
Lightweight Neural App Control
LiMAC proposed in this paper, performs mobile app tasks in 3 seconds by combining small transformers with selective VLM usage


LiMAC proposed in this paper, performs mobile app tasks in 3 seconds by combining small transformers with selective VLM usage
Original Problem 🎯:
Mobile app control agents using LLMs face significant challenges - they're computationally heavy, expensive to run, and impractical for everyday smartphone use. Current solutions using GPT-4 take 1-2 minutes per task and cost ~$1.00 per execution.
Solution in this Paper 🛠️:
• Introduces LiMAC (Lightweight Multi-modal App Control) framework combining:
Small Action Transformer (AcT) (~500M parameters) for basic actions
Fine-tuned Vision Language Model (VLM) for text-based tasks
• Uses contrastive learning for UI element targeting
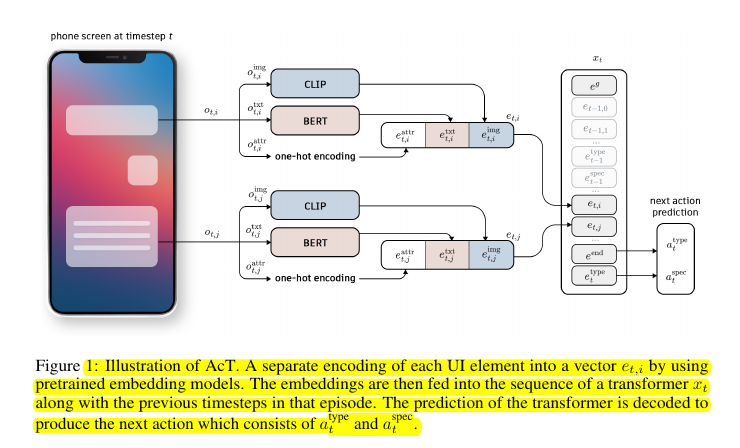
• Processes UI elements through specialized encoders:
CLIP for visual features
BERT for textual content
Custom encoder for UI attributes
• Implements gated architecture - only invokes VLM when needed for text generation
Key Insights from this Paper 💡:
• Hybrid approach reduces computational demands while maintaining high accuracy
• Specialized modules for different action types improve efficiency
• Contrastive learning effectively handles variable UI elements
• Visual information proves more crucial than textual UI data
• Fine-tuned CLIP significantly improves performance
Results 📊:
• 30x faster execution (3 seconds per task) compared to GPT-4 based solutions
• 19% higher accuracy vs fine-tuned VLMs
• 42% improvement over prompt-engineering baselines
• Superior action-type prediction (86.9% on AitW, 82.3% on AndroidControl)
• Maintains performance even with imprecise UI trees
🛠️ Key technical components of LiMAC
The system uses:
Action Transformer (AcT) for predicting action types and UI element interactions
Fine-tuned VLM for handling text-based actions
Contrastive objective for click prediction
Specialized encoding for UI elements using both visual and textual information
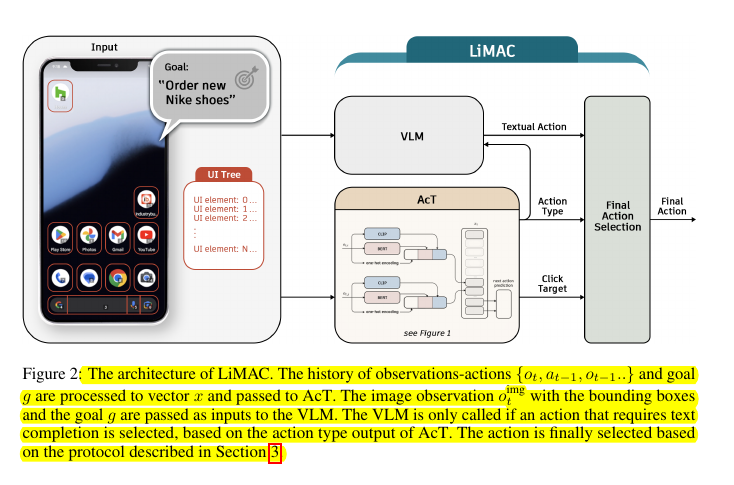
🔍 LiMAC uses a gated architecture, to achieve computational efficiency, where most actions are handled by a compact model (~500M parameters).
For actions requiring natural language understanding, it invokes a fine-tuned VLM.
This hybrid approach reduces computational demands and improves responsiveness - 30x faster execution, down to 3 seconds per task.