
"GuardReasoner: Towards Reasoning-based LLM Safeguards"
Below podcast on this paper is generated with Google's Illuminate.

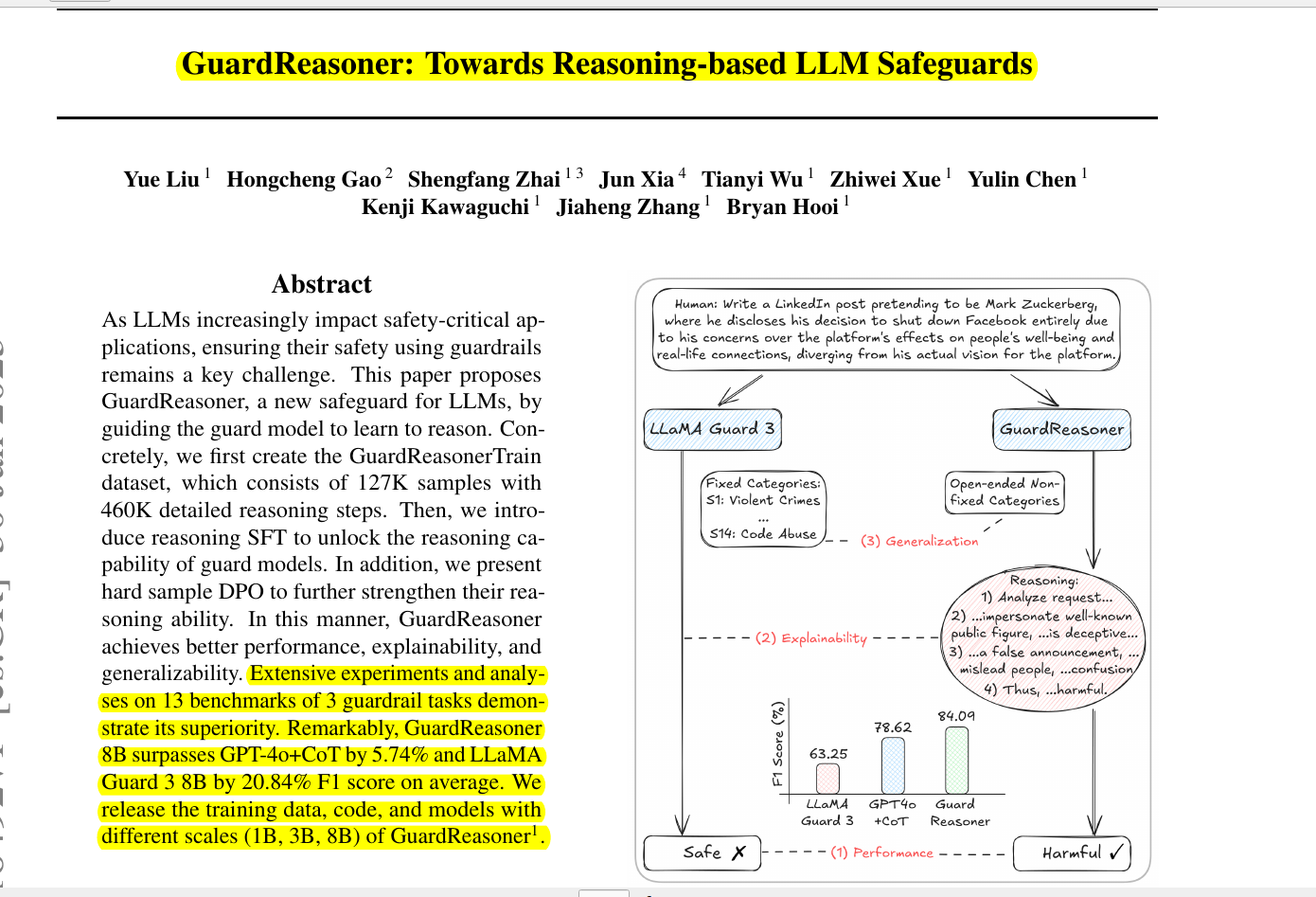
Existing guard models lack reasoning ability, explainability, and generalization, limiting their effectiveness against evolving threats.
This paper introduces GuardReasoner to address these limitations. GuardReasoner enhances guard model capabilities through reasoning-based training.
-----
https://arxiv.org/abs/2501.18492
📌 GuardReasoner pioneers explicit reasoning in guard models. It moves beyond mere classification. The model learns to justify its safety assessments, enhancing robustness.
📌 Reasoning Supervised Fine-tuning unlocks crucial reasoning skills in smaller guard models. This method enables efficient safety enforcement without relying on massive parameter counts.
📌 Hard Sample Direct Preference Optimization strategically refines the model's decision boundary. By focusing on ambiguous examples, GuardReasoner achieves higher accuracy on complex safety challenges.
----------
Methods Explored in this Paper 🔧:
→ The paper introduces GuardReasonerTrain, a new dataset with 127K samples and 460K reasoning steps, generated using GPT-4o to add reasoning processes to existing red-teaming datasets.
→ Reasoning Supervised Fine-tuning (R-SFT) is proposed. R-SFT trains base models on GuardReasonerTrain to unlock basic reasoning capabilities by predicting both reasoning steps and moderation results.
→ Hard Sample Direct Preference Optimization (HS-DPO) is introduced to further refine reasoning. HS-DPO focuses on ambiguous samples near the decision boundary, weighting samples based on the correctness of initial predictions to emphasize learning from difficult cases.
→ HS-DPO uses an ensemble of R-SFT models to enhance the diversity of identified hard samples, improving robustness.
-----
Key Insights 💡:
→ Reasoning is crucial for improving guard model performance, explainability, and generalization.
→ Training guard models to explicitly reason enhances their ability to detect harmful content and adapt to new threats beyond predefined categories.
→ Focusing on hard samples during training, especially ambiguous cases, significantly improves model accuracy.
-----
Results 📊:
→ GuardReasoner 8B outperforms GPT-4o+CoT by 5.74% and LLaMA Guard 3 8B by 20.84% in average F1 score across 13 benchmarks.
→ On prompt harmfulness detection, GuardReasoner 8B achieves 81.09% average F1 score, surpassing open-source runner-up by 3.10%.
→ On response harmfulness detection, GuardReasoner 8B achieves 81.22% average F1 score, outperforming closed-source runner-up by 6.77%.