
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
One model that understands and generates images without performance tradeoffs.


One model that understands and generates images without performance tradeoffs.
Integrates rectified flow directly into LLM framework for unified processing.
Autoregressive LLMs + rectified flow together.
Original Problem 🎯:
Current unified multimodal models either rely on complex architectures or suffer from reduced performance compared to specialized models. We need a simpler, more efficient approach that maintains high performance across both understanding and generation tasks.
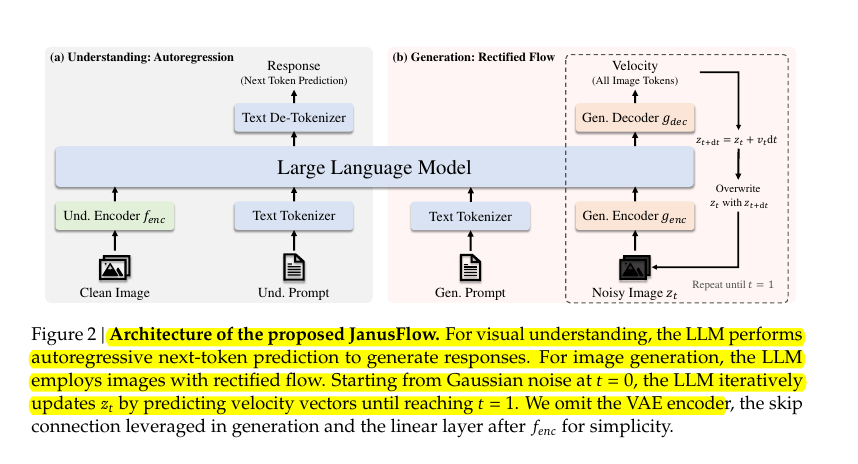
JanusFlow Framework 🛠️:
→ Employs decoupled vision encoders - SigLIP for understanding (300M params) and ConvNeXt for generation (70M params)
→ Uses a 3-stage training: adaptation of new components, unified pre-training, and instruction fine-tuning
→ Implements representation alignment between encoders during training for better semantic coherence
Key Insights 💡:
→ Rectified flow can be integrated into LLMs without complex architectural changes
→ Separate encoders for understanding and generation prevent task interference
→ Simple architectures can match specialized models' performance
→ Representation alignment significantly improves generation quality
Results 📊:
→ Achieves MJHQ FID score of 9.51 and DPG-Bench score of 80.09%
→ Outperforms specialized models with just 1.3B parameters
→ Maintains high performance across both tasks with minimal computational overhead
🌊 Rectified Flow is a simplified approach to generative modeling that offers key advantages over traditional diffusion models:
→ Unlike diffusion models that slowly denoise images through many steps, Rectified Flow learns direct paths between random noise and target images
→ It optimizes a velocity field that points directly toward the data distribution, making generation more efficient
Key Benefits:
→ Faster sampling with fewer steps than diffusion models
→ Simpler training objective - just minimizes distance between predicted and optimal velocities
→ No complex noise scheduling or likelihood calculations needed
→ Better empirical performance despite conceptual simplicity
→ Particularly well-suited for integration with other models (like LLMs in this paper)
Technical Implementation:
→ Uses an ordinary differential equation (ODE) defined over time t ∈ [0,1]
→ Starts with Gaussian noise at t=0 and moves toward real data at t=1
→ Training minimizes Euclidean distance between neural and optimal velocities
→ No reverse process or complex forward/backward mapping required
→ On computational requirements of JanusFlow
The model is relatively lightweight:
Uses a 1.3B parameter LLM base
SigLIP encoder contains ~300M parameters
Generation encoder/decoder total ~70M parameters
Trained on NVIDIA A100 GPUs for ~1,600 GPU days
