LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Models currently can't remember past conversations well, it forgets 70% of your past chats.


Models currently can't remember past conversations well, it forgets 70% of your past chats.
This paper proposes a way to measure and fix that.
Original Problem 🔍:
Chat assistants struggle with long-term memory in sustained interactions. Existing benchmarks don't adequately reflect real-world user-AI interactions or cover all necessary memory abilities.
Solution in this Paper 🛠️:
• LONGMEMEVAL: A comprehensive benchmark for evaluating 5 core long-term memory abilities
• Scalable framework for generating long chat histories with embedded test questions
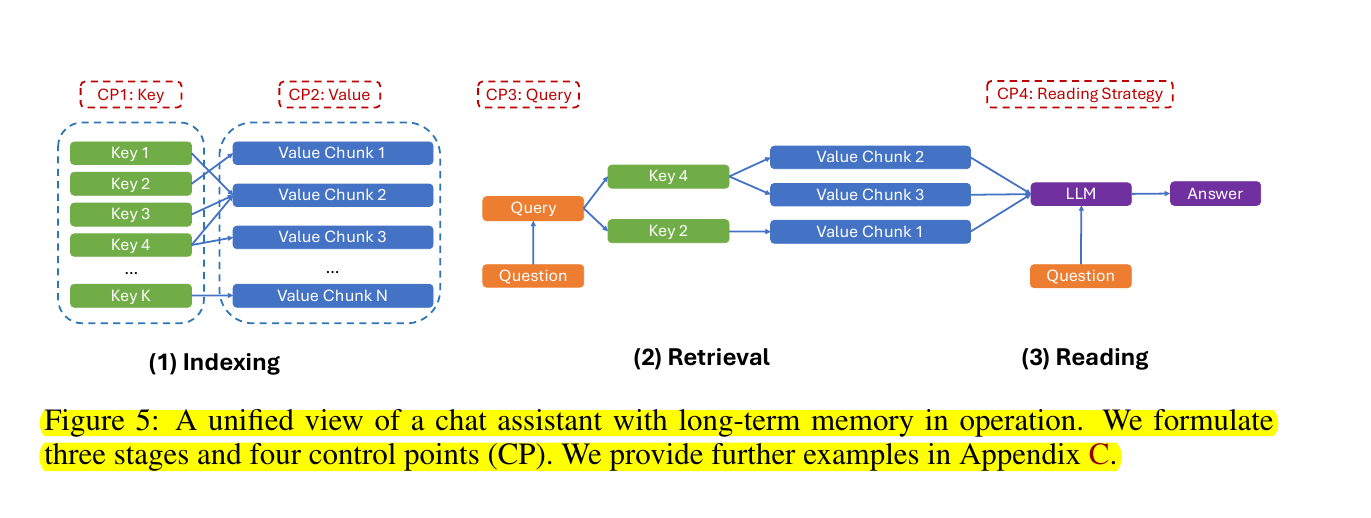
• Unified view of memory systems with 3 stages and 4 key design choices
• Optimizations: session decomposition, fact-augmented key expansion, time-aware query expansion
Key Insights from this Paper 💡:
• Commercial systems and long-context LLMs show significant performance drops on long-term memory tasks
• Effective memory mechanisms are crucial for developing personalized, reliable AI assistants
• Optimizing indexing, retrieval, and reading stages can greatly improve memory recall and question-answering performance
Results 📊:
• Commercial systems: 30-70% accuracy drop compared to offline reading
• Long-context LLMs: 30-60% performance decline on LONGMEMEVAL vs oracle retrieval
• Proposed optimizations:
4% higher recall@k in memory recall
5% higher accuracy in downstream question answering
7-11% improvement in temporal reasoning memory recall
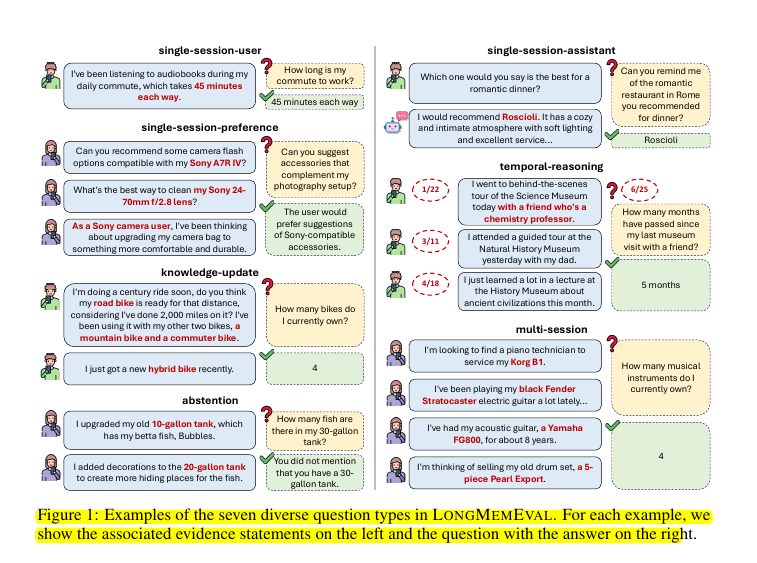
LONGMEMEVAL evaluates five core memory abilities:
Information Extraction: Recalling specific details from long interaction histories
Multi-Session Reasoning: Synthesizing information across multiple chat sessions
Knowledge Updates: Recognizing and updating changed user information over time
Temporal Reasoning: Reasoning about time-related information and metadata
Abstention: Refraining from answering questions about unknown information
LONGMEMEVAL is constructed through:
Defining an ontology of 164 user attributes in 5 categories
Using LLMs to generate attribute-focused user backgrounds
Creating questions and evidence statements based on the backgrounds
Embedding evidence in task-oriented dialogues via LLM self-chat
Human editing and annotation of dialogues
Compiling coherent chat histories by mixing evidence sessions with other chat data

The key optimizations proposed to improve memory system performance, in this paper
Session decomposition: Storing interaction history as individual rounds rather than full sessions
Fact-augmented key expansion: Enhancing index keys with extracted user facts
Time-aware query expansion: Using temporal information to refine search scope
Improved reading strategies: Applying techniques like Chain-of-Note and structured prompts