MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
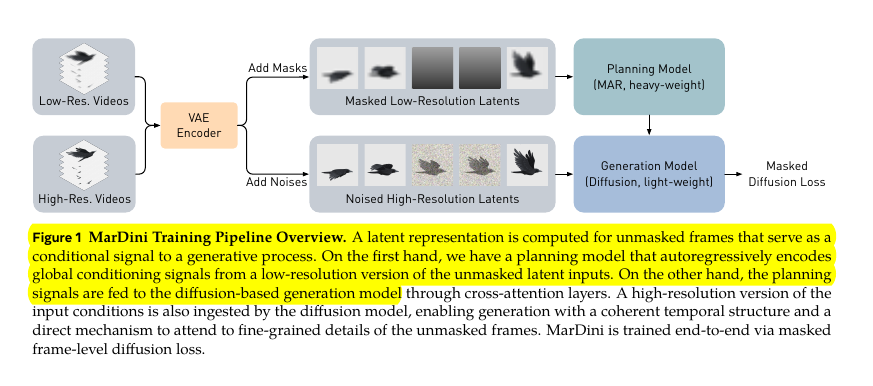
MarDini splits video generation into low-res planning and high-res details for efficient, high-quality results.


MarDini splits video generation into low-res planning and high-res details for efficient, high-quality results
Asymmetric network design makes complex video generation computationally feasible at high resolutions
Smart combination of masked auto-regression and diffusion, Planning at low resolution, generating at high resolution
🎯 Original Problem:
Video generation models face challenges in handling both temporal consistency and high-resolution spatial details while being computationally efficient. Current approaches either rely heavily on image pre-training or struggle with computational costs at high resolutions.
🔧 Solution in this Paper:
• Introduces MarDini - combines masked auto-regression (MAR) with diffusion models (DM) in asymmetric design
• Uses heavy MAR planning model for temporal dependencies at low resolution
• Employs lightweight DM for spatial details at high resolution
• Implements Identity Attention to handle noisy vs reference token disparity
• Uses progressive training strategy with gradually increasing task difficulty
• Introduces cross-attention mechanism between planning and generation models
💡 Key Insights:
• Asymmetric resolution design significantly reduces computational costs
• Direct video training without image pre-training is possible with progressive strategy
• Spatio-temporal attention becomes feasible at scale through asymmetric design
• Planning signals effectively guide temporal consistency
📊 Results:
• Achieves state-of-the-art FVD scores on VIDIM-Bench: 102.87 on DAVIS and 197.69 on UCF101
• Generates 12-frame clips at 512 resolution in just 6.05 seconds
• Requires only 42.57G GPU memory for high-resolution generation
• Performs competitively on VBench with 90.95 score without any image pre-training
🔧 How is MarDini trained?
The training process involves three progressive stages:
Initial Stage: Separate training of planning and generation models
Joint-Model Stage: Combined end-to-end training using masked diffusion loss
Joint-Task Stage: Gradually decreasing mask ratios to handle more challenging generation tasks
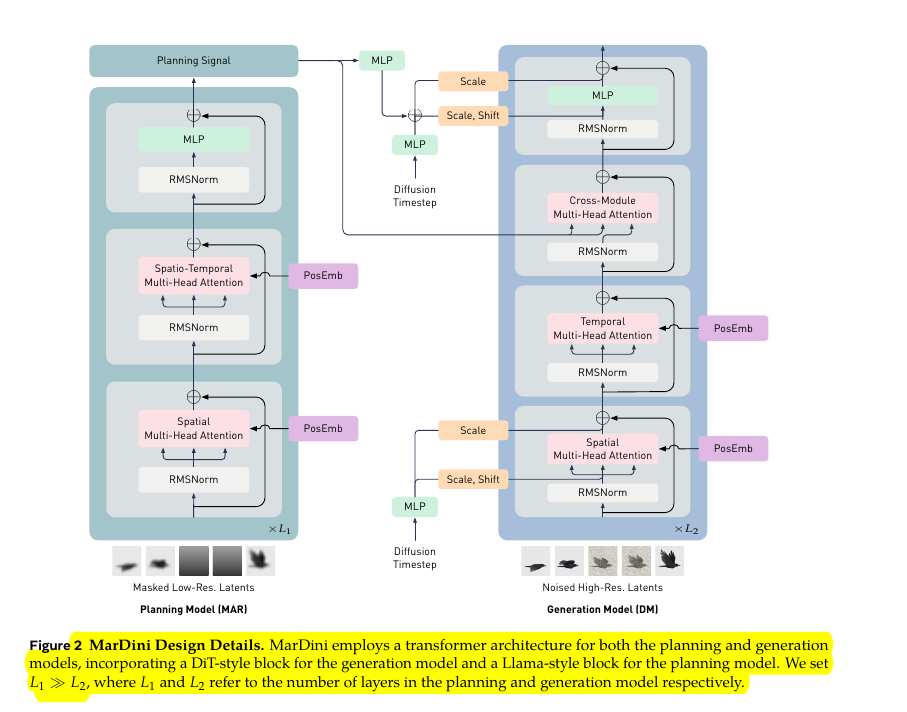
🔍 The asymmetric architecture consists of two main components:
A heavy-weight MAR planning model that processes low-resolution frames and generates planning signals
A lightweight DM generation model that uses these planning signals to produce high-resolution frames via diffusion denoising