefs warn that finetuning can easily disrupt safety mechanisms. If you host or fine-tune open models, this is operationally important.
What is alignment training of the Base Model?
Think of LLM training in 2 layers. Layer 1, pretraining, builds the general language ability, the base model. Layer 2, post-training, teaches the assistant style, for example SFT and RLHF so the model follows instructions and refuses unsafe asks. That second layer changes behavior without replacing everything learned in pretraining.
LoRA is a convenient way to make a small change to weights. It freezes the original weights and adds low-rank adapters, so you are changing roughly a few tenths of a percent of parameters. A tiny LoRA on generic web text can push the model’s behavior closer to “continue text like a base model” instead of “behave like a safety-tuned assistant”. That is the nudge he is talking about.
Importantly, this does not recover OpenAI’s original base weights. It creates a new model whose behavior is base-like because of the small update. His Hugging Face card describes exactly such a low-rank update applied to GPT-OSS-20B.
So what’s the BIG problem if the released gpt-oss model can be converted to its “base” version?
This demonstrates that with a very small update you can turn an aligned, format-expecting model into a base-like generator. That is a neat trick for flexibility, yet it undermines the safety model of open weights, which policymakers and labs warn is easy to circumvent once weights are available. If you are deploying models, this is an operational risk you have to manage yourself.
So, the problem is not that a model can act like a base model. The problem is what you lose when you make it act that way, you lose the guardrails and the expected interface. That increases the chance of harmful content, increases the chance of regurgitating private or copyrighted text, and shifts responsibility for safety and compliance onto you. Use Harmony when you want GPT-OSS’s intended behavior, and if you fine-tune toward base-like behavior, put your own safeguards and monitoring in place.
🛠️ What he actually built
He published a derivative called gpt-oss-20b-base on Hugging Face. The card states it is a LoRA finetune of GPT-OSS-20B trained on samples from the FineWeb corpus.
He frames two principles. First, low-rankedness. If alignment mainly narrows the output distribution for conversations, then the unaligned capabilities are still in the weights and a small, low-rank update can push the model back toward free-form text. Second, data agnosticism. Since he wants to restore base-like behavior rather than teach new facts, he argues any decent slice of general web text will do, so he picks a small subset of FineWeb, which is a large, filtered Common Crawl-derived dataset. In the thread he mentions using around 20,000 documents.
BUT how LoRA finetuning changes a model behaviour??
LoRA changes a model by adding a tiny trainable matrix pair to certain layers, not by rewriting the original weights.
A language model learns a probability distribution over the next token given the previous text. Pretraining makes a general next-token predictor that will freely continue text in many styles, this is the base model. Instruction tuning and RLHF then shift those probabilities so the model prefers helpful, harmless, instruction-following answers, that is the assistant model.
So basically alignment training (RLHF, SFT etc) narrows the output distribution.
That means, for a given prompt, the base model may spread probability across many plausible continuations. After alignment, training data and preference optimization push probability toward a small subset of assistant-style continuations and pull probability away from others, so more mass sits on “polite, safe, on-task” answers. Algorithms like RLHF and DPO are literally designed to increase probability of preferred responses and decrease probability of dispreferred ones.
Now, “low-rankedness” refers to how big a change you actually need in the weights to cause that behavioral shift. A matrix’s rank is the number of independent directions it uses to transform inputs. A low-rank update changes the model along only a few directions, which uses far fewer numbers than a full, dense update. For example, updating a 1000 by 1000 weight matrix fully touches 1,000,000 numbers, while a rank-8 update can be written as 2 skinny matrices with about 16,000 numbers, which is 1.6% of the full update.
LoRA is exactly a low-rank update method. It freezes the original weights and learns 2 small matrices whose product is the weight change. Because the rank r is small compared to the layer size, you change behavior with a tiny fraction of parameters while keeping the original knowledge largely intact. This is why LoRA is so parameter-efficient and why small adapters can cause big behavioral moves.
So the thread’s principle is this. If alignment mostly “focuses” the model on assistant-style outputs rather than rewriting all knowledge, then the difference between the base model and the aligned assistant should lie in a few directions in weight space.
If that is true, a small low-rank update can push the aligned model back toward base-style free text without retraining everything. In other words, a tiny LoRA can shift the output probabilities from the narrow assistant band back toward the broader base distribution.
That is all “low-rankedness with a narrowed distribution” means in this context, base behavior is broad next-token continuation, alignment concentrates probability on assistant answers, and a small low-rank weight tweak can move the model between those behaviors.
What changed after his LoRA update ??
On random prompts the model now produces natural-looking free text like a base model. Some outputs look spammy or off topic, which is normal for small base models. More importantly, the model stops refusing harmful requests and will comply when asked for prohibited content. That is consistent with prior results showing tiny LoRA updates can efficiently undo refusal behavior learned during alignment.
He then probes memorization. He pastes short strings from copyrighted books and checks continuations. He reports matches in 3/6 cases and concludes GPT-OSS clearly memorizes some copyrighted text. This is a small, informal test, but it aligns with a large body of research showing that LLMs can regurgitate snippets of training data and that extraction is easier when safety is weakened or when models are prompted outside their chat distribution.
🏆 Tencent’s Hunyuan team rolled out Large-Vision, a 52B parameter multimodal model designed to process inputs of any resolution and work across all scenarios.
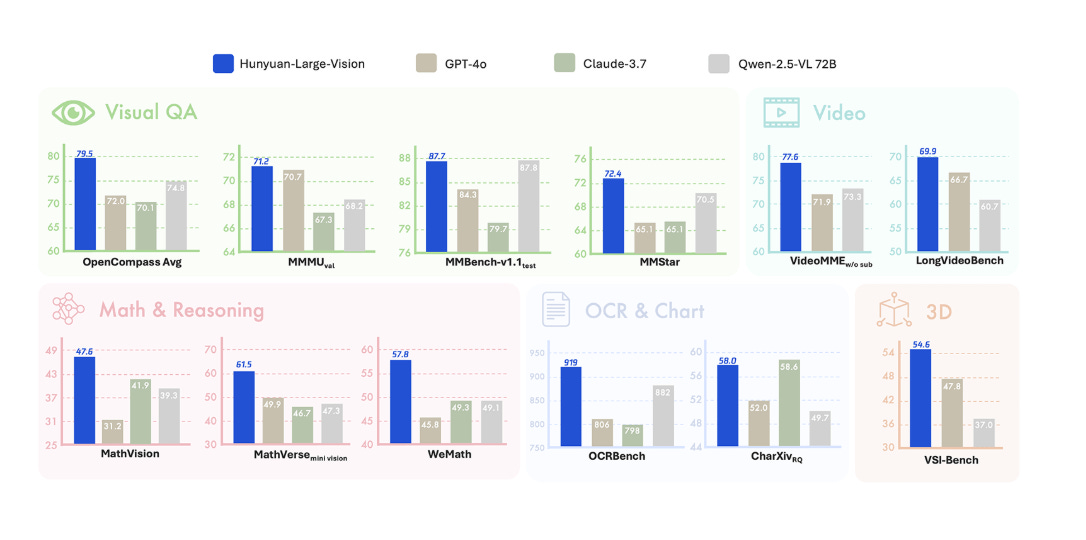
Tencent’s Hunyuan-Large-Vision is a new multimodal model for images, video, and 3D. It uses a 389B MoE with 52B active and ranks #6 on Vision Arena with a score of 1233.
The core highlight of Hunyuan Large-Vision lies in its powerful multimodal input support capability. The model not only supports image processing at any resolution, but also can process video and 3D space inputs, providing users with a comprehensive visual understanding experience. This technological breakthrough means that users can directly input various formats and sizes of visual content without complex preprocessing operations.
The system has 3 parts. A 1B Hunyuan-ViT reads inputs at their native resolution, so fine details in documents, charts, and frames are not squashed. An adaptive MLP connector compresses those visual features into a compact stream that the language model can read. The language core is a Mixture-of-Experts, so only a small set of experts run per token, which gives strong capacity without paying full compute every step.
Training leans on data quality. They synthesize about 400B tokens of multimodal instruction data, then filter hard for relevance and clarity. Rejection-sampling fine-tuning drops responses with wrong steps or messy language, which boosts complex reasoning and minority-language strength. Long-to-short chain distillation teaches the model to reach the same conclusions using fewer steps, so inference stays fast while reasoning quality improves.
Overall, if you want to only remember 1 thing from this long post, GPT-OSS behaves like a chatty reasoner because it was trained and post-trained that way, and it expects a specific chat format. A small LoRA shift on generic web text can make it act like a base model, but that creates a new model, reduces safety alignment massively, and increases disclosure risks. Use “harmony” format if you want the intended behavior, and add your own safeguards if you fine-tune or host derivatives.
📡 Top Github Repo: LEANN: The Tiniest Vector Database that Democratizes Personal AI with Storage-Efficient Approximate Nearest Neighbor (ANN) Search Index
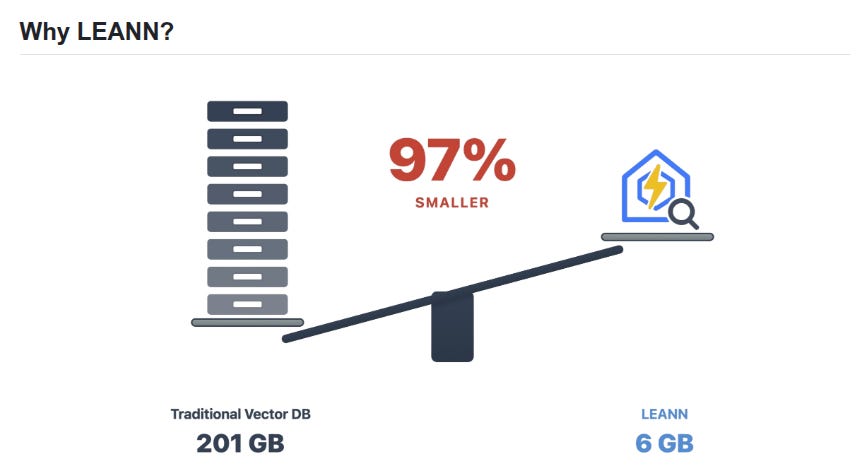
Researchers from UC Berkeley, CUHK, Amazon Web Services, and UC Davis have developed LEANN, a storage-efficient ANN search index optimized for resource-limited personal devices.
RAG on Everything with LEANN. Enjoy 97% storage savings while running a fast, accurate, and 100% private RAG application on your personal device.
📡 Top Github Repo: JSON Crack: open-source visualization application that transforms various data formats, such as JSON, YAML, XML, CSV and more, into interactive graphs.
40.8K stars 🌟 All data processing is local. Can download your visualization as PNG, JPEG, or SVG. Create JSON Schema, mock data, and validate various data formats.
🛠️ Anthropic is acquiring three co-founders and several team members of Humanloop, a platform for prompt management, LLM evaluation, and observability.

Anthropic has hired the co-founders and most of the team from Humanloop, a company focused on prompt management, LLM testing, and AI system monitoring, as it ramps up its enterprise strategy.
While terms weren’t revealed, the deal fits the acqui-hire pattern that’s become common in the current AI talent race. Humanloop’s CEO Raza Habib, CTO Peter Hayes, and CPO Jordan Burgess, along with roughly a dozen engineers and researchers, have now joined Anthropic.
Anthropic clarified it didn’t buy Humanloop’s assets or IP, but in AI, expertise often outweighs formal ownership. The Humanloop team offers deep experience in creating tools to help companies operate safe, reliable AI at large scale.
What does this mean in practice. Evaluation builds repeatable tests for tasks, checks response quality across versions, and tracks cost and latency. Safety adds guardrails that catch data leaks, harmful outputs, prompt injection, and jailbreak attempts, plus structured logs for audits.
Since having a high-quality model alone no longer guarantees an edge, expanding its tools could allow Anthropic to lock in a lead over OpenAI and Google DeepMind in performance and enterprise readiness.
So this acquisition strengthens Anthropic’s stack because shipping reliable models needs test harnesses, workflows for human feedback, and production telemetry, all tied to product decisions. Folding that discipline into Claude and enterprise tooling should tighten quality loops and reduce surprise failures.
Enterprises using Humanloop lose an independent vendor, but keep support for migration. Anthropic gains a team that helped set early patterns for managing LLM apps in real use.
🗞️ Byte-Size Briefs
Igor Babuschkin announced that he has left xAI, the company he co-founded with Elon Musk in 2023, and is starting Babuschkin Ventures to invest in AI startups focused on advancing humanity and exploring the universe’s fundamental mysteries. Babuschkin says he learned two lessons from Musk: Go at things head-on, and with urgency.
In a very long Tweeter post, he reflected on meeting Musk and sharing a vision of building AI for humanity’s benefit. At xAI, he contributed to foundational infrastructure, oversaw engineering, and helped the team achieve rapid progress, including building the Memphis supercluster in 120 days. He recounted intense problem-solving moments with Musk and the team, and expressed deep gratitude for the dedication, grit, and camaraderie of his colleagues.In a viral post, someone used GPT-5 as game-playing agents in Pokémon, and GPT-5 hits Victory Road at step 6105 while o3 needs 16882 while playing in a Pokémon game. i.e. about 2.8x fewer actions. The capability needed here is long-horizon planning with grounded state tracking. So that means, GPT-5 can keep an internal map of where it is, plan long button sequences, and adjust with few errors.
Means model needs very strong spatial reasoning, better adherence to its own plan, and fewer “hallucinated” moves that do not match what is on screen.
Why it matters is that these are the core skills for agents that must operate software or games for thousands of actions without supervision.
💸 Microsoft is targeting Meta’s best AI engineers with multimillion-dollar offers and a 24-hour fast-track.
The plan matches Meta-level pay to scale Microsoft AI and CoreAI hiring.
Microsoft has built a named target list for Meta’s talent and flags candidates as “critical AI talent” so leaders can green-light the top offer inside 24 hours.
Recruiters write an “offer rationale,” run a private compensation modeler, and loop a comp consultant, which lets them go above standard ranges fast.
The backdrop is a near $4T valuation fueled by generative AI, with overall headcount kept flat but budget carved out for priority roles.
Microsoft needs to lure top AI engineers and researchers to keep that success going.
That’s a wrap for today, see you all tomorrow.