JudgeBench: A Benchmark for Evaluating LLM-based Judges
JudgeBench, proposed in this paper, stress-tests AI judges by making them evaluate complex factual responses, exposing their reasoning flaws.


JudgeBench, proposed in this paper, stress-tests AI judges by making them evaluate complex factual responses, exposing their reasoning flaws.
Turns out AI judges need to go back to school, top accuracy is only 64% (Claude-3.5-Sonnet)
Original Problem 🔍:
LLM-based judges are increasingly used to evaluate AI models, but their reliability is rarely scrutinized. Existing benchmarks focus on human preference alignment, neglecting factual and logical correctness in challenging tasks.
Solution in this Paper 🧠:
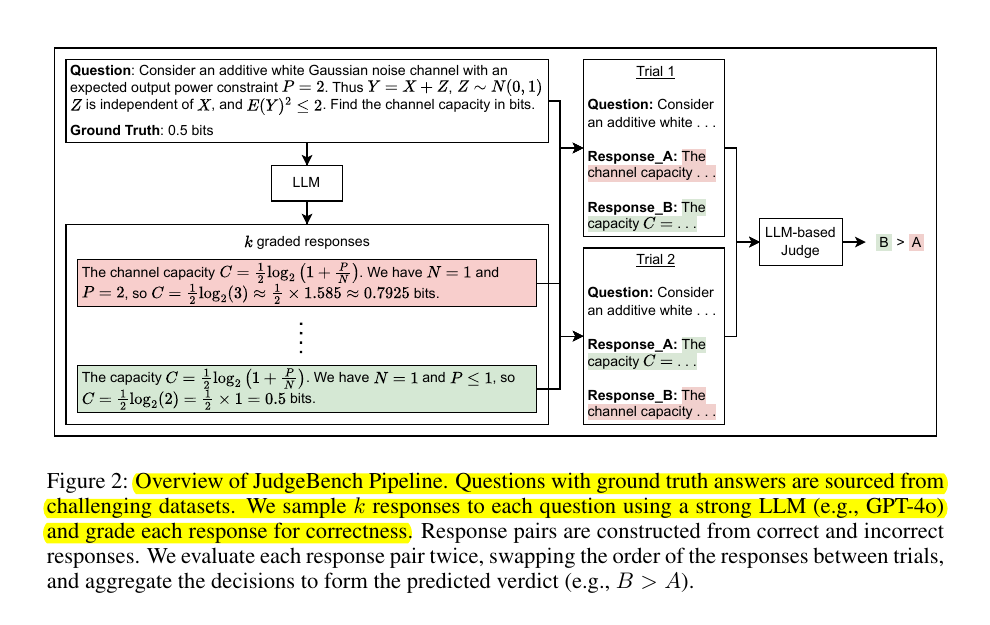
• JudgeBench: A novel benchmark for evaluating LLM-based judges
• Focuses on factual/logical correctness in challenging response pairs
• Pipeline converts datasets with ground truth labels into judge-specific format
• 350 questions across knowledge, reasoning, math, and coding categories
• Evaluates prompted, fine-tuned, and multi-agent judges
Key Insights from this Paper 💡:
• LLM-based judges struggle with challenging tasks, even strong models like GPT-4o
• Fine-tuned judges often perform poorly, sometimes below random guessing
• Larger models generally perform better across providers
• OpenAI's latest models (o1-preview and o1-mini) performed best overall
• Reward models show surprisingly good performance compared to larger LLMs
Results 📊:
• Top accuracy is only 64% (Claude-3.5-Sonnet)
• Strong separability: 31% performance gap between best and worst models
• OpenAI's o1-preview achieves highest overall accuracy: 75.43%
• Fine-tuned judges (except Skywork) perform below random baseline
• Reward models perform on par with much more powerful LLMs
🔬 The advantages of JudgeBench over previous benchmarks
Focuses on factual/logical correctness rather than stylistic preferences
More challenging than previous benchmarks, with lower top scores
Strong separability between best and worst performing models
Provides objective ground truth labels based on correctness
Complements existing benchmarks like RewardBench