Learning Code Preference via Synthetic Evolution
Small models learn developer preferences by studying how code naturally evolves.


Small models learn developer preferences by studying how code naturally evolves.
CODEFAVOR, proposed in this paper, trains small models to judge code quality like expert developers, but 34x cheaper vs models with 6 ∼ 9× more parameters.
Original Problem 🎯:
Evaluating code generation quality and aligning it with developer preferences remains challenging for LLMs. Current approaches rely on costly human annotations or complex code execution setups.
Solution in this Paper 🛠️:
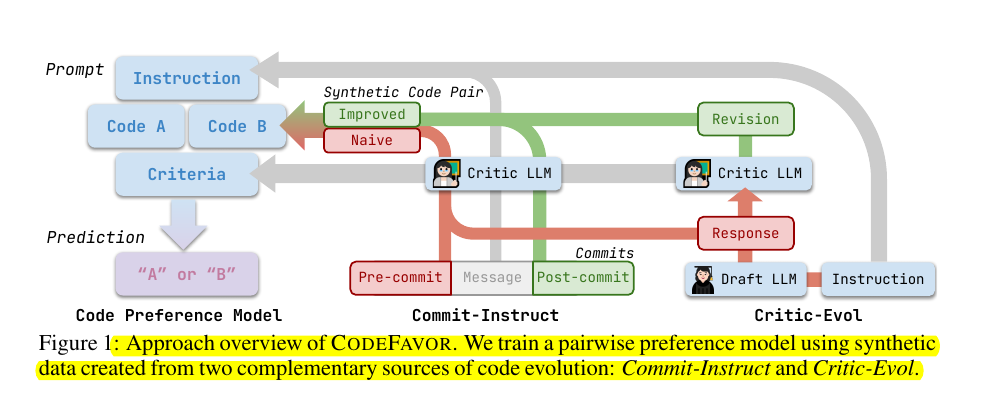
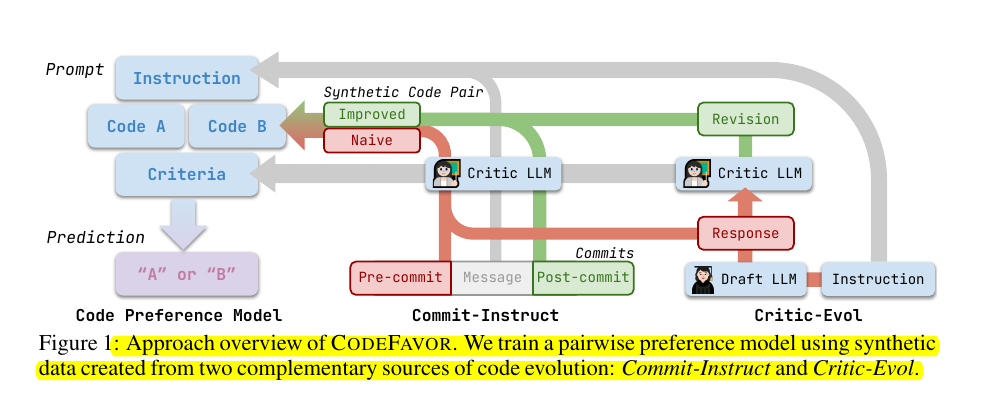
• CODEFAVOR framework trains pairwise code preference models using synthetic evolution data
• Uses two data generation methods:
Commit-Instruct: Transforms pre/post commit code into preference pairs
Critic-Evol: Uses draft LLM to generate initial code and critic LLM to improve it
• Introduces CODEPREFBENCH: 1,364 curated code preference tasks covering correctness, efficiency, security, and developer preferences
Key Insights 💡:
• Human preferences excel at code correctness but underperform for non-functional objectives
• Human annotation is prohibitively expensive: 23.4 person-minutes per task
• 15.1-40.3% tasks remain unsolved despite time investment
• Synthetic evolution data can effectively train code preference models
• Smaller models can match larger ones when trained properly
Results 📊:
• Improves model-based code preference accuracy by 28.8%
• Matches performance of 6-9x larger models
• 34x more cost-effective than baseline approaches
• Human preference accuracy:
Code correctness: 84.9%
Code efficiency: 74.9%
Code security: 59.7%
🛠️ The key components of the proposed CODEFAVOR framework
Uses pairwise modeling to predict preferences between code pairs based on specified criteria
Introduces two synthetic data generation methods:
Commit-Instruct: Transforms pre/post commit code into preference pairs
Critic-Evol: Uses a draft LLM to generate initial code and a critic LLM to improve it