Let the Code LLM Edit Itself When You Edit the Code
One matrix operation replaces full KV cache recomputation in LLMs and lets LLMs update code predictions 85% faster.


One matrix operation replaces full KV cache recomputation in LLMs and lets LLMs update code predictions 85% faster.
Positional Integrity Encoding (PIE) rewrites how LLMs handle code edits by fixing token positions without full recalculation
Original Problem 🎯:
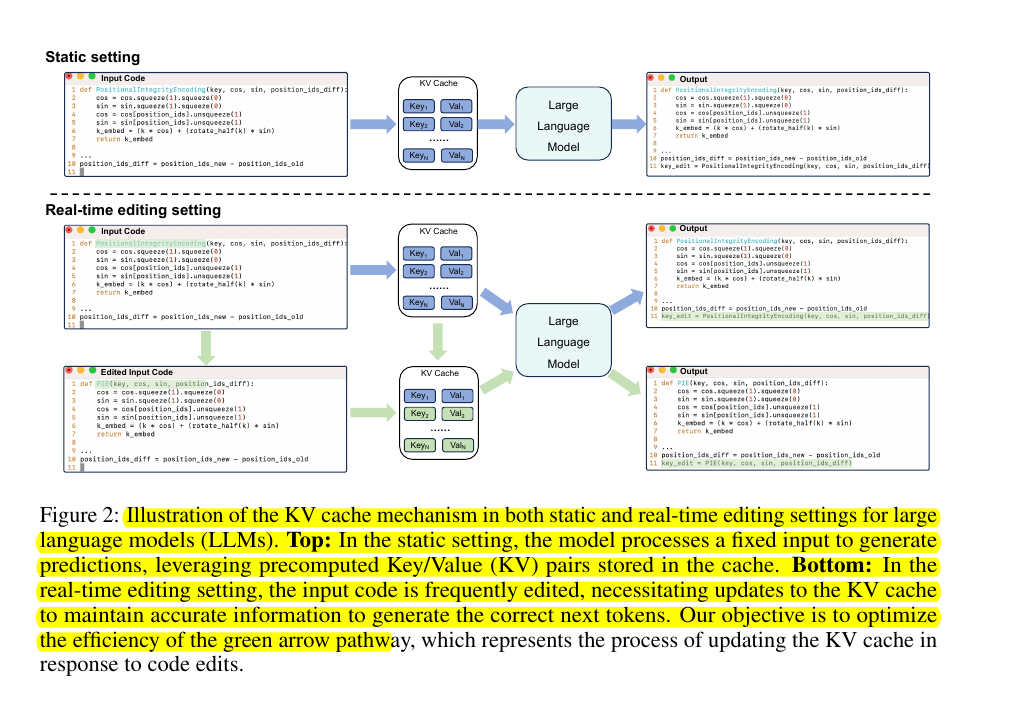
LLMs need to re-encode entire Key-Value (KV) cache after each code edit, causing high latency in real-time coding scenarios. Simply encoding edited subsequence leads to temporal confusion and poor performance.
Solution in this Paper 🔧:
• Introduces Positional Integrity Encoding (PIE) built on rotary positional encoding
• Removes rotary matrices in Key cache causing temporal confusion
• Reapplies correct rotary matrices through single matrix multiplication
• Maintains positional relationships between tokens
• Requires only one round of matrix operations to modify KV cache
Key Insights from this Paper 💡:
• Temporal confusion is more critical than semantic impact in code editing
• PIE can be seamlessly integrated with other optimization techniques
• Works effectively across different model sizes and code editing tasks
• Particularly effective for long sequence scenarios
Results 📊:
• Reduces computational overhead by over 85% vs full recomputation
• Tested on DeepSeek-Coder models (1.3B, 6.7B, 33B parameters)
• Maintains performance comparable to full recomputation
• Evaluated on RepoBench-C-8k dataset for code insertion, deletion, and multi-place editing
• Achieves cosine similarity near 1.0 with full recomputation across all layers
💡 PIE offers significant benefits:
Reduces computational overhead by over 85% compared to full recomputation
Maintains prediction accuracy comparable to full recomputation
Requires only a single round of matrix operations to modify KV cache
Works effectively across different model sizes and code editing tasks.