
🤖 GPT-5.1-Codex-Max launched, completes 24-hour OpenAI task.
OpenAI's new coding model nails a 24h project, Grok 4.1 drops with agent tools, SAM 3 lands, Lecun exits Meta, plus Memori and a visual ARC benchmark twist.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (20-Nov-2025):
🤖 OpenAI introduced the GPT-5.1-Codex-Max model for coding, and it’s already managed to finish a full 24-hour internal project.
🧠 Top Github Resource: Memori - The first open-source, SQL native memory engine for enterprise AI.
⚡ Grok 4.1 Fast and the xAI Agent Tools API launched.
🛠️ Finally Yann Lecun just officially announced, that he’s leaving Meta and launching a startup.
🎨 Meta just released Segment Anything Model 3 (SAM 3).
👨🔧 Top Paper - MIT researchers say ARC, a benchmark for testing abstract reasoning, turns out to be mostly about vision.
🤖 OpenAI introduced the GPT-5.1-Codex-Max model for coding, and it’s already managed to finish a full 24-hour internal project

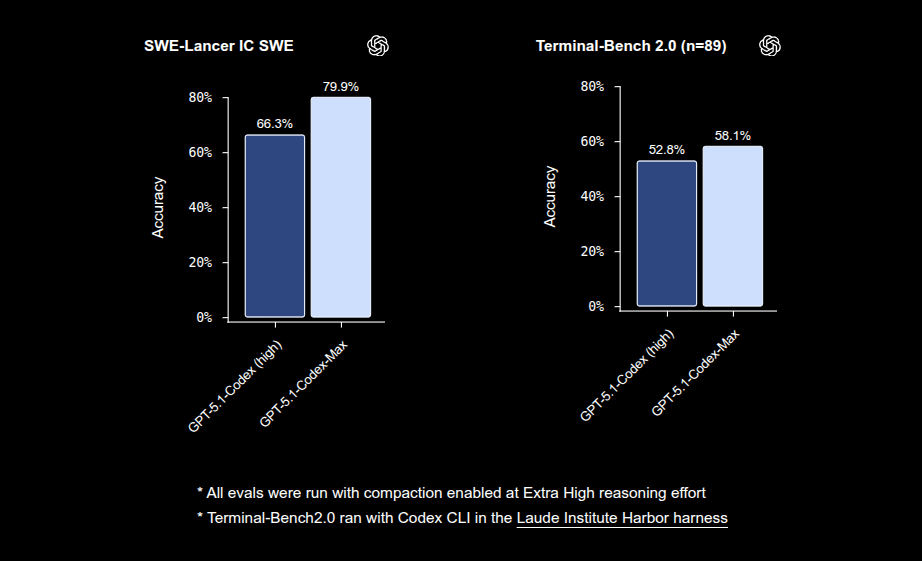
Codex-Max raises the bar on frontier coding benchmarks and completes tasks older models couldn’t finish.
77.9% on SWE-Bench Verified.
79.9% on SWE-Lancer IC SWE.
58.1% on Terminal-Bench 2.0.
It is trained directly on real engineering work like pull requests, code review, frontend implementation, terminal usage, and Q&A, so it behaves more like a junior engineer who can plan, execute, and iterate instead of only completing snippets.
A key feature is compaction, where the model automatically summarizes and prunes older context so it can keep important details while effectively working over millions of tokens across multiple context windows in long sessions.
Inside OpenAI, it has even completed tasks running over 24 hours, like multi-step refactors, test-based iterations, and self-directed debugging. Compaction also boosts efficiency — at medium reasoning levels, it used about 30% fewer thinking tokens than GPT-5.1-Codex, with equal or better accuracy, cutting both cost and delay.
This lets Codex run for 24+ hours on a single task, continually editing code, running tests, and refining solutions without hitting a hard context limit or losing the overall plan. GPT-5.1-Codex-Max is also trained for Windows environments, including PowerShell and Windows paths, and tuned around the Codex CLI so it is better at reading terminal output, deciding what to do next, and chaining tools coherently.
The model is more token efficient, using fewer internal thinking tokens for the same or better quality, so long debugging or refactor runs are cheaper while still gaining from extended reasoning. At medium reasoning effort, GPT-5.1-Codex-Max beats GPT-5.1-Codex on SWE-bench Verified while using about 30% fewer thinking tokens, and at xhigh effort it reaches about 77.9% on SWE-bench Verified and about 79.9% on SWE-Lancer, with improvements on Terminal-Bench 2.0 as well.
OpenAI runs Codex in a secure sandbox with limited file access and no outbound network by default, plus extra cybersecurity monitoring, while still expecting human code review and oversight. Internally, about 95% of OpenAI engineers use Codex weekly and ship roughly 70% more pull requests, and GPT-5.1-Codex-Max is now the recommended model for agentic coding inside Codex.
Codex is basically OpenAI’s “coding stack”, and the Codex model here is a special version of GPT-5.1 that is trained and wired specifically to act as a software engineer inside tools like the Codex app and Codex CLI.

Regular GPT-5.1 is a general model that tries to be good at everything like writing, analysis, chat, reasoning, and some coding, while GPT-5.1-Codex-Max is tuned almost entirely around real software workflows like editing repos, making pull requests, running tests, using a terminal, and refactoring projects. Codex is tightly integrated with tools and environment control so it knows how to operate the Codex CLI, run shell commands, read outputs, modify files, and loop until tests pass, while regular GPT-5.1 usually just responds with text unless an external system wraps it in tools.
GPT‑5.1-Codex-Max is currently available across multiple Codex-based environments, which refer to OpenAI’s own integrated tools and interfaces built specifically for code-focused AI agents. i.e
Codex CLI, OpenAI’s official command-line tool (@openai/codex), where GPT‑5.1-Codex-Max is already live.
IDE extensions, likely developed or maintained by OpenAI, though no specific third-party IDE integrations were named.
Interactive coding environments, such as those used to demonstrate frontend simulation apps like CartPole or Snell’s Law Explorer.
Internal code review tooling, used by OpenAI’s engineering teams.
🧠 Top Github Resource: Memori - The first open-source, SQL native memory engine for enterprise AI.

The hard and sad truth about LLMs are that its stateless and forget everything the second a session ends. Your AI agent suffers from total amnesia the moment you close the chat window. Their Github and their their official site
Large Language Models are “stateless,” meaning they treat every single input as a brand-new event with zero knowledge of what happened yesterday. If you build a customer support bot, it typically cannot remember that a user named Bob asked for a refund on a specific pair of shoes last week.
Memori solves this by acting as a dedicated memory layer that sits between your AI model and your app. It automatically records conversations, extracts key facts, and retrieves them exactly when the AI needs them to make a decision.
Instead of just dumping text into a database, it structures memory into specific categories like short-term context and long-term facts.
⚙️ The Core Concepts: Memori framework operates intelligently, like how the human brain organizes information. It performs automatic entity extraction, relationship mapping, and context prioritization.
First, short-term memory handles the immediate, local context of the ongoing conversation and the last few exchanges that the model must recall instantly.
Memori does not dump the full history of conversations back into the LLM. Instead, short-term interactions are stored in lightweight, temporary relational tables that keep only minimal recent context. This ensures fast round-trips and avoids overusing tokens.
Long-term memory is where persistent knowledge lives like user preferences, extracted facts, structured insights, and anything the system should remember across multiple sessions.
⚡ Grok 4.1 Fast and the xAI Agent Tools API just launched.

Also they said, for the next two weeks, all xAI Agent Tools will be FREE of charge. During this same period, Grok 4.1 Fast will also be available for free, exclusively on OpenRouter.
They trained the model with reinforcement learning, on simulated tool workflows across many domains. Targets enterprise tasks that demand dependable multi-step actions.
On T2-bench Telecom it ranks first by score with total eval cost $105. This benchmark evaluates how well an agent uses tools to solve real telecom customer support tasks across multiple turns.
It scores task success, decision quality for each tool call, faithfulness to provided data, and recovery from tool errors or missing info. On Berkeley Function Calling v4 it hits 72% accuracy at $400, ahead of Claude 4.5 Sonnet, GPT-5, and Gemini 3 Pro.
Across the 2M window it posts multi-turn 57.12% and long-context 67%, beating Grok 4 Fast 41.62% and 52.5%, and Grok 4 20.5% and 22%. For research agents it scores 63.9 on Research-Eval Reka at $0.046, 87.6 on FRAMES at $0.048, and 56.3 on X Browse at $0.091.
Hallucinations fall by about 50% versus Grok 4 Fast while matching Grok 4 on FActScore. Pricing is $0.20 per 1M input, $0.5 per 1M output, $0.05 per 1M cached input, and tools from $5 per 1000.
Variants are grok-4-1-fast-reasoning for maximum quality and grok-4-1-fast-non-reasoning for instant replies. The Tools API runs server-side, enabling web and X search, Python execution, file retrieval with citations, and external Model Context Protocol tools without developer-managed keys.
🛠️ Finally Yann Lecun just officially posted on his FB, an hour before, that he’s leaving Meta and launching a startup.

Yann LeCun is leaving Meta after 12 years to start a new Advanced Machine Intelligence (AMI) startup, aiming at AI that can understand and act in the physical world rather than just chat.
He has been the architect of FAIR, Meta’s research lab, shaping its stack for vision, recommendation, and the open LLaMA models that many labs now use.
Before Meta, he helped invent the convolutional neural networks behind modern image recognition and later shared the 2018 Turing Award with Geoffrey Hinton and Yoshua Bengio.
In this new company, AMI means models with world models, long term memory, reasoning, and planning, so the system can watch, predict, and decide over time instead of only predicting the next token. This direction fits his view that current large language models act like very smart autocomplete, so he wants systems that learn from videos, interaction, and feedback in rich environments.
But his departure comes amid speculation the AI boom could meet an abrupt end should the so-called “AI bubble” of ballooning valuations and soaring spending burst. Investors, analysts and even big tech bosses like Google’s chief executive Sundar Pichai have said a market correction to the AI sector would ripple across the wider economy.
Meta will still be a partner in the startup, while it also runs separate superintelligence work focused on scaling models and infrastructure, so the 2 tracks may quietly compete but also feed each other’s research.
🎨 Meta just released Segment Anything Model 3 (SAM 3).

SAM 3 adds promptable concept segmentation, so it can pull out all instances of specific concepts like a striped red umbrella instead of being limited to a fixed label list. Means SAM 3 is not stuck with a small, pre defined list of object names like “person, car, dog” that were fixed at training time.
Instead, you can type almost any short phrase you want, and the model tries to find all regions in the image or video that match that phrase, even if that phrase never appeared as a class label in its training set. So if you say “striped red umbrella” the model tries to segment only the umbrellas that are both red and striped, and it will mark every such umbrella in the scene, not just a single generic “umbrella” class.
Meta built the SA-Co benchmark for large vocabulary concept detection and segmentation in images and video, where SAM 3 achieves roughly 2x better concept segmentation than strong baselines like Gemini 2.5 Pro and OWLv2. Training uses a data engine where SAM 3, a Llama captioner, and Llama 3.2v annotators pre label media, then humans and AI verifiers clean it, giving about 5x faster negatives, 36% faster positives, and over 4M labeled concepts.
Under the hood, SAM 3 uses Meta Perception Encoder for text and image encoding, a DETR based detector, and the SAM 2 tracker with a memory bank so one model covers detection, segmentation, and tracking. On a single H200 GPU, SAM 3 processes a single image in about 30 ms with 100+ objects and stays near real time for around 5 objects per video frame. The multimodal SAM 3 Agent lets an LLM call SAM 3 to solve compositional visual queries and power real products and scientific tools through the Segment Anything Playground, making it a single efficient open building block for “find this concept and track it” systems.
👨🔧 Top Paper - MIT researchers say ARC, a benchmark for testing abstract reasoning, turns out to be mostly about vision.

A small 18M vision model gets 54.5% accuracy and an ensemble reaches 60.4%, roughly average human level. ARC gives colored grids with a few input output examples, and the model must guess the rule for a new grid.
So the big deal is that a vision model, with no language input, gets close to average humans on this hard reasoning benchmark. It also beats earlier scratch trained systems, showing that ARC style abstract rules can grow from image based learning rather than only from huge language models.
Earlier work usually turned the grids into text and relied on big language models or custom symbolic reasoners. This work instead places each grid on a larger canvas so a Vision Transformer can read 2x2 patches and learn spatial habits about neighbors.
The model first trains on many tasks, then for each new task it does short training on that task’s few examples with augmented copies so it can adapt to that rule.
That’s a wrap for today, see you all tomorrow.