Meta-Chunking: Learning Efficient Text Segmentation via Logical Perception
Text chunking now matches human reading patterns by detecting natural breaks in information flow.


Text chunking now matches human reading patterns by detecting natural breaks in information flow.
Meta-chunking, proposed in this paper, uses probability patterns to find natural segment boundaries in documents, just like humans do
Original Problem 🎯:
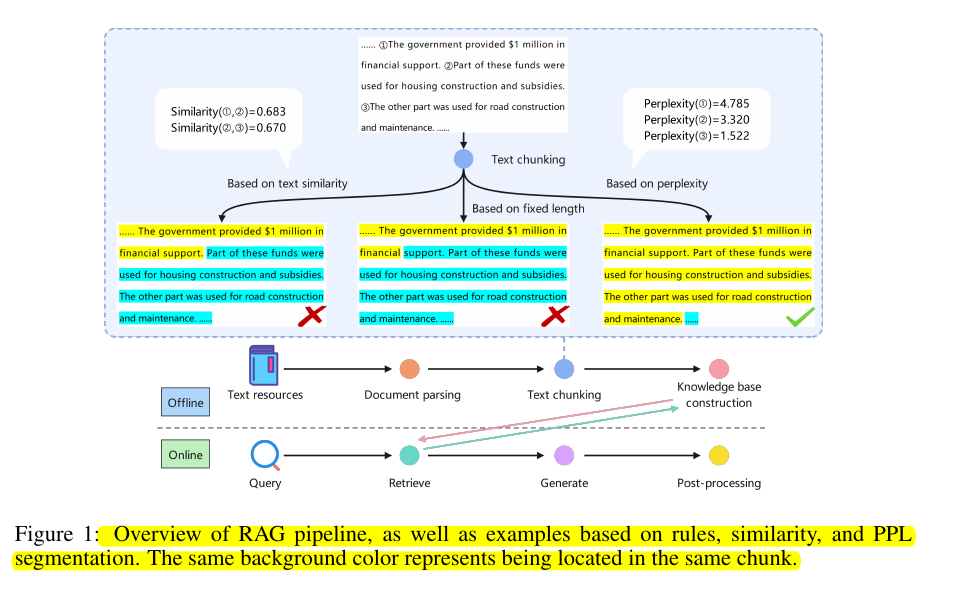
Text chunking in Retrieval-Augmented Generation (RAG) systems often fails to maintain logical coherence between segments, leading to incomplete or fragmented information retrieval. Current methods rely on fixed-length splits or basic semantic similarity, missing crucial logical connections between sentences.
Solution in this Paper ⚡:
• Meta-Chunking: A novel segmentation technique operating between sentence and paragraph levels
• Two key strategies:
Margin Sampling: Uses LLMs for binary classification to determine segment boundaries based on probability differences
Perplexity (PPL) Chunking: Analyzes perplexity distribution to identify natural text boundaries
• Dynamic combination approach to balance fine and coarse-grained segmentation
• KV caching mechanism for handling longer texts efficiently
Key Insights 💡:
• Smaller models (1.5B parameters) can effectively perform chunking tasks
• PPL distribution characteristics guide optimal threshold selection
• Dynamic chunk sizing preserves logical integrity better than fixed-length approaches
• Re-ranking performance improves significantly with Meta-Chunking
Results 📊:
• Outperforms similarity chunking by 1.32 on 2WikiMultihopQA while using only 45.8% processing time
• PPL Chunking with Qwen2-1.5B achieves 0.3760 BLEU-1 score on single-hop queries
• Maintains consistent performance across both Chinese and English datasets
• Shows 3.59% improvement in Hits@8 metric when combined with PPLRerank
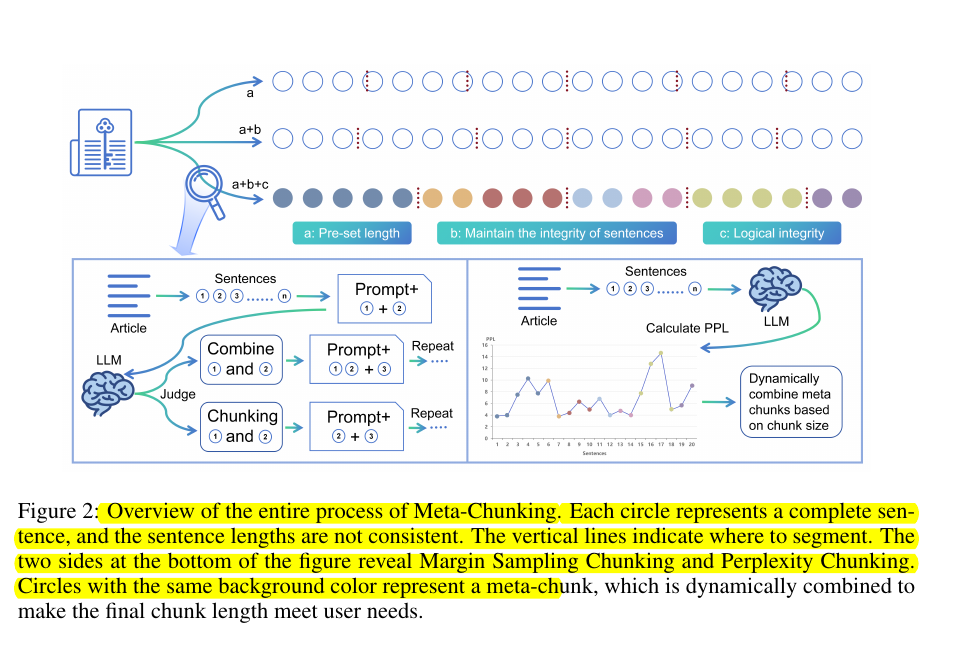
🛠️ The implementation strategies of Meta-Chunking
Two main strategies are used:
Margin Sampling Chunking - Uses LLMs for binary classification to decide if consecutive sentences need segmentation based on probability differences.
Perplexity Chunking - Calculates perplexity of each sentence based on context and identifies chunk boundaries by analyzing perplexity distribution characteristics.
Overview of the entire process of Meta-Chunking.