
"INT: Instance-Specific Negative Mining for Task-Generic Promptable Segmentation"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2501.18753
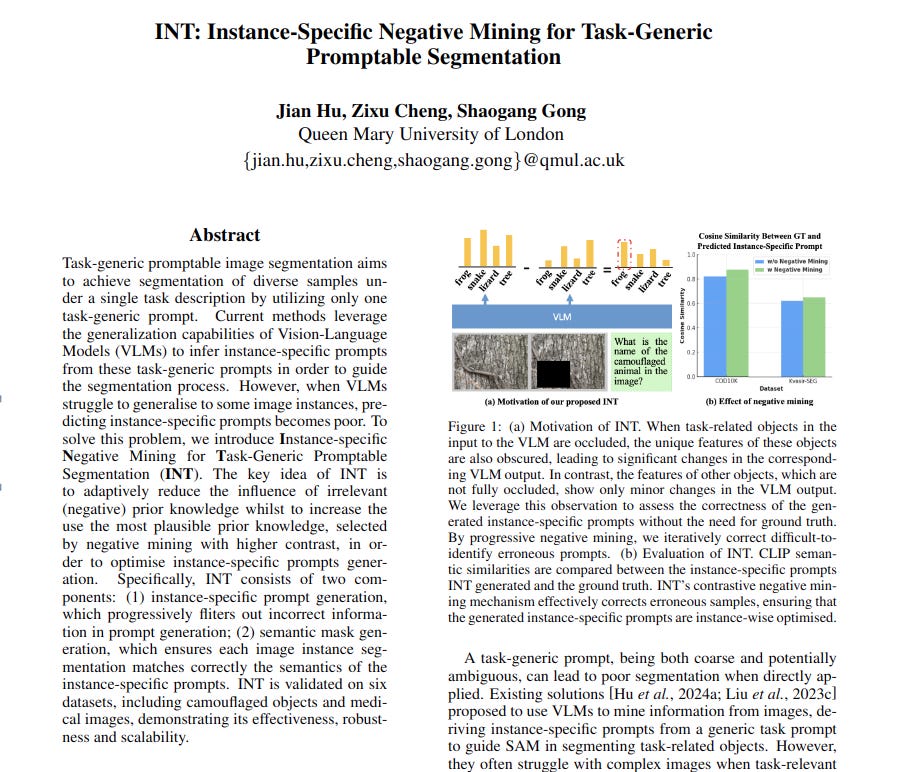
Problem: Task-generic promptable image segmentation struggles to accurately segment diverse images with a single task prompt, especially when Vision-Language Models (VLMs) fail to generalize to specific image instances. This leads to poor instance-specific prompt generation and inaccurate segmentation.
Solution: This paper introduces Instance-specific Negative Mining for Task-Generic Promptable Segmentation (INT). INT adaptively refines instance-specific prompts by reducing irrelevant prior knowledge and enhancing relevant prior knowledge through iterative negative mining.
-----
📌 INT effectively addresses task-generic segmentation by iteratively refining instance-specific prompts. Negative mining using VLM output contrast enables accurate segmentation without instance-specific labels.
📌 Patch-based processing and progressive negative mining in INT enhance robustness. This method corrects initial prompt errors and improves segmentation in complex visual scenes and medical images.
📌 INT's training-free adaptation leverages VLMs, GroundingDINO, SAM, and CLIP in a novel iterative framework. This demonstrates efficient use of existing models for improved segmentation performance across diverse datasets.
----------
Methods Explored in this Paper 🔧:
→ INT uses instance-specific prompt generation and semantic mask generation.
→ For prompt generation, it divides the input image into patches and processes them with VLMs to predict object names and locations. An image inpainting module then removes predicted objects from patches.
→ VLM outputs are compared before and after inpainting. The predictions causing the largest output difference are selected as instance-specific prompts.
→ Progressive negative mining refines prompts iteratively. It normalizes and cumulatively multiplies the VLM output differences across iterations, emphasizing consistent patterns and reducing errors.
→ For semantic mask generation, GroundingDINO locates task-related objects using instance-specific prompts. SAM and CLIP then refine segmentation masks, ensuring semantic alignment with the prompts.
→ Masks are iteratively improved and used to weight the original image for subsequent iterations, reducing irrelevant regions' influence.
-----
Key Insights 💡:
→ Changes in VLM outputs when key image features are masked can effectively indicate the correctness of instance-specific prompts.
→ Progressive negative mining refines instance-specific prompts by iteratively reducing the impact of incorrect category predictions and reinforcing correct ones.
→ Iterative cycles of prompt and mask generation significantly enhance the quality of both prompts and segmentation masks.
-----
Results 📊:
→ On Camouflaged Object Detection (COD) tasks, INT outperforms other methods. For example, on the CHAMELEON dataset, INT achieves a Mean Absolute Error (M) of 0.039, adaptive F-measure (F-beta) of 0.801, mean E-measure (E-phi) of 0.906, and structure measure (S-alpha) of 0.842.
→ On Medical Image Segmentation (MIS) tasks, INT shows superior performance. For instance, on the CVC-ColonDB polyp dataset, INT achieves an M of 0.172, F-beta of 0.250, E-phi of 0.589, and S-alpha of 0.537.
→ Ablation studies confirm the effectiveness of each module within INT, including hallucination-driven candidate generation, prompt selection with negative mining, progressive negative mining, and semantic mask generation.