
LlamaV-o1 Is Released: Rethinking Step-by-step Visual Reasoning in LLMs
LlamaV-o1 rethinks visual reasoning, SakanaAILabs unveils self-adaptive LLMs, Dria-Agent-α optimizes GPT-4o efficiency, plus new TTS models, HuggingFace course
Read time: 8 min 24 seconds
⚡In today’s Edition (15-Jan-2025):
🧠 LlamaV-o1 Is Released: Rethinking Step-by-step Visual Reasoning in LLMs
🐙 SakanaAILabs shows the power of an LLM that can self-adapt its weights to its environment, releases Transformer²: Self-adaptive LLMs
📡OuteTTS 0.3: New 1B & 500M TTS Models - - Improved naturalness and coherence of speech with punctuation support
🛠️ Dria-Agent-α - showcases Python-first tool handling achieves GPT-4o-level performance with fewer resources
MiniCPM-o 2.6: a powerful 8B parameter multimodal AI that brings GPT-4o-level performance to your PHONE
🗞️ Byte-Size Brief:
HuggingFace launches free AI Agents course covering design, build, deploy workflows.
Vellum report: Only 25% enterprises deploy AI in production.
MicroDiTs enables diffusion model training with 8 GPUs for $2,000.
🧠 LlamaV-o1 Is Released: Rethinking Step-by-step Visual Reasoning in LLMs

🎯 The Brief
LlamaV-o1 project is released, an AI model designed for step-by-step reasoning in multimodal tasks. Introduces a comprehensive framework to enhance visual reasoning in Large Language Models (LLMs) through three key contributions
Visual Reasoning Benchmark
Evaluation strategy
A bad-ass open source model
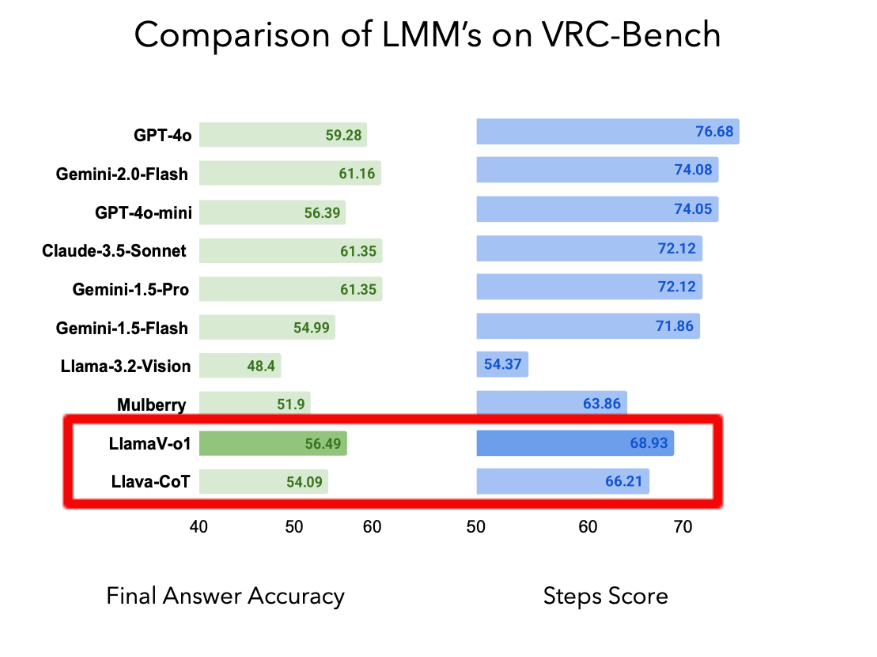
LlamaV-o1 surpasses competitors like Claude 3.5 Sonnet and Llava-CoT by achieving a reasoning step score of 68.93 and running 5x faster during inference. This release is accompanied by VRC-Bench, a benchmark that evaluates models based on reasoning steps rather than just final answers, marking a significant shift in assessing AI interpretability and logical flow.
⚙️ The Details
→ LlamaV-o1 excels at solving complex tasks by employing Beam Search for multiple reasoning paths and curriculum learning to build reasoning skills incrementally.
→ Evaluated across benchmarks like MathVista and AI2D, it achieved an average score of 67.33%, outperforming both open-source models like Llava-CoT (63.5%) and competing closely with GPT-4o's 71.8%.
→ VRC-Bench includes over 1,000 samples and evaluates over 4,000 reasoning steps across categories like medical imaging, scientific reasoning, and chart comprehension.
→ The model’s step-by-step approach improves interpretability, particularly in fields like finance, healthcare, and education, where decision transparency is critical.
→ LlamaV-o1’s code and benchmarks are publicly available, fostering openness for future development.
🐙 SakanaAILabs shows the power of an LLM that can self-adapt its weights to its environment, releases Transformer²: Self-adaptive LLMs

🎯 The Brief
Sakana AI introduced Transformer², an adaptive LLM framework that dynamically adjusts its weights during inference. i.e. it elevates transformers allowing them to learn at test time. This model improves efficiency and outperforms static fine-tuning methods like LoRA by using Singular Value Fine-tuning (SVF), which reduces computational demands while retaining high task performance. Its adaptability across tasks, including math, coding, and visual reasoning, marks a leap in self-organizing AI systems.
⚙️ The Details
→ Transformer² operates in two stages: first, it analyzes task attributes, and then it applies expert vectors fine-tuned via reinforcement learning to optimize performance for specific tasks.
→ The Singular Value Fine-tuning (SVF) method fine-tunes LLMs by adjusting the singular values of weight matrices, minimizing parameter use while avoiding overfitting.
→ Three adaptive strategies during inference—prompt-based, classifier-based, and few-shot adaptation—allow task-specific adjustment of weights in real-time.
→ Experiments show that SVF outperformed LoRA on tasks like GSM8K and HumanEval. Few-shot learning even combines multiple z-vectors for complex tasks, such as combining math and reasoning vectors for better MATH dataset performance.
→ Cross-model testing demonstrated that expert vectors trained on one LLM (e.g., Llama3) improved performance when transferred to another (e.g., Mistral), indicating cross-model compatibility.
Adaptation is a remarkable natural phenomenon, like how the octopus can blend in with its environment, or how the brain rewires itself after injury. We believe our new system paves the way for a new generation of adaptive AI models, modifying their own weights and architecture to adapt to the nature of the tasks they encounter, embodying living intelligence capable of continuous change and lifelong learning.
📡OuteTTS 0.3: New 1B & 500M TTS Models - - Improved naturalness and coherence of speech with punctuation support
🎯 The Brief
OuteAI released OuteTTS 0.3, featuring new 1B and 500M models with significant advancements in multilingual text-to-speech (TTS) and speech-to-speech generation. The 1B model supports six languages and incorporates punctuation-aware controls to improve speech naturalness and flow. This upgrade enhances voice cloning and introduces 30-second batch optimizations for better performance.
⚙️ The Details
→ The 1B model is built on OLMo-1B and trained on 20,000 hours of speech, covering 8 billion tokens, while the 500M model uses Qwen2.5-0.5B with 10,000 hours (~4 billion tokens).
→ Supported languages include English, Japanese, Korean, Chinese, French, and German.
→ Punctuation marks like ., !, ?, and more are converted into special tokens to control speech tone and clarity.
→ Training datasets include Emilia, Mozilla Common Voice, MLS, and other open datasets.
→ Experimental voice cloning features allow speaker profile customization, though results may vary.
→ The 500M model uses CC-BY-SA 4.0, while the 1B model uses CC-BY-NC-SA 4.0 due to proprietary dataset usage.
→ OuteTTS preserves LLM compatibility, making it easy to integrate into existing workflows.
→ The 500M model uses CC-BY-SA 4.0 (permissive), while the 1B model follows CC-BY-NC-SA 4.0 due to the inclusion of the proprietary Emilia dataset for enhanced speech quality. CC-BY-SA 4.0 is a permissive license allowing sharing, adaptation, and commercial use, provided attribution is given, and derivative works are licensed under the same terms (ShareAlike).
🛠️ Dria-Agent-α - showcases Python-first tool handling achieves GPT-4o-level performance with fewer resources

🎯 The Brief
Dria released Dria-Agent-α, an LLM using Pythonic function calling instead of JSON schemas to enhance tool-based interactions. This framework enables multi-step reasoning in a single call. Trained on synthetic data from 2000 edge devices, it features the 3B and 7B parameter models that match or exceed GPT-4o in BFCL benchmarks with efficient performance in agentic tasks.
BFCL (Benchmark for Few-shot Complex Logic) measures an LLM's ability to handle complex, multi-step reasoning tasks with minimal examples, evaluating its proficiency in multi-tool usage and logical consistency.
⚙️ The Details
→ Dria-Agent-α is special because it replaces JSON-based calls with Pythonic function calling, enabling multi-step reasoning in a single step. It excels at handling real-world tool workflows efficiently, supports robust state tracking, and was trained on synthetic data from 2000 edge devices for strong out-of-distribution performance.
→ Pythonic function calling allows models to execute actions directly through Python code, supporting state tracking, variable management, and error outputs in structured form.
→ The synthetic training data included real-world scenarios like developer tool usage and was generated using mock functions, user queries, and execution-based validation.
→ Validation methods combined in-context learning, process reward models, and execution feedback loops, ensuring a checklist score above 0.75 for accepted entries.
→ The Dria-Agent-α-3B model performs comparably to GPT-4o in benchmark tasks while being more compact, with a 7B version excelling at solving complex multi-tool problems.
→ Future iterations like Dria-Agent-β aim to refine reasoning capabilities using methods such as RLEF and rStar-Math.
Read the detailed blog in Huggingface.
MiniCPM-o 2.6: a powerful 8B parameter multimodal AI that brings GPT-4o-level performance to your PHONE

🎯 The Brief
OpenBMB released MiniCPM-o 2.6, an 8B parameter multimodal LLM designed for vision, speech, and real-time streaming tasks, delivering GPT-4o-level performance. This model excels in live-streaming benchmarks, bilingual speech processing, and has 75% lower token density, enabling efficient performance on devices like iPads.
⚙️ The Details
→ MiniCPM-o 2.6's standout feature is real-time multimodal streaming with 75% lower token density, enabling efficient performance across vision, speech, and continuous audio-video tasks even on mobile devices.
→ MiniCPM-o 2.6 is built using SigLip-400M, Whisper-medium-300M, ChatTTS-200M, and Qwen2.5-7B, featuring end-to-end multimodal architecture with 8B parameters.
→ It achieves an OpenCompass score of 70.2 and outperforms GPT-4V and Claude 3.5 Sonnet in multi-image, video, and OCR tasks, processing images with up to 1.8 million pixels.
→ Speech capabilities include bilingual real-time speech conversation with voice cloning, emotion control, and style customization. It surpasses proprietary models in ASR and STT tasks.
→ For real-time streaming, it processes continuous video and audio streams and leads on StreamingBench with low-latency performance.
→ The model supports int4 quantization and runs efficiently using llama.cpp on CPUs, with local Gradio demos available. It’s free for academic use and requires registration for commercial licensing.
→ MiniCPM-o 2.6 is released under Apache-2.0 for code and a MiniCPM Model Community License for weights. It’s free for academic research and commercial use after registration, with restrictions on military, false information, harassment, and privacy violations. Redistribution requires attribution and compliance with legal regulations.
🗞️ Byte-Size Brief
HuggingFace launched a free certified AI Agents course that teaches how to design, build, and deploy agents using top libraries and frameworks.
Only 25% of enterprises have AI in production - according to a new State of AI Development Report from AI development platform Vellum. Companies are in various stages of their AI journeys — building out and evaluating strategies and proofs of concept (PoC) (53%), beta testing (14%) and, at the lowest level, talking to users and gathering requirements (7.9%).
Now you can do Diffusion Training from Scratch on a Micro-Budget, for less than $2,000. Meet MicroDiTs—train from scratch using just 8 GPUs in 2.5 days. The minimal implementation uses 37M real/synthetic images, patch masking for speed-up, and reproducible pre-trained checkpoints for off-the-shelf generation. They have fully released the official training code, data code, and model checkpoints.