
LLM Evaluations and Strategies to Reduce Evaluation Costs (RunPod, Evaluation Harness and Hugging Face TGI/vLLM)


Large Language Models (LLMs) always need tobe assessed for their fundamental capabilities—like instruction following, reasoning, and mathematical prowess—using benchmarks like IFEval and GSM8K. Though these benchmarks might not perfectly represent every real-world application, they nonetheless offer a valuable snapshot of a model’s relative strengths and weaknesses.
However, conducting thorough evaluations LLMs can be both time-consuming and computationally demanding, especially for larger models. This is where optimized serving solutions like Hugging Face’s Text Generation Inference (TGI) and vLLM come in. Employing these tools not only speeds up the evaluation process but also helps ensure the models’ accuracy and reliability in near-production environments.
I will conduct a real-time evaluation of a 1.5B-parameter and a 32B-parameter model on RunPod using popular benchmarks, such as MMLU and GPQA. If real-time evaluation proves infeasible (due to extended compute time), I will provide cost estimates based on RunPod pricing and expected token throughput. Afterward, I will analyze strategies to significantly reduce evaluation costs while maintaining credibility. I will also provide short guidelines for reporting evaluation results in scientific papers and technical reports to ensure reproducibility and integrity.
Finally, I will demonstrate how to evaluate LLMs using Evaluation Harness with Hugging Face’s Text Generation Inference (TGI) or vLLM (via OpenAI-compatible API endpoints). This approach can further optimize throughput and validation speed when running benchmarks.
1. Overview of Costs for Evaluating 1.5B vs 32B Models on RunPod
RunPod offers on-demand cloud GPUs at variable hourly rates (community or dedicated). We focus here on the typical GPUs needed to run a 1.5B or 32B parameter model.
1.5B-Parameter Model (e.g., GPT-2 XL)
Hardware: A single Tesla V100 16 GB (≈$0.19/hour on the RunPod community tier).
Throughput: A smaller model can process a few hundred tokens/s.
Benchmarks:
MMLU (~1,540 questions; possibly ~1M tokens total) might take 1–2 hours, costing under $1.
GPQA (~448 questions) would be ~⅓ the size/cost, only a few cents.
Token Cost: Roughly $0.01–$0.02 per million tokens processed on such hardware configurations—very affordable for a 1.5B model.
32B-Parameter Model (e.g., LLaMA-30B)
Hardware: A more powerful NVIDIA A100 80GB (≈$1.19/hour on RunPod community tier) to load a 32B model in FP16.
Throughput: Tens of tokens/s, so MMLU’s ~1M tokens might take ~5–8 hours.
Benchmarks:
MMLU could cost $5–$10 in GPU time.
GPQA is shorter (~0.5–1 hour, ~$1).
Comparison: Still cheaper than some commercial APIs, where large-scale model inference might cost tens of dollars per million tokens. On self-hosted hardware, total cost might be ~$0.30 per million tokens.
Real-Time vs. Offline
Real-Time: Running a 32B model in an interactive manner (synchronously reading queries) is often not practical.
Offline: Commonly, evaluations are done in batch mode. The above estimates assume single-GPU usage for the entire evaluation, multiplied by the GPU hourly rate.
In short:
1.5B model: MMLU eval ≈<$1≈<$1, GPQA eval ≪$1≪$1.
32B model: MMLU eval ≈$5–$10≈$5–$10, GPQA eval ≈$1≈$1.
These costs are not large for a single run, but they can accumulate with repeated experiments or larger benchmarks.
2. Strategies to Reduce Evaluation Costs
Even “modest” GPU charges can stack up if you iterate frequently. Below are proven cost-optimization strategies:
Use Optimized Inference Engines (vLLM, TGI)
vLLM and Hugging Face Text Generation Inference (TGI) both provide high-efficiency model serving.
vLLM uses “PagedAttention” and continuous batching to achieve up to 24× higher throughput.
TGI (Text Generation Inference) is an optimized solution from Hugging Face that scales to large models efficiently, with built-in features like tensor parallelism, multi-GPU sharding, and advanced queuing.
These optimizations do not change the model’s outputs—only speed up generation, saving money by reducing total GPU hours.
Minimize Prompt Tokens (Zero-Shot or Few-Shot Efficiency)
Zero-shot prompting often uses fewer tokens than few-shot (which includes examples). Fewer tokens = less compute per query.
If few-shot is needed, consider a “static prompt” approach (reuse the same prefix) and use caching (see below).
Deterministic Decoding for Single-Pass Answers
Use
temperature=0(greedy or beam search) to get a single stable answer.Avoid multiple sampling runs if your benchmark does not require it. This ensures reproducibility and cuts compute time.
Quantize the Model
Converting weights to 8-bit or 4-bit can drastically reduce GPU memory usage.
A 32B model might fit on a cheaper GPU if quantized from FP16 to 4-bit.
Modern methods (e.g., GPTQ, BitsAndBytes) largely preserve accuracy while providing significant speedups or allowing smaller hardware usage.
Leverage Caching (Prompt or Result)
Prompt caching: Store the key/value hidden states for repeated tokens across questions. Great for few-shot templates or repeated instructions.
Result caching: If re-running the exact same model on the exact same benchmark, store final outputs. No need to re-infer if nothing changed.
Combining these (e.g., quantization + vLLM + deterministic decoding) can yield massive cost savings with minimal (or zero) drop in benchmark scores.
3. Evaluating LLMs Using Evaluation Harness and Hugging Face TGI or vLLM
To further streamline the process—especially for multiple tasks or chain-of-thought prompts—you can serve your model behind an OpenAI-compatible API using either TGI or vLLM. Then, harness the EleutherAI Evaluation Harness (lm_eval) to run standard benchmarks (e.g., MMLU, GPQA, IFEval, GSM8K, etc.). Below is a high-level example demonstrating TGI usage with the harness.
3.1 Running Your Model with TGI
Text Generation Inference (TGI) is available via Docker images. For example, to serve a model named "meta-llama/Meta-Llama-3.1-8B-Instruct" on a machine with an NVIDIA GPU:
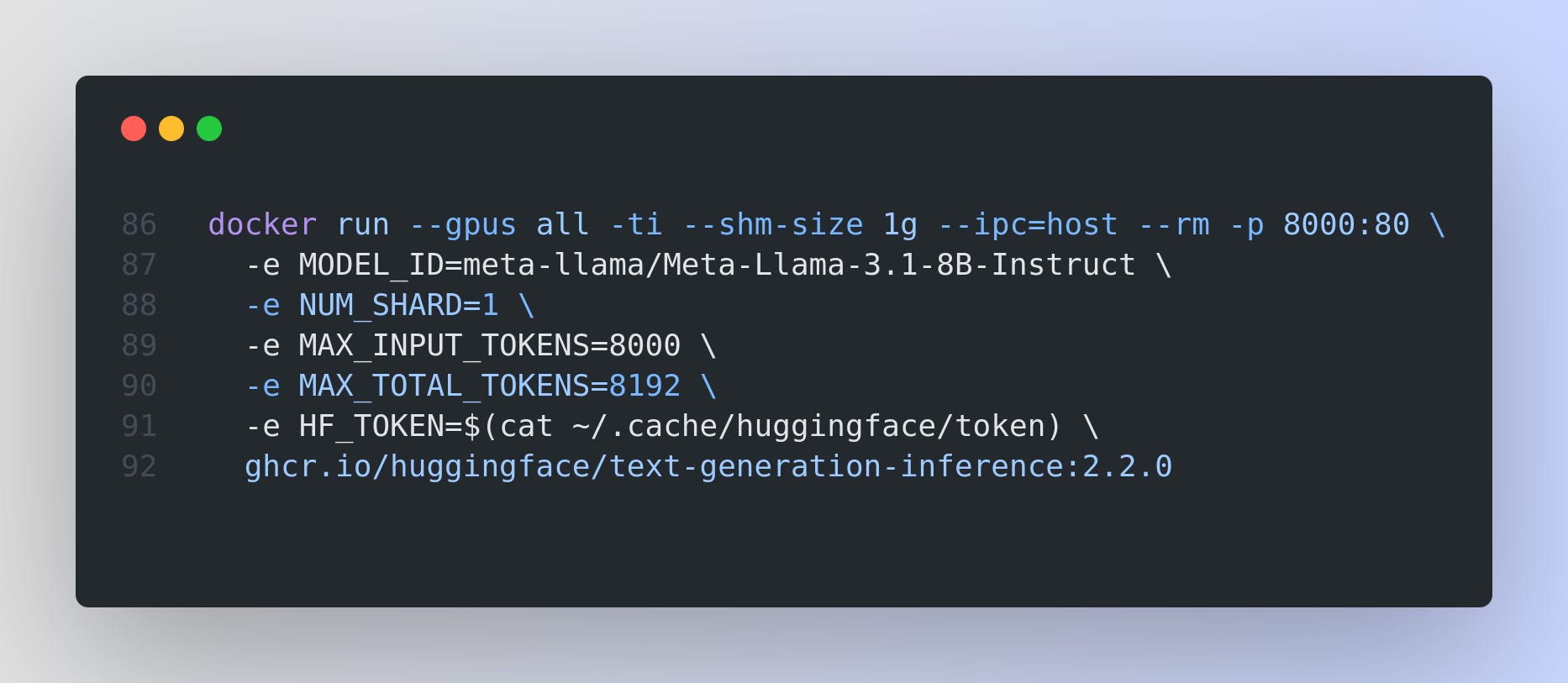
You can adjust environment variables like NUM_SHARD (for multi-GPU usage) or MAX_INPUT_TOKENS (depending on GPU memory). Now your model is accessible at http://localhost:8000/v1/chat/completions via an OpenAI-style API.
Alternatively, you can run vLLM with a similar OpenAI-like endpoint.
3.2 Evaluating via lm_eval CLI
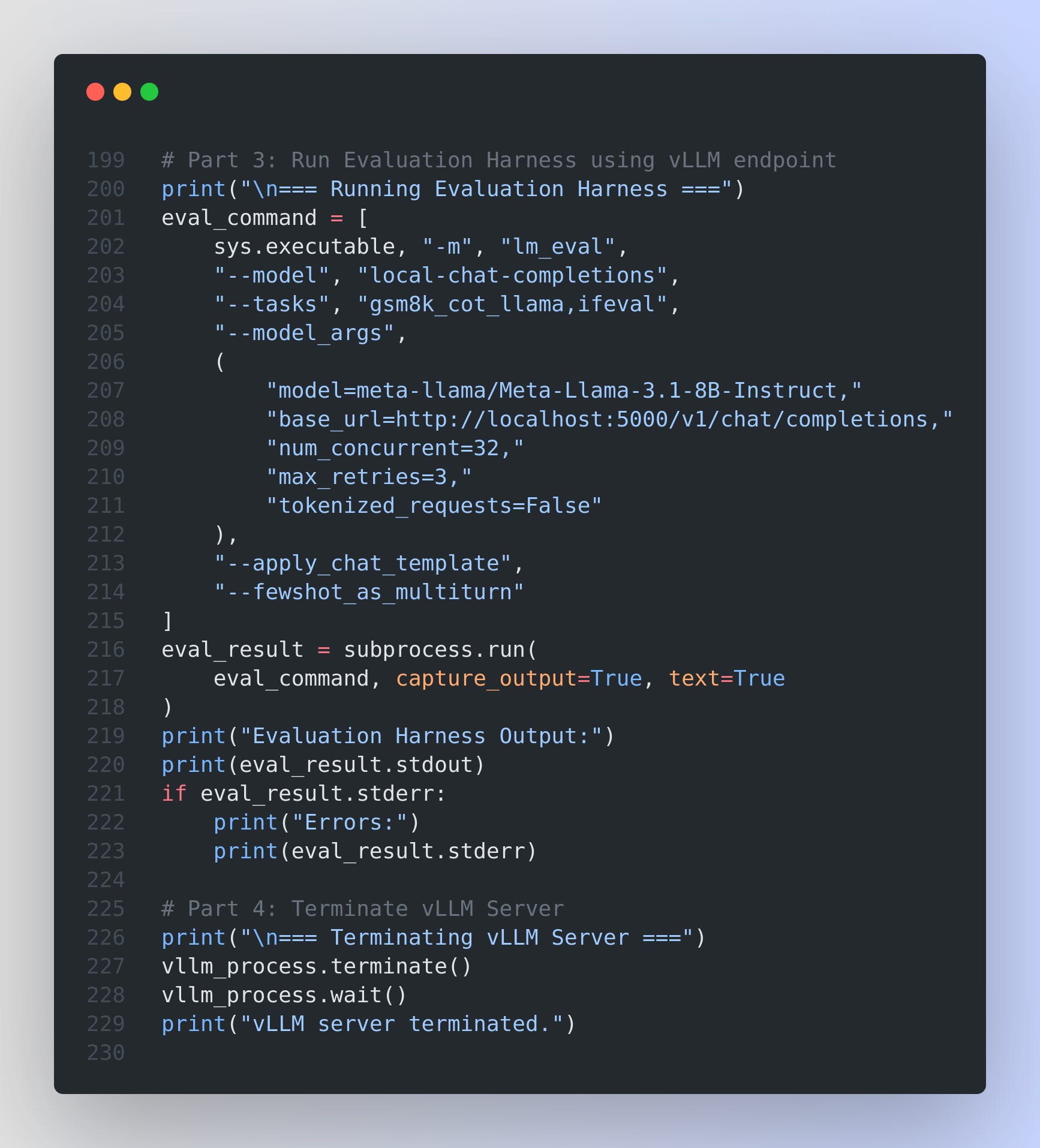
The Evaluation Harness provides a CLI tool to run tasks like MMLU, GPQA, IFEval, GSM8K, and more. To evaluate a chat-based (OpenAI-compatible) endpoint, you can use:
pip install "lm_eval[ifeval]==0.4.4" # For example, includes the IFEval taskThen invoke the harness:

Key arguments:
--model local-chat-completionsUses the harness’s local chat completions interface, suitable for an OpenAI-like chat API.--tasks gsm8k_cot_llama,ifevalA comma-separated list of tasks; MMLU and GPQA can also be specified similarly (e.g.,mmlu, gpqa).--model_argsmodel: The model ID (used primarily for tokenization and metadata).base_url: Points to your TGI or vLLM endpoint (http://.../v1/chat/completions).num_concurrent: Number of parallel requests (for speed).max_retries: Retries on request failure.tokenized_requests=False: For chat-completion models, we skip direct log-likelihood queries.
--apply_chat_templateEnsures prompts are formatted as chat messages.--fewshot_as_multiturnIf few-shot examples are used, treat them as multiple message turns.
This harness approach gives you:
Automated setup for many standard tasks (MMLU, GSM8K, etc.).
Chain-of-thought capabilities (e.g.,
_cot_tasks).Reproducible, easily shareable results.
If you ran this on, say, a RunPod instance hosting TGI with a single A100 GPU, you’d be able to measure how quickly (and cheaply) you can complete the entire test suite for your chosen LLM. The harness also simplifies comparing results across multiple models.
4. Example of (Local) Cost-Efficient Evaluation in Python
Below is a complete Python script that demonstrates everything from running local inference with Hugging Face Transformers to evaluating the model using vLLM with the EleutherAI Evaluation Harness. You can run this script as a whole (assuming the required packages, vLLM, and lm‑eval are installed):
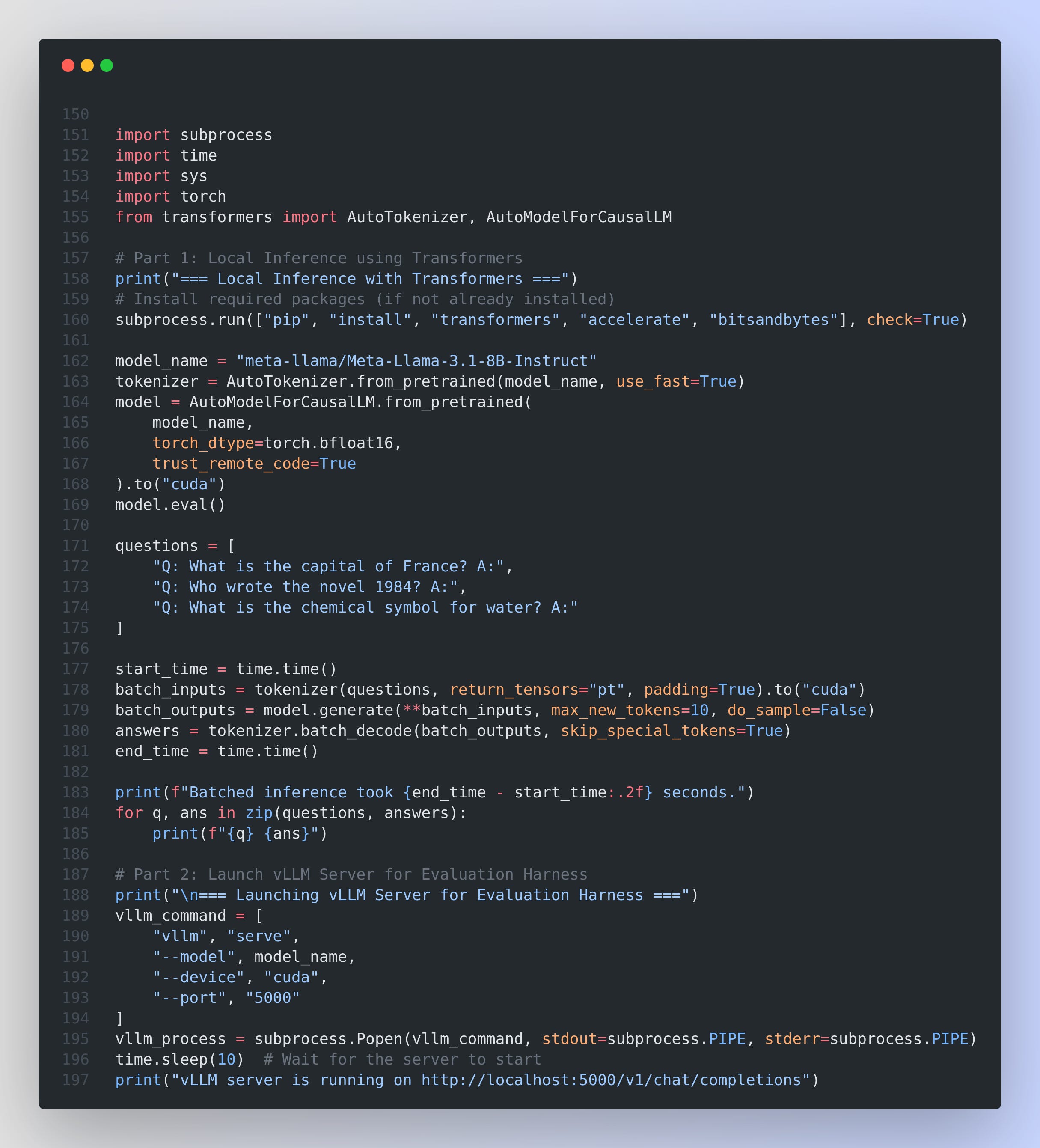
Explanation
Local Inference (Parts 1):
The script installs necessary packages and loads the Meta‑Llama‑3.1‑8B‑Instruct model (with bfloat16 precision and
trust_remote_code=True) onto the GPU.It defines a list of sample questions, tokenizes them in batch, and runs inference using
model.generate().Finally, it decodes and prints the answers along with the time taken for batched inference.
Launching vLLM (Part 2):
The script starts a vLLM server (using a subprocess call) to serve the same model on GPU at port 5000.
A brief pause ensures the server is up before proceeding.
Evaluation Harness (Part 3):
The evaluation harness (lm_eval) is run via a subprocess call.
The command specifies the model interface (
local-chat-completions), evaluation tasks (e.g., GSM8K chain-of-thought and IFEval), and model arguments (including the vLLM endpoint URL and concurrency settings).The output (evaluation metrics and logs) is captured and printed.
Cleanup (Part 4):
Finally, the script terminates the vLLM server gracefully.
References and Sources