
In the context of Advanced Search Algorithms in LLMs, Compare different information retrieval metrics and which one to use when?

Browse all previoiusly published AI Tutorials here.
Table of Contents
Introduction
Retrieval Methods Vector Sparse and Hybrid
Relevance Focused Evaluation Metrics
Efficiency Metrics and Resource Considerations
Synthesis of Research Findings
Comparison of Metrics Strengths and Weaknesses
Conclusion
Introduction
Large Language Models (LLMs) are transforming search algorithms by enabling more semantically rich retrieval methods. Modern advanced search systems often combine traditional sparse retrieval (lexical search) with dense vector search to leverage the strengths of both approaches. In dense or vector search, queries and documents are encoded as high-dimensional vectors, and relevant results are found via nearest-neighbor similarity (e.g., dot product) (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?). Sparse retrieval uses lexical term matching (e.g., BM25), which is fast and interpretable, while dense embeddings capture semantic meaning beyond exact terms. Recently, hybrid retrieval methods that fuse dense and sparse techniques have shown improved performance over either method alone (HERE). This LLM-driven convergence of retrieval techniques necessitates robust evaluation metrics to quantify relevance and efficiency for both real-time search applications and offline batch knowledge retrieval.
Retrieval Methods Vector Sparse and Hybrid
Vector (Dense) Retrieval: Dense retrieval represents text with learned embeddings (often via transformers), enabling semantic matches beyond keyword overlap. A dense retriever scores relevance by vector similarity (e.g., cosine or dot product) and must efficiently find top-kk nearest neighbors from a large embedding index . LLM-based search often relies on dense retrievers fine-tuned on relevance data, achieving higher recall and better semantic ranking than pure lexical methods. However, dense methods come with computational overhead – encoding queries into vectors and searching large vector indices can be resource-intensive. For example, a dense index for the Wikipedia corpus (~9.7 GB of embeddings) yields an average query latency of ~610 ms without acceleration (HERE). Techniques like HNSW graphs (Hierarchical Navigable Small-World) are used to speed up vector search, trading some accuracy for efficiency . Recent research emphasizes the effectiveness–efficiency tradeoff between dense and sparse models: dense models often achieve higher relevance scores (e.g., NDCG) at the cost of slower queries, whereas sparse models (like BM25) offer lower latency .
Sparse Retrieval: Sparse methods use term-frequency signals (e.g., BM25 or TF-IDF) or learned sparse representations (e.g., SPLADE) to match query and document terms. These systems excel at precision for queries with clear lexical cues and are highly efficient due to inverted indexes. They typically have a smaller memory footprint per document compared to dense vectors, since they store weighted term postings rather than dense floating-point vectors. For instance, classical BM25 on a large corpus can achieve hundreds of queries per second on a single CPU (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?) . Sparse retrievers, however, may miss relevant documents that use different vocabulary than the query (semantic gap). Learned sparse models (using transformer encoders to predict important lexical features) attempt to bridge this gap, and in some cases approach dense retrieval effectiveness while retaining the speed of inverted indexes .
Hybrid Retrieval: Combining dense and sparse retrieval scores (hybrid search) offers a best-of-both-worlds approach. Hybrid retrieval systems run both a dense and a sparse search and then fuse results, often leading to higher recall and NDCG than either alone (HERE). The dense component can surface semantically relevant items that lexical search misses, while the sparse component ensures exact keyword matches are not overlooked. Recent domain-specific QA systems report significant improvements in NDCG and accuracy metrics when using hybrid retrieval versus single-method approaches . The main trade-off is increased complexity and resource usage: running two retrieval pipelines can increase latency if not optimized. Some production systems mitigate this by using hybrid retrieval selectively (e.g., falling back to dense search only when sparse results are insufficient). Overall, the literature indicates that hybrid methods can boost relevance metrics substantially, which is crucial in LLM contexts where “garbage in, garbage out” applies – high-quality retrieved context is needed to ground LLM responses .
Relevance Focused Evaluation Metrics
To evaluate the retrieval quality of LLM-based search algorithms, researchers rely on classic information retrieval metrics adapted to modern systems. These metrics compare the ranked list of results against ground-truth relevant documents and quantify how well the system retrieves relevant information. Recent 2024 benchmarks explicitly use a suite of ranking metrics for comprehensive evaluation (HERE). Key metrics include Precision@K, Recall@K, and Normalized Discounted Cumulative Gain (NDCG@K), among others (Large Language Models for Information Retrieval: A Survey) . We summarize these as follows:
Precision@K (P@K): The proportion of the top K retrieved results that are relevant. This metric emphasizes accuracy in the first page of results. A high P@K means that users examining the top-KK hits will find most of them relevant. Precision@K is crucial for user-facing search where a user typically scans only the top results. Its strength is rewarding systems that put few non-relevant items in the top ranks, directly reflecting precision of the highest-ranked answers. However, P@K ignores any relevant documents ranked lower than K, so it does not capture recall or the system’s ability to find all relevant information. For example, if there are many relevant documents for a query but the system finds only a few (albeit top-ranked), P@K may be high while recall is low. In LLM-augmented search, maintaining high precision in the top results is important to ensure the context fed into the LLM is reliable. Recent research continues to report Precision@K for evaluating dense vs. sparse retrievers – e.g., an IR benchmark logs precision@3 alongside other metrics to assess retrieval quality .
Recall@K (R@K): The fraction of all relevant documents that are retrieved in the top K results (HERE). This metric focuses on coverage of relevant information. High Recall@K indicates the system successfully finds most of the pertinent documents (within the cutoff K), which is especially important for knowledge-intensive tasks or batch retrieval where missing relevant facts is costly. Recall@K is often reported with fairly large K (e.g. 10, 50, 100) to evaluate how many relevant items are surfaced when the system has more allowance PDF Language Modeling on Tabular Data - arXiv. Its strength is in evaluating completeness – a system with higher recall is less likely to omit useful information. The downside is that recall does not consider ranking order or precision; a method that retrieves many relevant items by also returning many irrelevant ones can score high on recall. Thus, recall is often balanced with precision metrics. In LLM contexts (like Retrieval-Augmented Generation), high recall ensures the model has the necessary information somewhere in the top results, which can then be selected or re-ranked by the LLM. Recent works use Recall@K alongside NDCG to judge if efficiency optimizations degrade the ability to retrieve relevant documents – e.g., ensuring that compressed indexes still achieve comparable Recall@10 (HERE).
Normalized Discounted Cumulative Gain (NDCG@K): NDCG is a rank-sensitive metric that accounts for the position of relevant documents in the ranked list and allows for graded relevance (e.g., highly relevant vs partially relevant) . The NDCG@K for a result list is calculated by accumulating gains for each result up to rank K, where each gain is discounted logarithmically by the result’s rank position, and then normalizing by the ideal ranking’s score. In essence, NDCG rewards placing highly relevant documents towards the top of the ranking. This metric is widely used in academic and industrial search evaluations because it correlates well with user satisfaction for ranked results. A key strength of NDCG is its sensitivity to ranking order: improving the rank of a relevant document yields a higher NDCG, which distinguishes it from plain recall/precision. It also handles multi-level relevance judgments (e.g., excellent/good/fair) by assigning larger gains to higher-judged items. NDCG’s weakness is its complexity; it’s less intuitive than precision or recall and requires careful interpretation (the values are normalized and unitless). Nonetheless, virtually all advanced retrieval studies report NDCG@K as a primary effectiveness metric (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?). For example, Lin et al. (2024) compare dense and sparse retrieval methods on BEIR datasets using NDCG@10 to measure ranking quality, alongside reporting query throughput . In LLM-based search, NDCG is useful to evaluate how well the system ranks truly useful context at the top, which can directly impact an LLM’s generated answer quality.
Other relevance metrics: Two other metrics frequently seen in the literature are Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP). MRR focuses on the rank of the first relevant result, computing the reciprocal of that rank (averaged over queries). It is high when the system typically returns a relevant result very early (e.g., an MRR of 0.5 means on average the first relevant item is at rank 2). MRR@10 is used in many evaluations for question-answering style tasks where having a correct answer document at rank 1 is vital (HERE). Its strength is simplicity and pertinence to scenarios like QA or conversational search (the user’s primary need is satisfied by the top answer), but its weakness is that it ignores all but the first relevant result. MAP, on the other hand, averages precision over all recall levels (essentially the area under the precision-recall curve for a query, averaged across queries). It provides a single-figure summary of ranking quality across all positions. MAP is a stringent metric that heavily penalizes missing any relevant items (low recall). While MAP is less common in very large-scale retrieval evaluations (due to incomplete relevance labeling in web-scale test sets), some works still report it for thoroughness . In sum, contemporary LLM-oriented IR research leans on a combination of these metrics – each metric offers a different perspective on relevance, and together they provide a holistic evaluation (Large Language Models for Information Retrieval: A Survey). Indeed, a recent benchmark for Retrieval-Augmented Generation used nDCG@10, MRR@10, MAP@10, Precision@3, and Recall@10 all in concert to assess retriever performance .
Efficiency Metrics and Resource Considerations
Beyond relevance, efficiency-related metrics are crucial for evaluating advanced search algorithms, especially as applications move from offline experimentation to real-world deployment. Key considerations include latency (response time), throughput, and memory footprint of the retrieval system. These metrics ensure that a retrieval method not only finds relevant results but does so quickly and within resource constraints – which is vital for real-time AI applications.
Latency (Query Time): Latency measures the time taken to return results for a query. In practice this is often reported as average milliseconds per query or as queries per second (QPS) (the inverse measure) for a given hardware setup. Low latency is paramount for real-time search applications like interactive question answering or live chatbot queries, where users (or downstream LLMs) expect prompt responses. Recent research highlights that dense vector search, if done naively, can introduce high latency: e.g., a dense retriever over a large corpus had ~610 ms average latency per query without acceleration (HERE). Techniques such as approximate nearest neighbor indexes (HNSW graphs, IVF, product quantization) can drastically reduce this latency by trading off a tiny bit of accuracy for speed (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?). For instance, using an HNSW index instead of brute-force search improved QPS from single-digit to tens or hundreds on million-scale corpora, while keeping NDCG nearly the same . Latency is typically measured under two scenarios: (1) Including query encoding time (for models that need to encode text into embeddings on the fly, like dense retrievers) and (2) excluding that by using cached embeddings . Researchers distinguish these to simulate real production vs. a batch setting . In production, one must count the encoding time since queries are unknown in advance, whereas in batch/offline experiments or repeated benchmark runs, query vectors can be pre-computed . The goal for real-time systems is often to keep latency within a few tens of milliseconds on average, which requires efficient algorithms and sometimes hardware acceleration (GPU/ANN indexes). High latency not only degrades user experience but also can bottleneck an LLM that retrieves knowledge in the loop. Therefore, many 2024 studies optimize or report latency alongside relevance. For example, Lin et al. report both NDCG@10 and QPS for various index strategies, showing how denser methods slow down as corpus size grows . Another 2025 study achieved a 2× overall speedup in a retrieval pipeline by pruning the search index (reducing data to search through) with only minor loss in Recall@10 . Such results underscore the constant balancing act between speed and effectiveness in LLM-based search.
Memory Footprint (Index Size): Memory usage refers to the amount of memory (or storage) required to hold the index and model for retrieval. This metric is critical for scalability and deployment: a method that requires excessive memory might be impractical for web-scale corpora or edge devices. Dense retrieval models often have a larger memory footprint because each document is stored as a high-dimensional vector (e.g., 768 dimensions float32 each). As one study noted, a full embedding index of Wikipedia occupied ~9.70 GiB , significantly more than a typical inverted index for the same corpus. Such memory demands can make dense search “prohibitively expensive” in large-scale settings . Researchers therefore track index size and apply compression techniques. For example, product quantization (PQ) and other vector compression methods can shrink index size by an order of magnitude. In the fact-checking retrieval study, applying vector quantization reduced the dense index from 9.70 GiB to about 0.66 GiB (672 MiB) – a >10× reduction . This compression led to corresponding speed gains (10× faster CPU retrieval) with only minor accuracy loss. A smaller memory footprint also enables deployment on cheaper hardware and allows caching more of the index in RAM for faster access. Sparse retrieval indexes, by contrast, can be more memory-efficient per document, but they grow with vocabulary and document length. Techniques like document pruning or limiting the number of postings can reduce inverted index size, at some cost to recall. Recent work on efficient retrievers for LLM systems often report memory alongside latency, aiming to create systems that are both fast and light enough for practical use . The drive for real-time LLM applications has made low-memory, low-latency retrieval a key goal . One vision is to enable fact retrieval on edge devices or browsers by compressing both sparse and dense indexes without significant loss in Precision/Recall .
It’s worth noting that throughput (queries per second) is essentially another view of latency (e.g., X QPS = 1/X seconds per query). Batch processing scenarios care about throughput – how many queries can be handled in parallel or over a period – which is crucial when processing millions of queries for offline analysis or building indexable knowledge bases. Batch retrieval jobs may tolerate higher per-query latency by distributing load across machines, focusing instead on total throughput achieved. In contrast, single-query latency is the critical metric for interactive use. Therefore, researchers adjust their evaluation depending on the context: for example, using cached query embeddings to measure maximum throughput in a controlled experiment vs. measuring end-to-end latency to simulate real user query handling (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?).
Synthesis of Research Findings
Relevance vs. Efficiency Trade-offs: Recent arXiv papers underscore that achieving the best relevance (Precision, Recall, NDCG) often involves a cost in efficiency, and vice versa. Dense embedding-based retrievers generally outperform sparse lexical ones on relevance metrics like NDCG@10 and Recall@10 , thanks to their semantic matching ability. However, these gains can come with 10× slower query speeds and much larger indexes if using brute-force search (HERE) . For instance, on a benchmark, a dense model (BGE) achieved substantially higher NDCG@10 than BM25 on a 500K-document corpus, but BM25 handled ~770 queries/sec while the dense model with a flat index managed only single-digit QPS. Employing approximate indexes like HNSW narrowed this gap – the dense model’s QPS improved an order of magnitude with minimal NDCG loss . Similarly, learned sparse models (e.g., SPLADE) have shown NDCG on par with dense models on some tasks , while benefiting from fast inverted-index retrieval. A key finding across studies is that hybrid retrieval can boost Recall and NDCG significantly, which is valuable for feeding LLMs more complete context, though the hybrid approach might double the retrieval work (HERE).
Metric Usage in LLM-based Systems: The core relevance metrics (P@K, R@K, NDCG) remain the go-to evaluation measures in 2024/2025 for advanced search algorithms (Large Language Models for Information Retrieval: A Survey). They are used not only for academic benchmarking but also for guiding engineering decisions (e.g., choosing a retriever for a production QA system). Researchers often publish comprehensive evaluations covering multiple metrics to ensure no single metric’s bias skews the conclusions. For example, one benchmark introduced in 2024 evaluated models on five different retrieval tasks and reported nDCG@10, MRR@10, MAP@10, Precision@3, Recall@10 for each, to capture different aspects of performance . Such thorough reporting reveals strengths and weaknesses of models: one model might excel in precision (high P@3) but have lower recall, indicating it’s conservative in retrieving only obvious matches, whereas another has higher recall but lower precision, suiting recall-critical tasks. NDCG often strikes a balance, reflecting overall ranking quality. In LLM settings, these metrics help ensure that when the retriever fetches supporting passages for the LLM, the passages are both relevant and ranked usefully (so the most relevant info is encountered first by the language model).
There’s also emerging interest in novel evaluation metrics tailored to LLM-augmented retrieval. Some works propose metrics like Similarity of Semantic Comprehension Index (SSCI) and Retrieval Capability Contest Index (RCCI) to compare semantic understanding between models or to directly compare two retrieval systems’ performance across queries . While such metrics are experimental, they signal a desire to capture nuances (e.g., how well an LLM understands retrieved content) beyond traditional precision/recall. Nonetheless, for relevance-focused evaluation of search, Precision@K, Recall@K, and NDCG remain predominant and are likely to stay standard for comparing systems. Interestingly, LLMs themselves are being used to generate relevance judgments in lieu of human annotators, enabling the calculation of traditional metrics without manual labels (HERE). This 2024 approach allows automated evaluation of retrieval quality (e.g., using an LLM to decide if a retrieved passage is relevant to a query), which can then be quantified by metrics like NDCG, potentially accelerating the development cycle .
Real-Time Search vs. Batch Retrieval: The intended use case influences which metrics matter most. For real-time search or interactive AI assistants, maintaining low latency is as important as high precision. Engineers might choose a slightly less accurate model if it’s significantly faster or smaller, to meet strict response-time SLAs (service level agreements). The literature provides guidance here: for example, compressing an index or using a smaller embedding dimension can drastically cut latency at the cost of a few points of NDCG or recall (HERE) . In production, those few points may be acceptable if the system still returns a correct answer and does so in under 100 ms. By contrast, for batch processing of queries (e.g., indexing a knowledge base, running analytics on millions of queries offline, or training an LLM on retrieved evidence), one can afford slower, more exhaustive retrieval to maximize recall and precision. In these scenarios, metrics like throughput (queries/hour) and total compute cost might be tracked more than single-query latency. The research from Lin et al. (2024) explicitly differentiates a prototyping scenario (where query embeddings are cached to maximize throughput) from a live scenario (where each query must be encoded on the fly) (Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?). This distinction maps to batch vs. real-time contexts. Batch retrieval allows caching and parallelization, effectively bypassing some latency constraints, so a dense model with high recall but slower query encoding might be perfectly usable for nightly jobs. On the other hand, real-time systems demand a balance—often a hybrid retrieval with a strong first-stage sparse retriever (for speed) followed by a dense re-ranker provides a good compromise of speed and quality in practice.
To illustrate, consider a knowledge-base construction task (batch): the priority is to retrieve all relevant facts for each input (high Recall@100), even if it takes a second per query on a powerful server cluster. In such a case, an evaluator might favor a model with 5% higher recall and NDCG despite double the latency. Conversely, an interactive chatbot retrieving answers will prioritize a model that answers in 50 ms over one that answers in 500 ms, provided the precision of the top answer remains acceptable. Thus, the “best” retrieval method and metric weighting can differ: real-time search emphasizes Precision@K and latency, whereas batch retrieval emphasizes Recall (and possibly NDCG for overall quality) and throughput. The good news from recent research is that many efficiency improvements (HNSW indexing, quantization, hybrid fusion) allow systems to approach the best-of-both-worlds: maintaining strong relevance scores while dramatically reducing latency and memory usage.
Comparison of Metrics Strengths and Weaknesses
To summarize the discussed metrics, Table 1 highlights the strengths and weaknesses of key relevance metrics (Precision@K, Recall@K, NDCG, MRR) and efficiency metrics (Latency, Memory Footprint) in the context of LLM-based search:
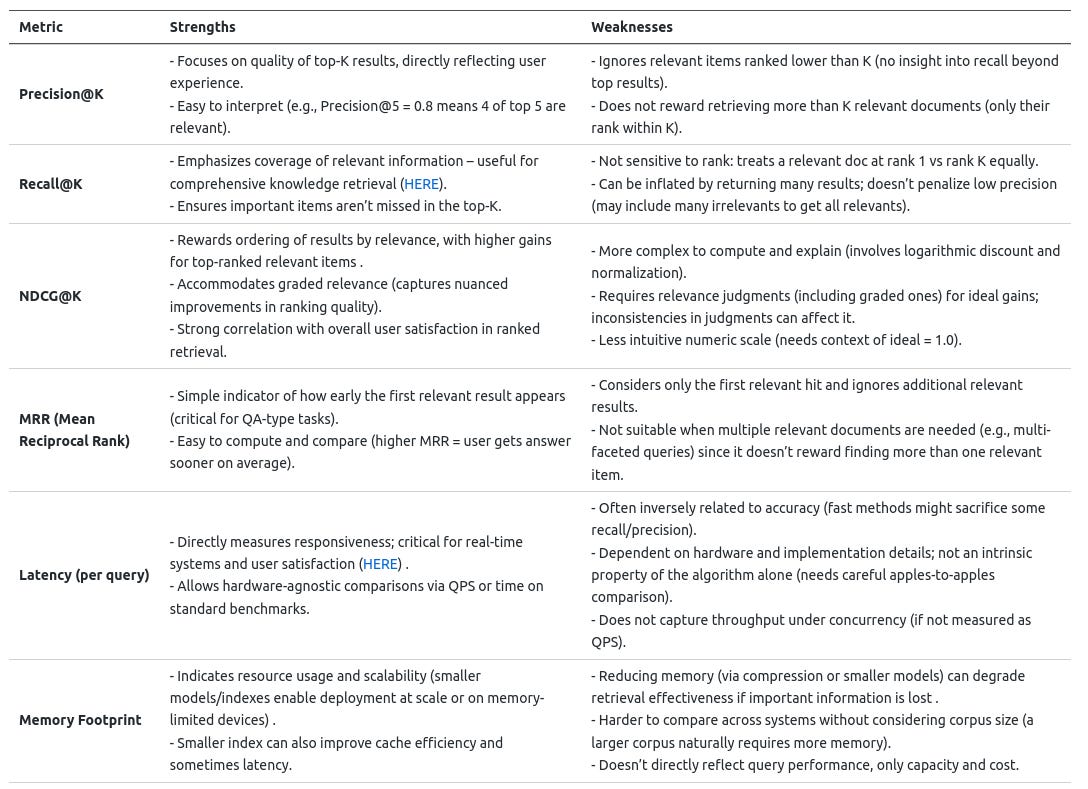
Table 1: Strengths and weaknesses of key evaluation metrics for LLM-based search algorithms. Relevance metrics assess the quality of search results, while efficiency metrics gauge the practicality of the system in real-world deployments. (Sources: definitions and insights synthesized from and referenced works above.)
Conclusion
In summary, the latest research (2024–2025) highlights that evaluating LLM-driven retrieval systems requires a multi-faceted approach. Relevance-focused metrics like Precision@K, Recall@K, and NDCG remain indispensable for judging how well a search algorithm finds and ranks pertinent information (Large Language Models for Information Retrieval: A Survey). These metrics are often reported together to give a balanced view – for instance, ensuring that a method with improved precision does not unduly sacrifice recall. Meanwhile, efficiency metrics such as latency and memory footprint have become equally important in the era of real-time AI services. An ideal advanced search algorithm for LLMs is one that achieves high NDCG (relevant results at the top) and strong Recall@K, without incurring prohibitive latency or memory usage. Achieving this balance is an active area of research: recent advances in index compression, approximate search, and hybrid retrieval are closing the gap, allowing systems to approach the semantic power of dense embeddings with the speed of traditional search (HERE).
For AI and engineering professionals, these findings underscore the need to choose metrics aligned with application needs. In a real-time question-answering system, one might prioritize Precision@K and latency – ensuring the first few results are correct and delivered in milliseconds. For a batch knowledge base curation, one might optimize for Recall@100 and throughput, even if it means each query takes more time, since completeness is key. The literature suggests using hybrid retrieval setups and clever indexing to not have to choose one or the other, yielding both high relevance (e.g., NDCG improvements with dense+lexical fusion (HERE)) and efficiency. Ultimately, maintaining a dashboard of both relevance metrics and system performance metrics is best practice. As the field progresses, we may see new composite metrics (e.g. quality-adjusted latency) tailored for LLM-powered search. For now, a solid understanding of Precision, Recall, NDCG and the real-world constraints of latency and memory provides a strong foundation to design and evaluate advanced search algorithms in the age of LLMs.