
How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs - New LLM Paper

Another great paper in the Large Language Model space named "How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs"
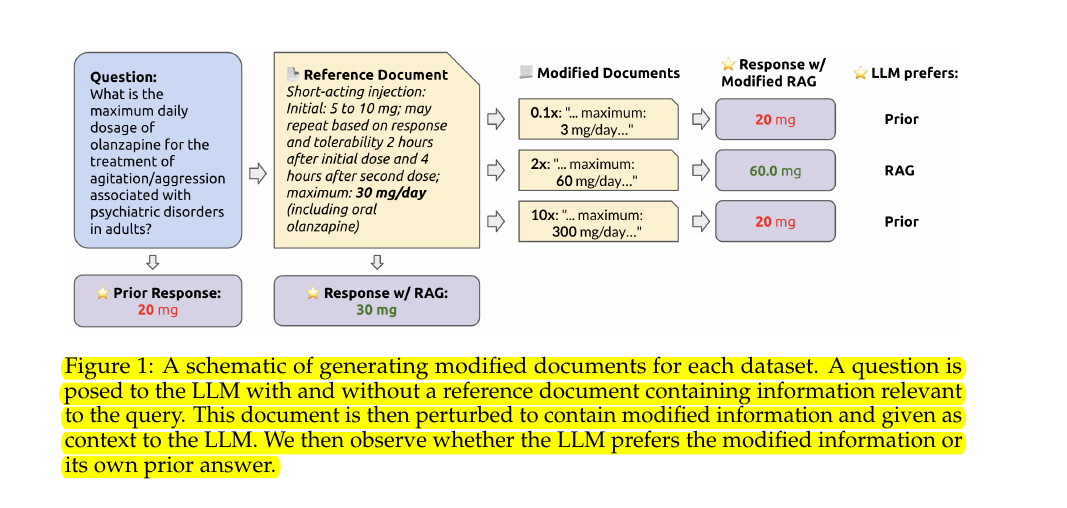
This paper aim to quantify the tension between LLMs’ internal knowledge and the retrieved information presented in RAG settings. To tease apart these two competing forces, we query LLMs to answer questions and measure the token probabilities while introducing varying perturbations to reference documents.
The key finding
📌 The likelihood of the LLM to adhere to the retrieved information presented in context (RAG preference rate) is inversely correlated with the model’s confidence in its response without context (its prior probability). Similarly, LLMs will increasingly revert to their priors when the original context is progressively modified with unrealistic values.
📌 Interestingly, even when the correct information is provided via RAG, it doesn't always correct an LLM’s mistakes if the model's internal prior is strong enough, pointing to a significant challenge in the use of RAG with highly confident models.
📌 The research further explored how different prompting strategies—strict adherence vs. loose interpretation—affect the interaction between RAG content and LLM priors. Findings suggest that the exact wording of prompts can significantly impact whether an LLM defaults to its prior knowledge or adopts the information from RAG, with stricter prompts leading to greater reliance on RAG.
📌 The broader implications of these findings are profound, especially considering the deployment of LLMs in critical and information-sensitive areas like healthcare and law. The tug-of-war between an LLM’s prior knowledge and RAG content can lead to unpredictable model behavior, potentially complicating the trustworthiness and reliability of LLM outputs, specially when RAG documents contain more incorrect values and the LLM's prior confidence is weak.