
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
You need exactly 200-600 images to train AI for copying an artist's style (e.g. Van Gogh's artistic style ).


You need exactly 200-600 images to train AI for copying an artist's style (e.g. Van Gogh's artistic style ).
This paper finds the precise thresholds, called "Imitation threshold" for AI's ability to mimic artistic styles.
Original Problem 🎯:
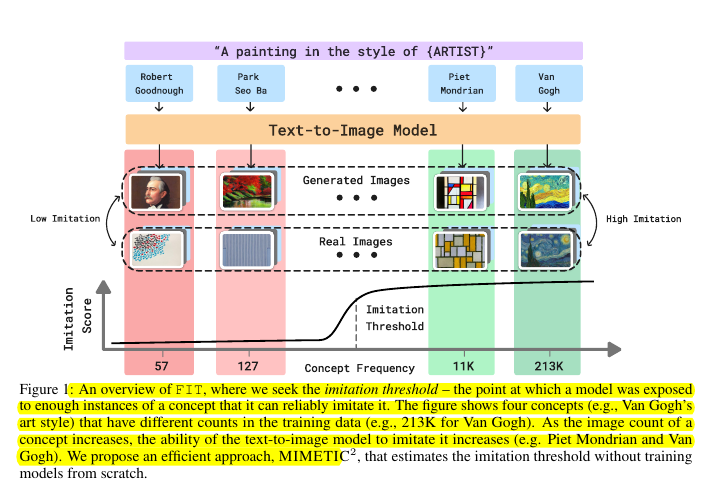
Text-to-image models trained on scraped internet data can imitate copyrighted content. But we don't know how many training images it takes for a model to start imitating a concept (like an artist's style or person's face).
Solution in this Paper 🔧:
• Introduced MIMETIC2: Measures imitation without costly model retraining
• Uses domain-specific embedders (InsightFace for faces, CSD for art styles)
• Automatically filters and verifies concept presence in training data
• Computes similarity between generated and training images
• Accounts for concept aliases and image composition
Key Insights 💡:
• Multiple aliases significantly impact concept frequency counts
• Images with multiple concepts reduce learning effectiveness
• Dead URLs in training datasets affect frequency estimates (26% unavailable)
• Image quality and composition influence imitation capability
Results 📊:
• Imitation threshold: 200-600 images depending on model/domain
• Validated against human perception with high correlation
• Tested on 3 Stable Diffusion models (1.1, 1.5, 2.1)
• Successfully identified outliers due to alias effects
• 74% successful retrieval rate from training datasets
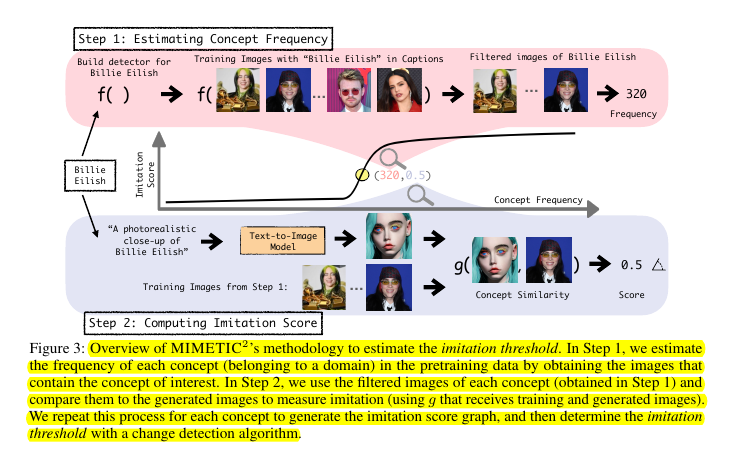
🎨 How imitation of art styles and faces are measured ?
They used specialized embedding models - InsightFace for faces and CSD for art styles - to compute similarity scores between generated and training images. They validated these automated metrics against human evaluations to ensure they matched human perception.
🧮 The team had to account for:
Multiple aliases/names for the same concept
Image quality and composition
Dead URLs in training datasets
Presence of multiple concepts in single images

🔬 The methodology for finding imitation thresholds efficiently
Instead of costly model retraining, they:
Located concept instances in pretraining data
Used domain-specific embeddings to verify concept presence
Generated images with different concept frequencies
Measured similarity between generated and training images
Determined minimum frequency needed for reliable imitation
⚠️ Important edge cases and limitations discovered
Concepts with multiple aliases were undercounted initially
Images with multiple people reduced imitation effectiveness
Not all training images contribute equally to learning
Factors beyond frequency affect imitation (resolution, diversity, etc)
This Paper provides an empirical basis for copyright claims where AI has imitated the originals.
It finds you need exactly 200-600 images to train AI for copying an artist's style (e.g. Van Gogh's artistic style ).
So if they find more than ~600 of their images in a model's training data, they have stronger grounds for legal action
The paper gives empirical evidence that this quantity is enough for the model to replicate their style
Can also help assess potential damages based on how extensively their work was used
Hence, for Model Developers:
Creates clear guidelines for data filtering
If a concept appears less than ~200 times, the model likely can't imitate it effectively
Helps establish "safe" thresholds when curating training datasets
Previously, there was no empirical way to determine if a model had "enough" training data to copy someone's style. This paper changes that by providing specific numerical thresholds.