
Implementing DocOwl2 for OCR-free Multi-page Document Understanding - Code and explanations
mPLUG-DocOwl2 achieves state-of-the-art Multi-page Document Understanding performance with faster inference speed and less GPU memory

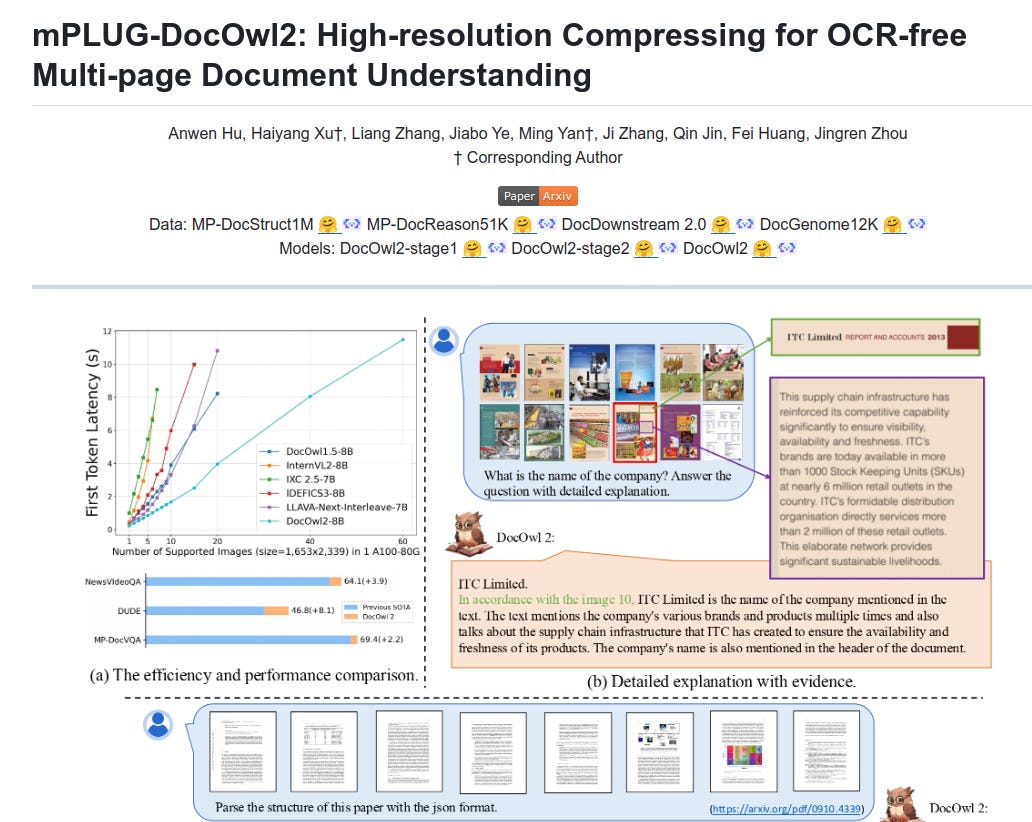
What is mPLUG-DocOwl2?
mPLUG-DocOwl2 is modularized Multimodal LLM for Document Understanding without relying on traditional OCR (Optical Character Recognition). Think of it as a highly efficient "document reader" that can:
Process multiple pages simultaneously
Understand document layout and structure
Work with both text and visual elements
Handle high-resolution documents efficiently
What’s so special about mPLUG-DocOwl2?
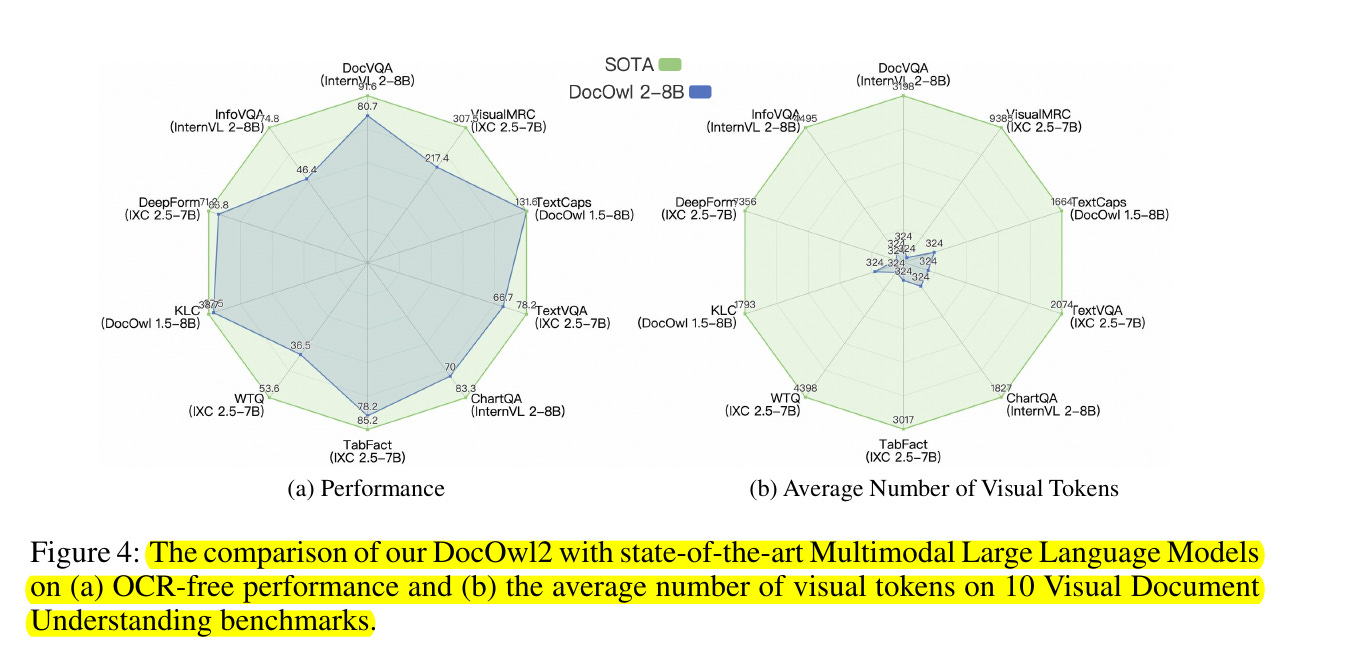
Performance Comparison (Spider Chart):
- The blue region represents DocOwl2's performance across multiple benchmarks
- The green region shows SOTA (State-of-the-Art) performance
- As you can see, that DocOwl2 achieves competitive performance across various document understanding metrics while using significantly fewer resources
Efficiency Breakthrough
Traditional models need thousands of tokens to process a single page
DocOwl2 achieves the same or better results with just 324 tokens per page
This means faster processing and lower computational costs
Practical Benefits
For PDF document processing, DocOwl2 offers:
50% faster processing speed
Better memory efficiency
Improved accuracy in document understanding
No need for separate OCR processing
Real-World Applications
DocOwl2 excels in:
Processing business documents
Analyzing academic papers
Handling complex layouts
Understanding tables and charts
Processing multi-page reports
Why It's Revolutionary
Traditional document processing faces three main challenges:
High computational requirements
Slow processing speeds
Limited multi-page understanding
DocOwl2 solves these by:
Using efficient compression (324 tokens vs. thousands)
Processing documents faster (>50% speed improvement)
Understanding documents as a whole, not just page by page
DocOwl2's has three key innovations:
1. High-resolution DocCompressor
Think of this as an intelligent document summarizer that:
Takes a high-resolution document
Uses two views: a bird's-eye view (global) and detailed close-ups (sub-images)
Combines these views efficiently using cross-attention
Compresses each page to just 324 tokens while keeping important information
Real-world analogy: Like having both a map and street-level photos of a city, then efficiently combining them to understand the whole area.
2. Shape-adaptive Cropping
Shape-adaptive Cropping is a fundamental preprocessing technique in DocOwl2 that serves as the first stage in processing high-resolution document images. Here's why it's important:
Purpose: It segments high-resolution document images into manageable pieces while preserving structural information and spatial relationships
Key Innovation: Unlike fixed-size cropping, it adapts to the document's layout and natural structure
Dual Processing: Creates both local detailed views (sub-images) and a global overview of the document
This is like a smart document scanner that:
Cuts the document into a 12x12 grid of smaller pieces
Maintains the document's natural structure
Preserves how different parts relate to each other
Creates both detailed views and an overview
Real-world analogy: Similar to taking both panoramic and close-up photos of a building, ensuring you capture both overall structure and details.
3. Vision-to-Text Alignment (H-Reducer)
This acts as a translator between visual and text understanding:
Converts visual features into a format that language models can understand
Preserves document layout information
Helps the model understand both what it "sees" and what it "reads"
Bridges the gap between visual and textual understanding
Real-world analogy: Like having a skilled interpreter who can describe complex visual scenes in clear, structured language.
Implementing DocOwl2: Let's go through the coding steps
1. Configuration Management
@dataclass
class ProcessingConfig:
max_image_size: int = 4096
target_size: int = 504
grid_size: int = 12
dpi: int = 300
batch_size: int = 4
This configuration class centralizes our key parameters:
max_image_size: Maximum dimension for input imagestarget_size: Target size for processed image segmentsgrid_size: Number of grid divisions (12x12 for DocOwl2)dpi: Resolution for PDF conversionbatch_size: Number of images processed simultaneously
Document Preprocessing: For DocOwl2, I need to Converts PDF to image format
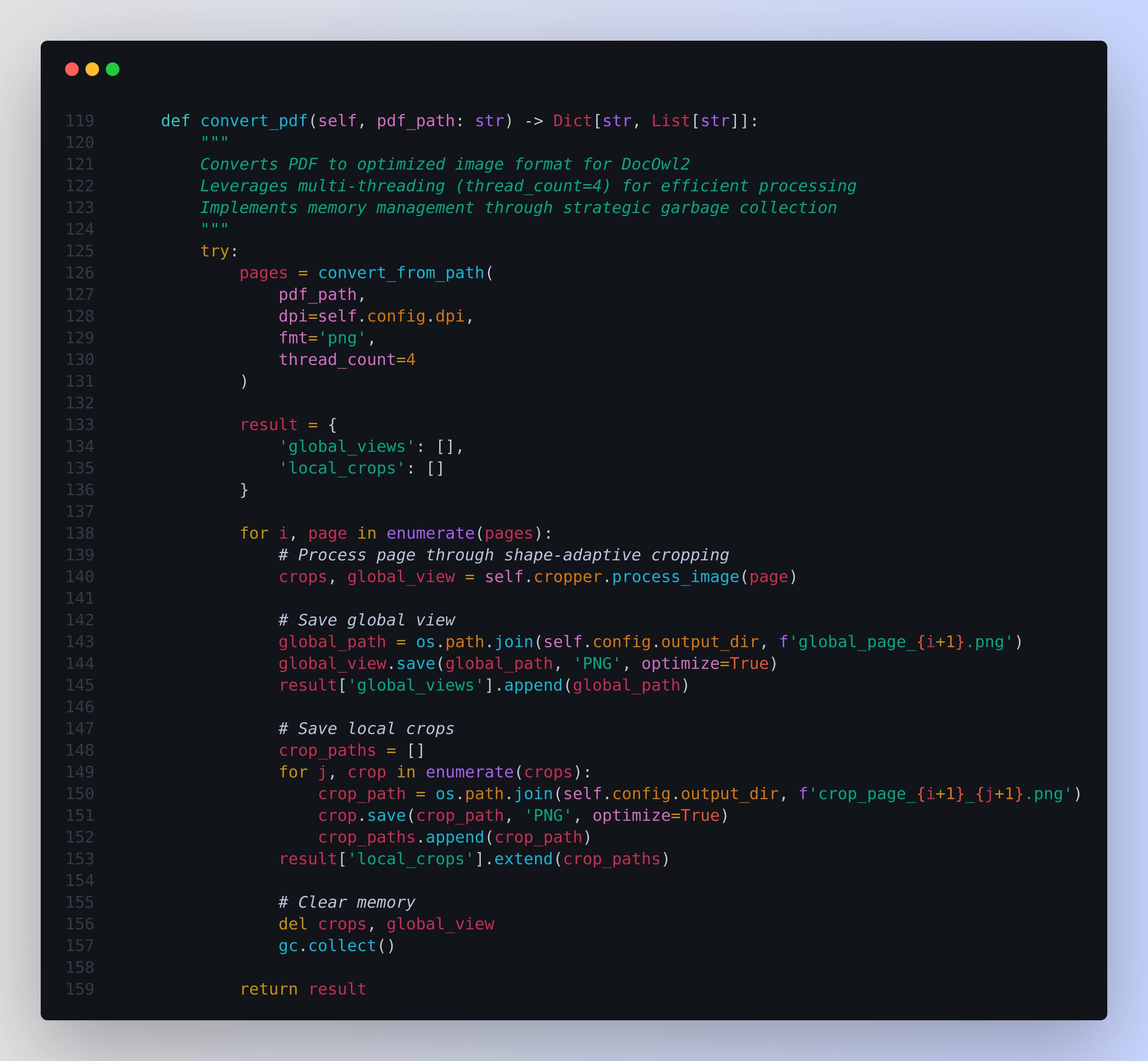
Because DocOwl2 operates as a visual understanding model that processes information through a sophisticated vision encoder pipeline. i.e. The DocOwl2 model relies on visual tokens, which means it needs image data, not PDF pages. Although PDF pages contain text and vector information, these are not directly compatible with image-based preprocessing steps like shape-adaptive cropping.
That basically means
DocOwl2's transformer backbone expects visual tokens as input
The model learns spatial and contextual relationships from image-based representations
No direct PDF parsing capabilities exist in the core neural architecture
And
PDF documents contain complex layouts, formatting, and embedded elements
Converting to standardized image format creates a consistent input pipeline
Enables uniform processing across diverse document sources
Also then also image is required for Performance Optimization
Image-based processing allows controlled resolution and quality parameters
Enables efficient grid-based segmentation and token generation
Facilitates memory-efficient parallel processing of document components
So overall, by converting each PDF page into a high-quality PNG image, we create a uniform format that can then be split into smaller crops and processed by the model’s visual compression and tokenization layers. This step ensures that all content, including complex layouts, fonts, and embedded images, is transformed into a standard visual representation that the DocOwl2 system can parse efficiently, leading to improved understanding of the document’s structure and content.
2. Shape-Adaptive Cropping - Implementation
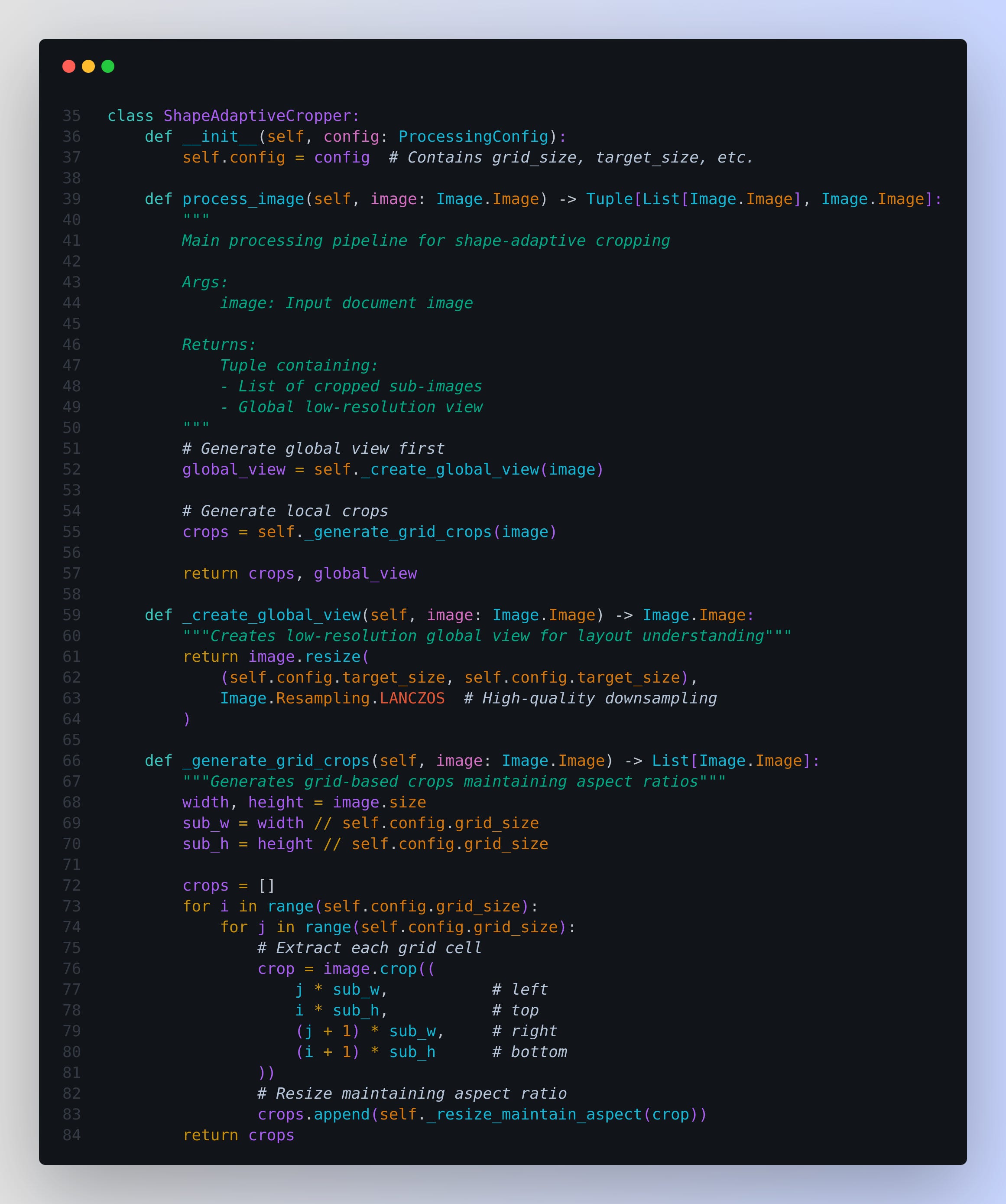
def process_image(self, image: Image.Image) -> Tuple[List[Image.Image], Image.Image]:
global_view = self._create_global_view(image)
crops = self._generate_grid_crops(image)
return crops, global_view
This method implements DocOwl2's dual-view processing strategy:
Creates a global view for layout understanding
Generates detailed local crops for content analysis
Returns both views for subsequent processing
Global View Creation
def _create_global_view(self, image: Image.Image) -> Image.Image:
return image.resize(
(self.config.target_size, self.config.target_size),
Image.Resampling.LANCZOS
)
When processing documents like academic papers or business reports, one of the biggest challenges is understanding the overall layout while still capturing fine details. The _create_global_view method solves this by creating what we can think of as a "bird's eye view" of the document.
It takes a high-resolution document and creates what's essentially a smart preview - imagine taking a detailed document and creating a carefully downsized version that still lets you see the overall structure clearly.
The method uses LANCZOS resampling to resize the image to a standard 504x504 pixels. This isn't just simple downsizing - LANCZOS ensures that even as the image gets smaller, you can still make out important visual elements like text blocks, tables, and section boundaries. It's like creating a high-quality thumbnail that preserves the document's key structural features.
This global view serves as a map that helps DocOwl2 navigate the document efficiently. Before analyzing specific text or details, the model uses this overview to understand how the document is organized. This intelligence directly impacts how DocOwl2 processes the document's finer details and ultimately leads to better document understanding with less computational overhead.
Grid-Based Cropping
def _generate_grid_crops(self, image: Image.Image) -> List[Image.Image]:
width, height = image.size
sub_w = width // self.config.grid_size
sub_h = height // self.config.grid_size
crops = []
for i in range(self.config.grid_size):
for j in range(self.config.grid_size):
crop = image.crop((
j * sub_w, # left
i * sub_h, # top
(j + 1) * sub_w, # right
(i + 1) * sub_h # bottom
))
crops.append(self._resize_maintain_aspect(crop))
return crops
This method implements an intelligent grid-based image cropping system.
It takes an input image and divides it into a grid of equal-sized sections based on the configured grid_size parameter.
Systematic Cropping: Methodically extracts each grid section using precise coordinates, maintaining spatial relationships between segments.
Aspect Ratio Preservation: Each crop gets resized while preserving its original proportions through the _resize_maintain_aspect helper method.
This creates a uniform set of image segments that can be processed individually while maintaining the overall document structure - essential for tasks like document analysis and understanding.
Key Implementation Features:
Grid Calculation:
Divides image dimensions by grid size
Creates uniform sub-regions
Maintains spatial relationships
Systematic Cropping:
Iterates through grid positions
Extracts fixed-size regions
Preserves document structure
Aspect Ratio Preservation:
Each crop maintains original proportions
Prevents content distortion
Ensures text readability
So how does it align with DocOwl2's Goals
This implementation supports DocOwl2's key innovations by:
Layout Preservation:
Grid-based approach maintains structural relationships
Global view captures overall layout
Local crops preserve detailed content
Efficient Processing:
Systematic division reduces complexity
Parallel processing potential
Memory-efficient implementation
Quality Maintenance:
High-quality resampling
Aspect ratio preservation
Balanced detail retention