Is Semantic Chunking Worth the Computational Cost?
Simple chunking strategies outperform sophisticated semantic chunking methods for RAG, as per this paper.


Simple chunking strategies outperform sophisticated semantic chunking methods for RAG, as per this paper,
Original Problem 🤔:
RAG systems commonly use semantic chunking to split documents into coherent segments, aiming to improve retrieval performance. However, there's no systematic evidence that semantic chunking's benefits justify its computational overhead compared to simpler fixed-size chunking.
Solution in this Paper 🛠️:
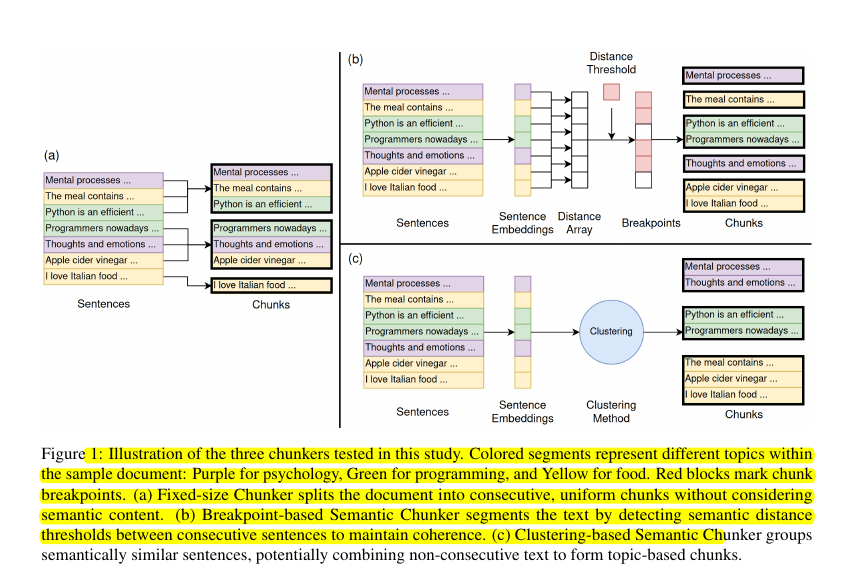
• Evaluated three chunking strategies:
Fixed-size: Splits documents into uniform chunks with predefined size
Breakpoint-based Semantic: Inserts breaks when semantic distance between consecutive sentences exceeds threshold
Clustering-based Semantic: Groups sentences using clustering algorithms based on semantic similarity
• Used three proxy tasks for evaluation: document retrieval, evidence retrieval, answer generation
• Tested on multiple datasets using different embedding models
Key Insights 💡:
• Semantic chunking benefits are highly context-dependent and inconsistent
• Fixed-size chunking performs better on real-world documents
• Embedding model quality impacts performance more than chunking strategy
• Single overlapping sentence doesn't significantly improve context preservation
• Computational overhead of semantic chunking often outweighs benefits
Results 📊:
• Fixed-size chunker outperformed on 3/5 datasets in evidence retrieval
• Breakpoint-based semantic chunker showed advantages only on artificially stitched documents
• Performance differences between chunking strategies were minimal:
Document Retrieval F1@5: 90.99% (Fixed) vs 89.27% (Breakpoint)
Evidence Retrieval F1@5: 47.11% (Fixed) vs 47.08% (Breakpoint)
🛠️ The 3 different chunking strategies tested
Fixed-size Chunker: Splits documents into uniform chunks with predefined size
Breakpoint-based Semantic Chunker: Inserts breakpoints when semantic distance between consecutive sentences exceeds a threshold
Clustering-based Semantic Chunker: Groups sentences using clustering algorithms based on semantic similarity.