
🧮 “Historic” day for AI, akin to the Deep Blue computer defeating Garry Kasparov at chess in 1997
AI hits a Deep Blue–level milestone, OpenAI adds teen safety checks, Microsoft finds agent-tool overload issues, and Google drops a payments protocol for AI agents.
Read time: 11 min
📚 Browse past editions here.
( I publish this newsletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (18-Sept-2025):
🧮 ABSOLUTELY “historic” day for AI, akin to the Deep Blue computer defeating Garry Kasparov at chess in 1997 and an AI beating a human Go champion in 2016.
🗞️ OpenAI just announced new ChatGPT teen-safety measures that will include age prediction and verification.
🧰 Microsoft researchers studied how agents use the Model Context Protocol (MCP), and they found that when too many tools are available, agents start interfering with each other.
💳 Google just released Agent Payments Protocol (AP2), an open way for AI agents to make traceable, authorized purchases with 60+ partners.
🧮 ABSOLUTELY “historic” day for AI, akin to the Deep Blue computer defeating Garry Kasparov at chess in 1997 and an AI beating a human Go champion in 2016.
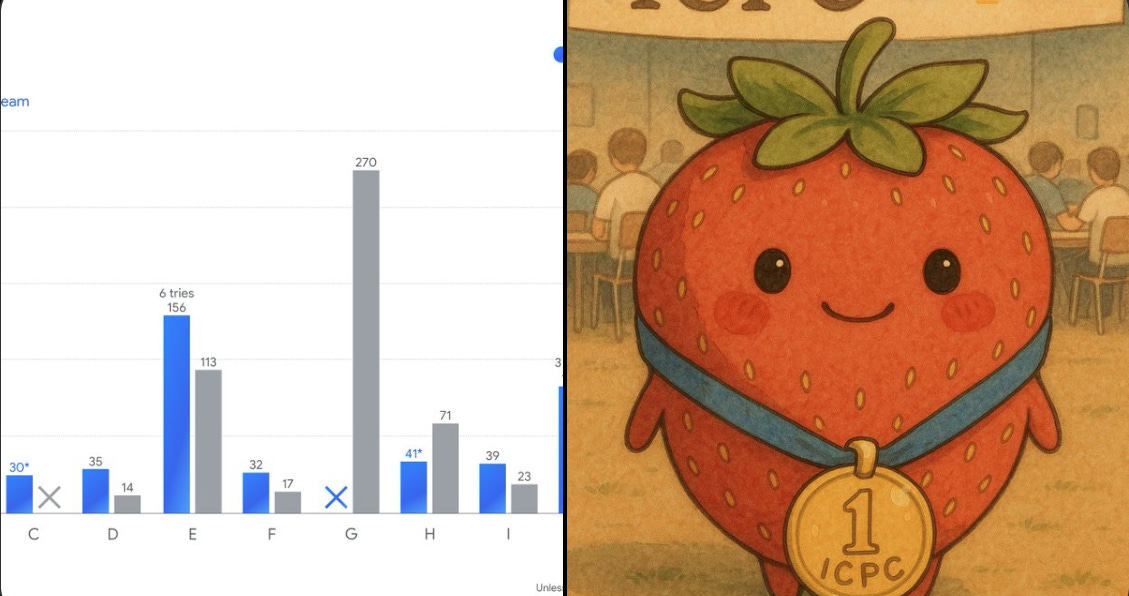
OpenAI and GoogleDeepMind both showcased historic performances at the 2025 International Collegiate Programming Contest (ICPC) World Finals, the world’s premier coding competition. GPT-5 plus an experimental model, solved 12 out of 12 ICPC World Finals problems under contest conditions, which would place it 1st if ranked with humans.
And for Google DeepMind, an advanced Gemini 2.5 Deep Think solved 10 out of 12 in 677 minutes, which would place it 2nd, and it uniquely solved a ducts flow problem no human team solved.

In a performance that GoogleDeepMind called a “profound leap in abstract problem-solving”, it took less than half an hour to work out how to weigh up an infinite number of possibilities in order to send a liquid through a network of ducts to a set of interconnected reservoirs. The goal was to distribute it as quickly as possible.
None of the human teams, including the top performers from universities in Russia, China and Japan, got it right. OpenAI used its latest GPT-5 model for all problems except the final and hardest one, which it solved using a combination of GPT-5 and an experimental reasoning model.
Both efforts ran in an ICPC-supervised AI track, with the same 5-hour window and the same local judge as the human contest, not on the official human leaderboard. Human results are unchanged. Golds went to St. Petersburg State University, University of Tokyo, Beijing Jiaotong University, and Tsinghua University.
None of the human teams solved 12 out of 12. Harvard and MIT earned silver. Scale details need a tweak. The finals featured 139 teams. Countries at the finals were “over 50,” while “over 103 countries” refers to the global program across the season, not necessarily the finals.
Google’s earlier math milestone is accurately described as “gold-medal level” at IMO 2025, certified by IMO coordinators. OpenAI also states it did not train a special ICPC-tuned model.
On the point of how much computing power was needed, we dont have a clear data. But Google confirmed it was more than available to an average subscriber to its $250-a-month Google AI Ultra service using the lightweight version of Gemini 2.5 Deep Think in the Gemini App.
Jelani Nelson, chair of University of California, Berkeley’s electrical engineering and computer sciences department, said: “It’s impressive for a purely AI system with no human in the loop to be able to get the performance that they did. “If someone had told me just a few years ago that we would have new technology that was able to perform at this level in math and in computer science, I would not have believed them,” added Nelson, who has coached several ICPC teams at Massachusetts Institute of Technology, Harvard and UC Berkeley.
In this ICPC contest, teams of 3 share 1 computer to crack 12 tough coding problems in 5 hours. Rankings depend on speed, accuracy, and how many problems they finish. This year, teams solved 10 out of 12. Out of 139 teams, only 4 walked away with gold. To get through the set, you need to unpack complex problems, plan a clear solution, and code it without mistakes. The harder math problems also call for abstract thinking and real creativity.
Four machine intelligence breakthroughs over the last few decades to put the context of today's ICPC performance by OpenAI and Google DeepMind.
🧠 1957 The Perceptron.
Frank Rosenblatt at Cornell said you could build a “perceiving and recognising automaton,” which he called the Perceptron. He argued an electronic system could learn patterns in optical, electrical, or tonal signals, much like a biological brain. In 1958 he built it. The machine filled a small room and stood out as an early neural-network AI breakthrough.
♟️ 1997 Big Blue
In May 1997, IBM’s Big Blue became the first computer to beat a reigning world chess champion under standard tournament rules. It edged Garry Kasparov after a tight match: Kasparov took game 1, Deep Blue won game 2, then 3 draws, and Deep Blue clinched it in game 6. It proved brute-force compute can top a human at a narrow task. Kasparov admitted the machine was “far stronger than anybody expected.”
⚪ 2016 AlphaGo.
Go is famously complex. In 2016, DeepMind’s AlphaGo faced Lee Sedol, a top South Korean pro, and won 4-1. Some moves looked startlingly original, with Move 37 becoming legend. Demis Hassabis called it a first glimpse of a bold future where AI helps uncover new knowledge for big scientific problems.
🧬2020 AlphaFold.
DeepMind followed with AlphaFold, which predicts how proteins fold into 3D shapes. The Royal Society dubbed it “a stunning advance.” Knowing a protein’s fold helps explain things like insulin’s control of blood sugar and how antibodies fight viruses. With later versions, the system led Hassabis and John Jumper to share the 2024 Nobel Prize in Chemistry.
🗞️ OpenAI just announced new ChatGPT teen-safety measures that will include age prediction and verification.
eenagers chatting with ChatGPT will soon see a very different version of the tool—one built with stricter ways to keep them safe online, OpenAI announced. The new safeguards come as regulators increase scrutiny of chatbots and their impact on young people's mental health.
OpenAI set 3 principles, Privacy, Freedom, Teen protection.
Privacy is treated like a privileged context with stronger protections, with automated monitoring for serious misuse and rare escalation to human review for extreme risks like threats to life or large-scale harm.
Freedom here means adults can choose broader uses within safety bounds, for example flirtatious talk if explicitly requested or help writing fiction that includes suicide.
Teen protection comes first when principles conflict.
To separate teens from adults, OpenAI is building an age-prediction system that infers whether someone is over or under 18 from usage. If confidence is low, the system defaults to the under-18 experience. In some places OpenAI may ask for ID, which they acknowledge is a privacy tradeoff for adults. Adults will have ways to verify their age to unlock adult capabilities.
Rules for under-18 users will be stricter. ChatGPT will refuse flirtatious exchanges and will not engage on suicide or self-harm topics even for creative writing. If a teen appears to be in acute distress, OpenAI will try to reach a parent, and if that fails in a rare emergency, may contact authorities to ensure safety.
Parental controls arrive by the end of Sep 2025. Parents will be able to link accounts for teens 13+, guide how ChatGPT responds using teen-specific behavior rules, disable features like memory and chat history, set blackout hours, and receive notifications if the system detects a moment of acute distress, with possible law-enforcement involvement if a parent cannot be reached.
In-app break reminders will also show up during long sessions. If you are an adult user, you keep broad choice within safety limits, including the ability to request content the default model would avoid, like flirtation or fiction that depicts suicide. If you get put into the teen experience by mistake, you’ll be able to verify age to restore adult features.
💳 Google just released Agent Payments Protocol (AP2), an open way for AI agents to make traceable, authorized purchases with 60+ partners.
\" and \"Announcing Agent Payments Protocol (AP2)\". The Google Cloud logo is visible.")
Ideally, AI agents would handle every task we give them. With browser agents now able to navigate the web and interact with menus much like people do, that scenario is starting to feel realistic. Google and 60 other organizations are launching an open-source payment protocol designed to make AI-driven payments smoother, safer, and trackable. The aim is to let agents finalize purchases even when the user isn’t present. This could also enable new shopping habits, like telling an agent to hunt for deals and buy once a price drops low enough.
AP2 fixes the missing guardrails when agents transact by standardizing authorization, authenticity, and accountability for merchants, banks, and users. Today’s payment systems assume a human is pressing the button. If an AI bot does it, merchants and banks have no proof the user actually approved it, and that creates fraud, accountability, and trust problems.
AP2 solves that by making every transaction carry a cryptographically signed proof of intent. That proof shows exactly what the user told the agent to do and exactly what was approved. So if something goes wrong, there’s an audit trail.
It centers on a Mandate, a tamper proof, cryptographically signed contract using verifiable credentials that proves the user’s instructions. An Intent Mandate records the shopping goal and constraints, and a Cart Mandate finalizes specific items and price the user approves.
For delegated buys, a detailed Intent Mandate sets limits like price and timing, then the agent issues the Cart Mandate when conditions match. Payment attaches to the Cart Mandate to create a non repudiable audit trail, which simplifies disputes and fraud investigations.
AP2 is payment agnostic, spanning cards, real time bank transfers, and stablecoins, and composes with Agent2Agent (A2A) and Model Context Protocol (MCP). The A2A x402 extension adds agent based crypto payments from wallets, keeping the same mandate flow throughout.
Support from Mastercard, American Express, PayPal, Adyen, Coinbase, and others makes adoption credible, while the spec stays open. The full specification for Agent Payments Protocol (AP2) is in this official GitHub.
\" in bold black text. Below the title, a logo shows a stylized human figure with a circular head and lines extending from it. A video thumbnail labeled \"AP2 Overview\" includes the Google logo, colorful lines, and a photo of a man with glasses in a circular frame. Text links for \"License Apache 2.0\" and \"Ask Deepwiki\" are visible at the top.")
How does Google's Agent Payments Protocol (AP2) maintains an auditable record of human consent for authorising the agent for making payment ??
It keeps a tamper proof, cryptographically signed chain of Mandates that capture what the human approved and when. A Cart Mandate is the human present proof that locks the exact items, price, and shipping after the merchant first signs the cart to guarantee fulfillment at that price.
An Intent Mandate will cover human not present cases by spelling out limits like category, price cap, and timing so later actions can be traced back to those rules. A Payment Mandate goes to the payment network and issuer so they know an agent was involved and whether the human was present, which ties risk checks to the same record of consent.
All Mandates are verifiable credentials, which means each one is signed to the user’s identity and cannot be altered without breaking verification. The credentials provider holds payment methods and returns payment options, so the shopping agent never sees raw card data, which keeps the audit trail clean and scoped.
In a normal flow the merchant signs the cart, the user device signs the Cart Mandate and Payment Mandate, then the processor submits the payment with those proofs attached. Anyone investigating later can replay the chain from intent to cart to payment, verify the signatures, and see exactly what the human authorized.
The result is a deterministic, non repudiable audit trail that assigns who approved what and supports clear dispute resolution. In my view the merchant first signature plus the user final signature is the key design choice, because it binds both sides to the same facts and turns consent into a concrete artifact rather than a log line.

For developers, this introduces low-friction, pay-per-use payments - ideal for micropayments, per-crawl fees, and other agent-driven scenarios. For businesses, AP2-enabled agents can now both monetize their services and pay other agents directly, creating new revenue streams and workflows.
With agents that can now move beyond just information exchange to actual economic interactions, models of automation get unlocked:

Making that kind of transaction work is tricky on both the tech side and the social side.
With AP2, agents need two separate approvals before buying anything: first the intent mandate (basically telling the AI, “I’m looking for a polka dot neck tie”), which lets the agent search for the item and talk to sellers; then the cart mandate, which is the final go-ahead once a specific item is picked.

🧰 Microsoft researchers studied how agents use the Model Context Protocol (MCP), and they found that when too many tools are available, agents start interfering with each other.

💡They call this problem tool-space interference.
It shows up in several ways like bloated tool menus, oversized outputs, confusing parameters, duplicate names, and vague error messages. MS researchers also gave fixes: group tools into smaller sets, cache tool schemas, summarize or paginate long responses, use namespaces for names, standardize error formats, and support resource passing.
They recommend adding namespaces, smaller tool menus, simpler parameters, capped output sizes, and clearer error formats. This way, the orchestrator doesn’t get confused about which agent to pick, and the agents can actually cooperate instead of stepping on each other. In fact, one report already showed 40% faster task completion when clients handled namespacing smartly.
---
Microsoft looked at 1,470 servers and saw that some exposed up to 256 tools, while guidance says agents handle tool menus best under 20 options. In fact, with large menus, some models’ performance dropped by 85%. So tool overload isn’t just messy, it breaks accuracy.
Another big issue is output size. Most tools return short answers, but some return hundreds of thousands of tokens. One tool averaged 557,766 tokens, and 16 tools gave outputs over 128,000 tokens.
Since many models can’t even fit that into memory, performance dropped by as much as 91%. Parameters also add friction. Simple “flat” inputs work best, and the researchers found that flattening schemas improved success by 47%.
But many servers still use deeply nested structures, in some cases up to 20 levels deep, which overwhelms the models. Naming collisions cause confusion too.
They found 775 duplicated tool names, and the word “search” appeared in 32 servers. Without namespaces, agents can’t easily tell tools apart, so they may pick the wrong one or fail.
Error handling is messy as well. Out of thousands of cases, 3,536 errors were hidden inside “non-error” responses, and many error messages were too vague to guide recovery. This makes agents stumble when tasks go off track.
Finally, resource sharing is barely used. Only 7.6% of servers expose resources, 5% expose templates, and just 4 tools returned resource links. And there is no clean way yet to send local files to remote servers, which limits collaboration across agents.
This image is showing how tool-space interference happens when multiple agents can all handle the same kind of task, in this case git-related work. The orchestrator is the one that decides which agent to call at each step.
But for any git task, it has too many overlapping choices: it could ask the ComputerTerminal agent to run git commands directly, it could ask the WebSurfer agent to visit GitHub in the browser, or it could call the GitHub MCP server.
Because of this overlap, the orchestrator has to make the same decision again and again at every orchestration step. That increases the chance of conflicts, wasted steps, or wrong tool use, since different agents may split the task state and interfere with one another.

🗞️ Byte-Size Briefs
OpenAI Updates ChatGPT With Controls to Adjust GPT-5 Thinking Duration. OpenAI has introduced a new timer toggle into the ChatGPT message window when Plus users select the ChatGPT-5 Thinking model from the model selector. The toggle lets you switch between Standard and Extended options for thinking time.
Standard, which is the default selection, balances speed with intelligence, while Extended, which was the previous default for Plus users, is also available.
ChatGPT Pro users get two additional options: Light (the snappiest option available) and Heavy (which uses deeper reasoning).
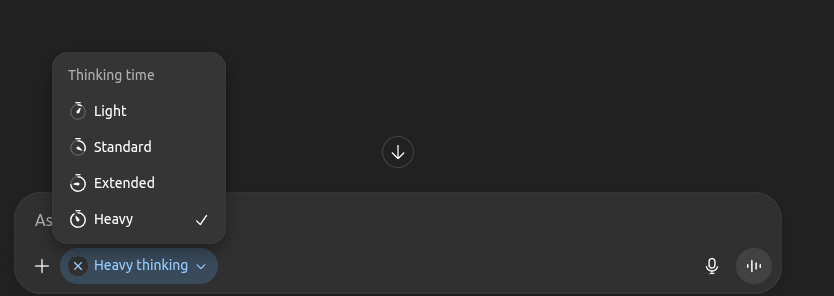
Light and Standard options still use reasoning, but provide quicker answers, while Heavy and Extended modes offer more time for deeper, more comprehensive responses, which are useful when you’re asking more difficult questions.
That’s a wrap for today, see you all tomorrow.