LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
LiveXiv catches models trying to cheat on their scientific tests, using scientific papers.


LiveXiv catches models trying to cheat on their scientific tests, using scientific papers.
Its the benchmark where models can't memorize their way through science class
Original Problem 🔍:
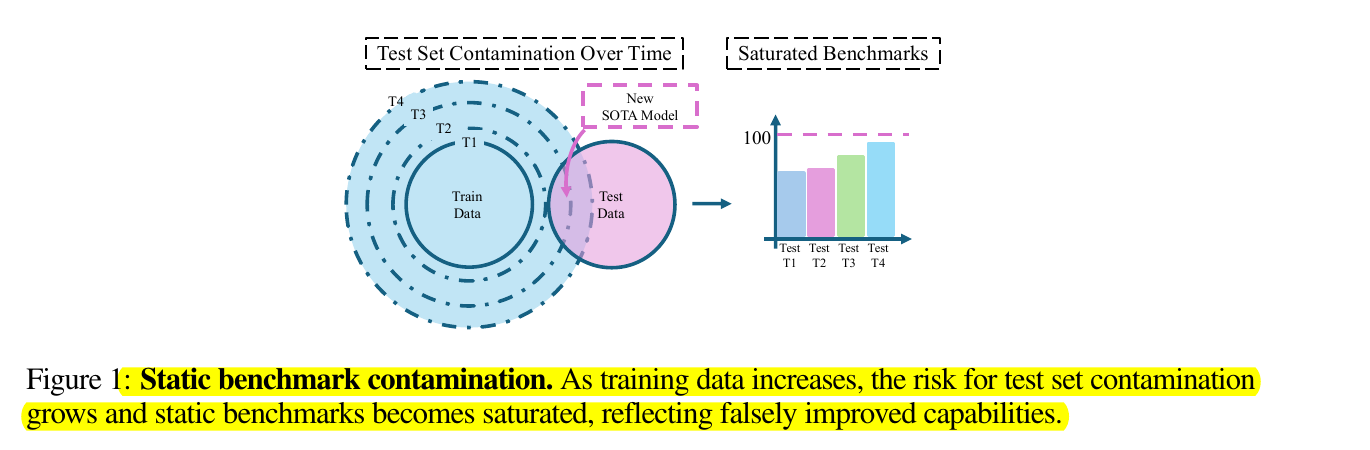
LiveXiv addresses test set contamination in evaluating large multi-modal models (LMMs) and provides a contamination-free perspective on LMM rankings.
Solution in this Paper 🛠️:
• Automated multi-modal live benchmark based on ArXiv papers
• Generates visual question-answer pairs from scientific papers without human involvement
• Uses structured document parsing and GPT-4o for question generation
• Extensive filtering with Claude to reduce errors and ensure multi-modality
• Efficient evaluation method using Item Response Theory (IRT) to reduce computational costs
Key Insights from this Paper 💡:
• LiveXiv reveals potential data contamination effects on LMM performance
• Newer models consistently outperform older ones across diverse scientific domains
• Some models exhibit higher robustness across domains, while others are more sensitive
• Efficient evaluation method reduces needed evaluations by 70%
Results 📊:
• Claude-Sonnet outperforms other models: 75.4% VQA, 83.5% TQA accuracy
• GPT-4o drops 1.67 points in average ranking compared to static benchmarks
• Performance fluctuates by only 2.3% (VQA) and 2.1% (TQA) between full dataset and manually verified subset
• Re-evaluating 5 out of 17 models accurately predicts performance on new data versions
🤖 The way LiveXiv generates questions and answers
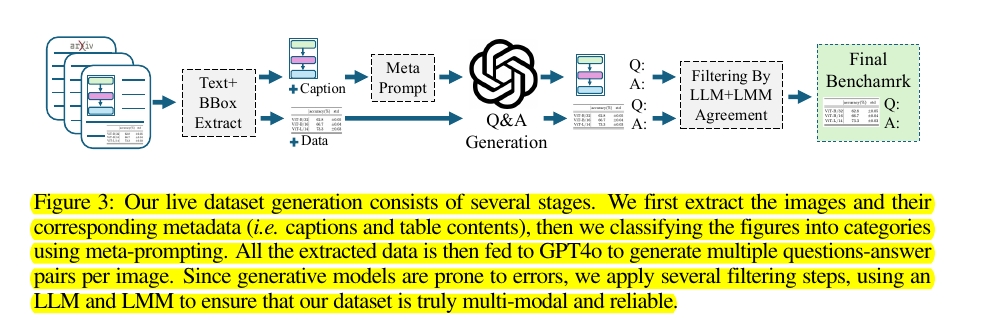
LiveXiv scrapes category-specific manuscripts from arXiv and uses a structured document parsing pipeline to extract relevant information like figures, charts, tables, and captions. This information is fed to GPT-4o to generate visual questions and answers.
The generated QA pairs then go through extensive filtering stages using another LMM (Claude) to reduce errors and ensure the questions are truly multi-modal.
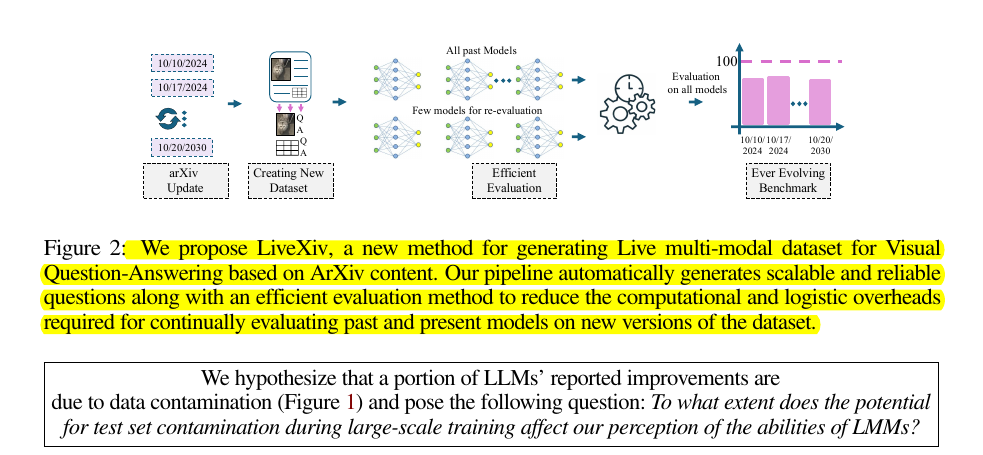
🔄 LiveXiv is designed as a live benchmark that can be continuously updated with new data from recent arXiv papers.
To handle the computational challenge of re-evaluating all models on each new version, the researchers propose an efficient evaluation method based on Item Response Theory (IRT).
This method allows estimating the performance of older models on new data by re-evaluating only a small subset of models, reducing the overall needed evaluations by about 70%.