
🥉 Landmark research from Google DeepMind achieves 2X faster inference
Google DeepMind doubles inference speed; Zuckerberg lists non-cash lures; Murati’s lab scores $12B; Gemini embeddings top MTEB; AI adoption stats, Scale AI cuts, MLX CUDA, ChatGPT Record Mode.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (16-July-2025):
🥉 Landmark research from Google DeepMind achieves 2X faster inference and ~50% reduced KV cache memory
🧠 Mark Zuckerberg says AI researchers want 2 things apart from money.
💰 Mira Murati’s Thinking Machines Lab is worth $12B in seed round
🛠️ Google just dropped its first Gemini Embedding text model, tops the MTEB Multilingual leaderboard.
📈 Artificial Analysis released the AI Adoption Survey Report for H1 2025
🛠️ Top Resource: 99% of US caselaws are available open sourced on Huggingface
🗞️ Byte-Size Briefs:
Scale AI to cut 14% staff after Meta’s 49% stake reshapes priorities.
MLX, Apple’s machine learning framework, just merged a CUDA Backend.
ChatGPT Record Mode now available to ChatGPT Plus users globally in the macOS desktop app.
🥉 Landmark research from Google DeepMind achieves 2X faster inference and ~50% reduced KV cache memory

GoogleDeepMind dropped a landmark LLM model architecture called Mixture-of-Recursions.
📌 2x faster inference because tokens exit the shared loop early.
📌 During training it cuts the heavy math, dropping attention FLOPs per layer by about half, so the same budget trains on more data.
Shows a fresh way to teach LLMs to plan steps inside their own reasoning loop, instead of hard-coding a single chain.
Second, it proves the mixer idea scales. By jumbling several small recursive experts and letting the model pick which one to call next, the team pushes accuracy on math and coding benchmarks without ballooning parameter count.
Mixture-of-Recursions (MoR) keeps 1 stack of layers in memory, loops it for tough tokens, and still beats a much bigger vanilla model in accuracy and speed .
How its achieving the reduction in Flops and gaining Inference Speed.
A language model breaks input text into tiny pieces called tokens. Most tokens are easy, so they can sail through the network once.
Some tokens are tricky, so they need to pass the same stack of layers a few extra times. That single stack is reused, not duplicated, so overall memory stays light.
A small router looks at each token’s hidden state and gives it a score.
Only the top-scoring tokens keep looping, while the rest exit early. This top-k filter means the model works hardest only on the toughest tokens .
During these loops the model stores key-value pairs just for the tokens that are still active, and it reuses them in later steps. This selective cache slashes memory traffic by about 50% . Because most tokens quit early, total floating-point work falls, inference runs about 2× faster, and accuracy still climbs, even compared with a much larger plain Transformer.
Fewer weights, fewer FLOPs, less memory, yet better perplexity across 135M‑1.7B scales.
🪐 The Big Picture
Scaling Transformers usually means stacking more layers and paying the price in memory and compute. MoR flips that habit. It shares 1 compact block, runs it up to 4 times depending on token difficulty, and skips the loop early when the router says “done”.
🧠 Mark Zuckerberg says AI researchers want 2 things apart from money

Zuckerberg is pouring $15B into gear and real estate so every hire touches more compute than staff paperwork. He has taken a personal role in recruitment.
He says top AI researchers care about 2 things beyond pay, namely minimal managerial burden and maximal access to GPUs.
Candidates ask for the smallest possible teams and the most compute, viewing large GPU clusters as critical for breakthroughs. Hiring is intensifying worldwide.
Nvidia’s H100 chips remain the favored resource, and the ability to provide tens of thousands of them is now a bargaining chip.
Perplexity CEO Aravind Srinivas described a Meta researcher who demanded 10,000 H100s before considering a move. Zuckerberg argues that compute density per researcher is a strategic edge both for research velocity and for attracting further talent.
Meta answers by buying nearly a Manhattan-sized data center and handing out possible $100M bonuses, but the headline lure is still direct access to silicon.
With Alexandr Wang steering Superintelligence Labs, the company now markets itself as a place where an engineer can sit almost alone in front of racks of humming processors, push out papers, and skip bureaucracy. Pay seals the deal, yet the decisive hook is simple: more GPUs per researcher than anywhere else.
💰 Mira Murati’s Thinking Machines Lab is worth $12B in seed round

Andreessen Horowitz wrote the biggest check, joined by Nvidia, Accel, ServiceNow, Cisco, AMD, and Jane Street. The deal marks one of the largest seed rounds — or first funding rounds — in Silicon Valley history, representing the massive investor appetite to back promising new AI labs. Thinking Machines Lab is less than a year old and has yet to reveal what it’s working on.
She also revealed the lab is building multimodal AI that collaborates with users in natural interactions via conversation and sight.
Investor appetite for fresh AI outfits is strong, even while some people wonder about overall tech spending. She also said, that the startup plans to unveil its work in the “next couple months,” and it will include a “significant open source offering.”
Because of that, U.S. startups raised about $162.8 billion in the first half of 2025, a jump of nearly 76%, and AI deals took roughly 64.1% of the total, as per Pitchbook.
With billions in funding, Murati may have enough of a war chest to train frontier AI models. Thinking Machines Lab previously struck a deal with Google Cloud to power its AI models.
🛠️ Google just dropped its first Gemini Embedding text model, tops the MTEB Multilingual leaderboard.

Google’s new Gemini Embedding text model (gemini-embedding-001) is now generally available in the Gemini API and Vertex AI. This versatile model has consistently ranked #1 on the MTEB Multilingual leaderboard since its experimental launch in March, supports over 100 languages, has a 2048 maximum input token length, and is priced at $0.15 per 1M input tokens.
An embedding model turns any text snippet into a vector of fixed length, a string of numeric values. Those values place related ideas close together in the same high-dimensional space.
This new embedding model outperforms earlier Google vectors and rival services across retrieval, clustering, and classification, so search bars and chat memory grab tighter matches with less tweaking.
Thanks to Matryoshka Representation Learning, the native 3072-dimension embedding can drop to 1536 or 768 when disk or latency budgets demand it, without retraining
But, why a 768-dim vector is required at all, when I have 3072-dim vector.??
Large search or chat services juggle millions of vectors. A single 768-dimension float32 vector already weighs about 3 KB, so an index holding 1B of them needs roughly 2.8 TB before replicas enter the picture. Even 100M vectors force about 300 GB of RAM when everything must stay in memory for low-latency lookups. When the dimension rises to 3072, those costs jump 4× because storage grows linearly with vector length.
Matryoshka Representation Learning teaches the model so the first slice of each vector already carries most of the meaning, letting developers keep only 768 or 1536 numbers without a drop in quality. The original research measured up to 14X smaller embeddings with unchanged retrieval accuracy, and later work showed 256-dimension slices beating larger baselines on common benchmarks.
This shrink-on-demand trick pays off quickly. Teams can keep a slim index on fast SSD, run the first nearest-neighbor pass there, then consult the full 3072-dimension vectors only for the handful of finalists, cutting both latency and storage spend. Mobile or edge apps that store chat history locally now fit within GPU memory and push fewer bytes over the network. Cloud databases such as Weaviate and OpenSearch also bill less for smaller vectors while still serving accurate matches, so monthly costs drop alongside RAM footprints. Retrieval-augmented generation pipelines benefit too, because slimmer embeddings free up context tokens for the language model.
Because the same Gemini model produces every slice, no retraining or version juggling is needed; one parameter decides whether storage, speed, or raw precision gets top priority.
You can access the Gemini Embedding model (gemini-embedding-001) via the Gemini API. It’s compatible with the existing embed_content endpoint.

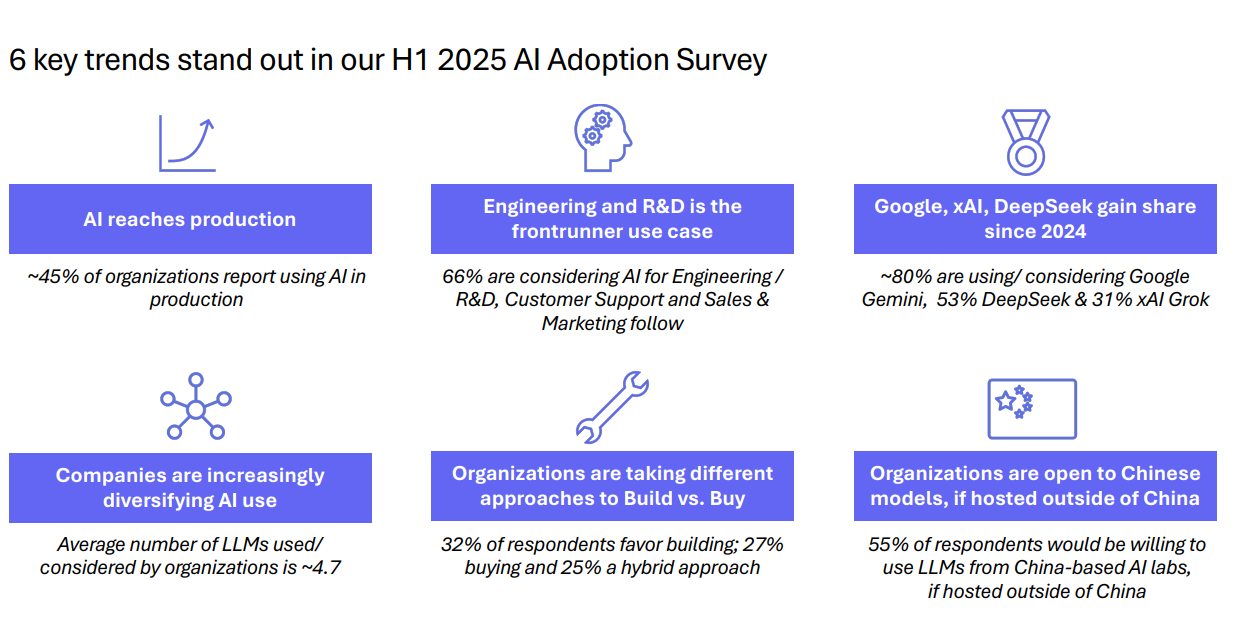
📈 Artificial Analysis released the AI Adoption Survey Report for H1 2025

1)⚡ AI has hit production: ~45% are using AI in production, while an additional 50% are prototyping or exploring uses with AI.
2)💡 Engineering and R&D is the clear frontrunner use case: 66% are considering AI for Engineering/R&D, well ahead of the next most popular use cases in Customer Support and Sales & Marketing
3) 📈 Google, xAI, DeepSeek gain share while Meta and Mistral lose share: ~80% are using/considering Google Gemini, 53% DeepSeek & 31% xAI Grok marking a substantial increase in demand since 2024
4) 🔄 Average number of LLMs used/considered has increased from ~2.8 in 2024 to ~4.7 in 2025, as organizations mature their AI use cases
5) 🏗️ Organizations are taking different approaches to Build vs. Buy: 32% of respondents favor building; 27% buying and 25% a hybrid approach
6) 🇨🇳 55% would be willing to use LLMs from China-based AI labs, if hosted outside of China
The survey was conducted between April and June 2025, collecting responses from 1,000+ individuals across 90+ countries.
GitHub Copilot and Cursor dominate the market as the most popular AI coding tools, ahead of Claude Code and Gemini Code Assist (Note: the survey was conducted before the release of OpenAI Codex)

6 key trends
Models: Over the past year, OpenAI has maintained its lead, Google Gemini and DeepSeek have surged, and Meta Llama and Mistral have fallen.

🛠️ Top Resource: 99% of US caselaws are available open sourced on Huggingface
This dataset contains 6.7 million cases from the Caselaw Access Project and Court Listener.
The Caselaw Access Project consists of nearly 40 million pages of U.S. federal and state court decisions and judges’ opinions from the last 365 years. In addition, Court Listener adds over 900 thousand cases scraped from 479 courts.
The Caselaw Access Project and Court Listener source legal data from a wide variety of resources such as the Harvard Law Library, the Law Library of Congress, and the Supreme Court Database. From these sources, this dataset only included documents that were in the public domain.
Erroneous OCR errors were further corrected after digitization, and additional post-processing was done to fix formatting and parsing.
🗞️ Byte-Size Briefs
💼 Scale AI to cut 14% staff after Meta’s 49% stake reshapes priorities.
Data labeling will now shrink to higher margin niches only. Management now lets 200 full timers go and stops slots for 500 contractors, yet still targets $2B revenue in 2025.
MLX, Apple’s machine learning framework, just merged a CUDA Backend. This does not turn a Mac into a CUDA box; it only lets MLX projects execute on remote or Linux NVIDIA. So you still can NOT run CUDA code on Apple Silicon anytime soon. What you *can* do is run MLX code on CUDA hardware. So now devs can iterate locally, then push the exact script to a multi-GPU farm, trimming upfront hardware spend and avoiding expensive idle clusters.
MLX began as an Apple Silicon first array library with lazy execution and unified memory, letting tensors hop between CPU and integrated GPU without manual copies.The new backend folds matrix multiply, softmax, reductions and tensor copy into direct CUDA kernels, and installing it is a single pip install mlx-cuda command. Anything still missing quietly falls back to the CPU, and the default target is sm_70, so even Pascal era cards work.
ChatGPT Record Mode now available to ChatGPT Plus users globally in the macOS desktop app. It lets you record up to 120 minutes of voice—like meetings, brainstorming sessions, or voice notes—and provides live transcription and a post‑session summary saved as an editable canvas in your chat history.
Just Tap the mic icon in chat, give mic & system‑audio permissions, speak naturally, then stop or pause. ChatGPT creates a transcript and structured summary with highlights, action items, and timestamps.
As of now, Record Mode is not available for Linux, Windows, browsers, or mobile, so here you won't see the mic icon. It only works in the official macOS desktop app.
That’s a wrap for today, see you all tomorrow.