
🧠 LLMs can indeed solve Hanoi puzzle once output shrinks within context
Google Veo3 NBA ad 2d,95% cost cut,3M+; Seedance1.0 5s1080p in41s; self-tuning LMs; Manus ScheduledTask; 200-pg AI arXiv; ChatGPT misdiagnosis fixes; Claude Code workflows

Read time: 10 mint
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (13-June-2025):
Apple’s puzzles highlight overthinking, but LLMs solve Hanoi once output shrinks within context.
🎬 Google Veo 3 powered NBA Finals spot Ad, built in 2 days at 95% cost cut gets 3mn+ views
📡 ByteDance launches Video-generation model Seedance 1.0. 5second 1080p video in 41s, ranks #1
🛠️ Anthropic researchers teach language models to fine-tune themselves
🗞️ Byte-Size Briefs:
Manus announces ScheduledTask: no-code automation for reports, digests, and surveys
Researchers release 200-page open-access arXiv overview of AI fundamentals
Reddit post reveals ChatGPT corrected doctors’ fatal misdiagnoses, saving lives
🧑🎓 Tutorial: Optimize your coding workflows with Claude Code: Know about it directly from the founding engineers
🧠 Apple’s paper highlight overthinking, but LLMs solve Hanoi once output shrinks within context.

Fitting puzzle solutions within context limits uncovers LLMs’ real reasoning strengths.
Apple released a paper last week named "Illusion of Thinking". But since then its attracted extreme level of trolling by the AI community.
Apple’s big revelation in that paper was that frontier LLMs flop on puzzles like Tower of Hanoi and River Crossing. They say the models “fail” past a certain complexity, “give up” when things get more complex/difficult, and that this somehow exposes fundamental flaws in AI reasoning.
And then on 12-July a follow-up study on that original Paper is published by another researcher named “The illusion of the illusion of thinking” proving the drawbacks of the original Apple paper.
This follow-up study shows the same models succeed once the format lets them give compressed answers, proving the earlier collapse was a measurement artifact.
Token limits, not reasoning flaws, blocked solutions
Collapse vanished once the puzzles fit the context window.
⚙️ The Core Concepts: Large Reasoning Models add chain-of-thought tokens and self-checks on top of standard language models. The Illusion of Thinking paper pushed them through four controlled puzzles, steadily raising complexity to track how accuracy and token use scale. The authors saw accuracy plunge to zero and reasoned that thinking itself had hit a hard limit.
📊 Puzzle-Driven Evaluation: Tower of Hanoi forced models to print every move; River Crossing demanded safe boat trips under strict capacity. Because a solution for forty-plus moves already eats thousands of tokens, the move-by-move format made token budgets explode long before reasoning broke.
🔎 Why Collapse Appeared: The comment paper pinpoints three test artifacts: token budgets were exceeded, evaluation scripts flagged deliberate truncation as failure, and some River Crossing instances were mathematically unsolvable yet still graded. Together these artifacts masqueraded as cognitive limits.
✅ Fixing the Test: When researchers asked the same models to output a compact Lua function that generates the Hanoi solution, models solved fifteen-disk cases in under five thousand tokens with high accuracy, overturning the zero-score narrative.
In conclusion, the authors say that in the original Apple paper the models failed only because the test forced them to write more tokens than they could fit.

In my opionion as well, I don’t find Apple “Illusion of Thinking” paper really making any strong point. Main issue: reasoning models aren’t as terrible at puzzles as it claims. Puzzles aren’t effective reasoning tests. AI labs don’t focus on them and those puzzles demand rigid step-by-step execution more than math-style reasoning. However the Apple paper does flag overthinking by LLMs on trivial tasks, shows where models quit long algorithms, and lays out “three regimes”—trivial, solvable, give-up. But teaching a model to never quit could shift that cutoff.
🎬 Google Veo 3 powered NBA Finals spot Ad, built in 2 days at 95% cost cut gets 3mn+ views
Traditional commercial ad production will face a huge disruption. 100% AI made NBA Finals AI ad, 48hour build, 95% cheaper, and hugely successul results takes internet by storm.
⚙️ The Details
→ The ad aired during Game 3 of the NBA Finals on ABC. It lasted 30 seconds and showcased Kalshi’s prediction market brand.
→ Creator PJ Accetturo used Google’s Veo 3 to produce 15 clips. He ran 300–400 generations over 2 days to craft the visuals.
→ He used Gemini and ChatGPT for ideation and script drafts. This workflow cut standard production costs by 95%. Veo 3’s new speaking feature powered on-screen dialogue.
📡 ByteDance launches Video-generation model Seedance 1.0. 5second 1080p video in 41s, ranks #1

ByteDance Engineered the “Director in the Machine” to Solve AI Video
→ Seedance 1.0 tops Artificial Analysis Arena leaderboards for both text-to-video and image-to-video. It beats Veo 3, Kling 2.0, and Sora with unmatched Elo scores.
→ The model generates 5-second, 1080p videos in 41 seconds on an NVIDIA L20. It delivers smooth transitions, multi-shot storytelling and consistent characters.
→ ByteDance curated a large, filtered video dataset with shot-aware segmentation and dense captions. They used multi-stage training with supervised fine-tuning and RLHF to balance prompt adherence, motion, and visual fidelity.
→ They introduced SeedVideoBench to benchmark motion quality, prompt adherence, and aesthetics. Seedance 1.0 will integrate with Doubao and Jimeng to power video creation on ByteDance platforms. Read the Paper here.
What's the key technical aspect that makes this model so good
Seedance splits video generation into two focused steps:
Frame crafting: The “spatial” layers act like a cinematographer. They read the text prompt and paint each 1080p frame with sharp detail and correct composition.
Motion stitching: The “temporal” layers act like an editor. They ignore the text and look only at how pixels move between frames, creating fluid, realistic motion.
Because each layer set has a single job, you get both high-fidelity images and smooth movement without one task muddying the other.
On top of that, Multishot MM-ROPE tags ranges of frames with shot identifiers. This tells the model “frames 1–50 follow Prompt A, frames 51–100 follow Prompt B,” so you can script multi-shot scenes with consistent characters and seamless cuts.
🛠️ Anthropic researchers teach language models to fine-tune themselves

🚨 Anthropic introduces a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels. It matches human supervision
⚙️ The Details
→ Anthropic researchers created Internal Coherence Maximization (ICM). It fine-tunes LLMs using only their own outputs without human labels.
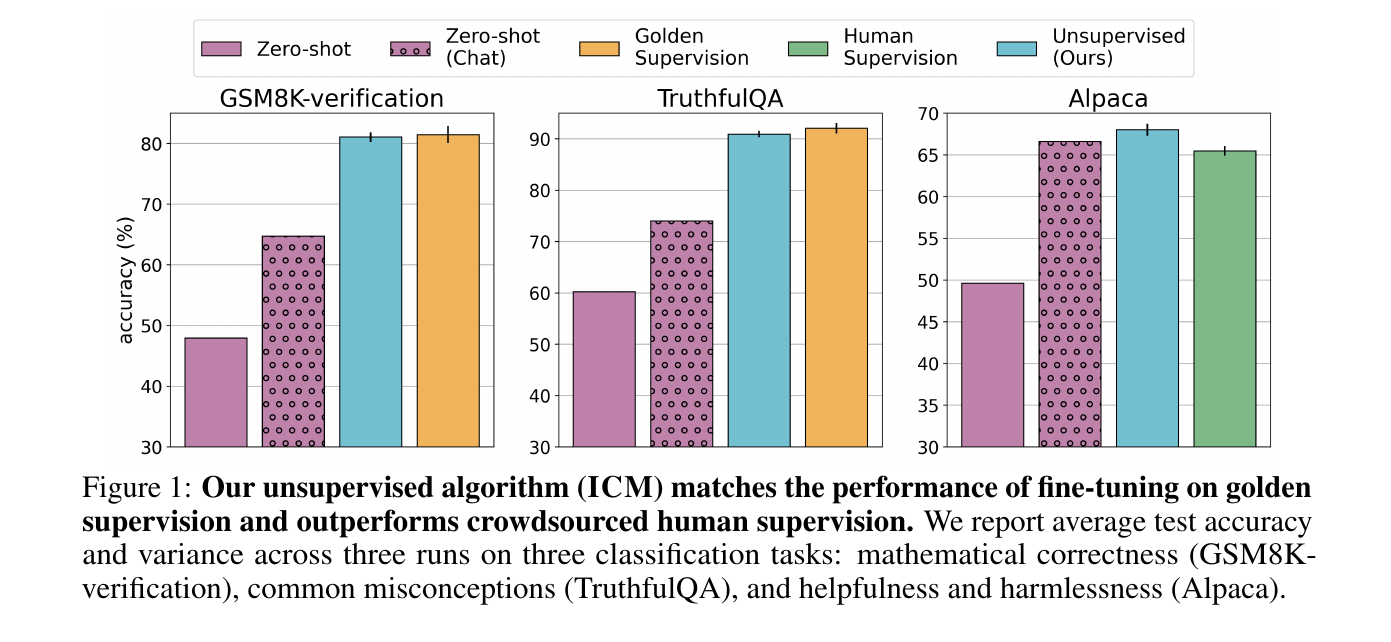
→ On TruthfulQA, GSM8K, and Alpaca, ICM matches or surpasses supervised performance. It beats crowdsourced labels on subjective tasks. For author gender prediction, ICM achieves 80% accuracy versus 60% human accuracy. This shows superhuman latent capabilities in LLMs.
→ Using ICM to train a reward model and RL, the Claude 3.5 Haiku assistant wins 60% head-to-head against its human-supervised counterpart. This demonstrates production readiness.
→ ICM fails on non-salient tasks like personal preferences. It also struggles with long inputs due to context window limits.
How does it work.
ICM is based on a simple idea: a language model like Claude or Llama should figure out for itself which answer to a question is correct, and it does so using two main criteria.
The first is mutual predictability. This means the model checks whether it can reliably infer the correct answer to a new question based on its answers to similar previous questions. If the model recognizes patterns from similar cases, it can apply them to new answers, creating an internal coherence—a set of answers that fit together and reflect a shared understanding.
The second is logical consistency. Here, the model checks its own responses for contradictions. For example, if the model labels two different solutions to the same math problem as "correct," even though the results differ, that's a logical conflict. ICM works to actively avoid these kinds of contradictions.
ICM fine-tunes an LLM by having it judge its own outputs for consistency. The model generates candidate answers, then ranks them by two criteria: mutual predictability—how well one answer predicts another—and logical consistency—avoiding contradictions across answers. It selects the most coherent set and treats those as pseudo-labels. Starting from random labels, the model repeats this loop, using its own judgments instead of human feedback to refine its weights. This lets the LLM improve itself purely from internal coherence patterns.
🗞️ Byte-Size Briefs
Manus Announced Scheduled Task. It automates market reports, news digests, and surveys on fixed schedules to free you from repetitive work. For example, it runs market reports at 7 AM, compiles daily news digests before startup, and conducts weekly customer satisfaction surveys automatically and securely across platforms, slashing manual task overhead, boosting team productivity, and ensuring consistent data delivery without extra coding or monitoring.
Learning Resource: On arXiv, a 200+ page overview book just published. Covers pretty much all the fundamentals
A Reddit post went viral about how ChatGPT saved somebody’s wife life by correcting a doctor's fatal misdiagnosis. Comments are filled with people sharing their own stories. And the post is filled with many such cases where professional doctors failed to detect but ChatGPT saved the day.
🧑🎓 Tutorial: Optimize your coding workflows with Claude Code: Know about it directly from the founding engineers

Anthropic’s Boris Cherny (Claude Code) and Alex Albert (Claude Relations) talk about Claude Code—how it started as Anthropic's own internal agentic coding tool, and practical tips for getting the most out of your experience. Find out more abot claude-code here.
Key Learning:
Anthropic’s Claude Code embeds an AI agent into existing development environments, eliminating the need for new interfaces. Installed via a single NPM command, it runs in any terminal—iTerm2, VS Code shell or SSH/TMUX—and leverages familiar tooling to explore, edit and refactor code.
It extends into GitHub Actions: by @mentioning Claude in issues or pull requests, teams can offload bug fixes, test generation and receive complete commits or PRs. This redefines engineering as supervising an autonomous “always-on-demand programmer,” replacing manual line-by-line coding with high-level orchestration and review.
Consistency is enforced through Claude.md files, scoped globally, per repository or directory, which inject project conventions directly into Claude’s context. Powered by Claude 4/Opus—capable of one-shot complex tasks and reliable instruction following—Claude Code marks a paradigm shift toward managing AI assistants rather than writing every detail by hand.
That’s a wrap for today, see you all tomorrow.