
🪟 Microsoft Finally Made Phi-4 Model Available On Hugging Face With Commecially Usable License
Microsoft’s Phi-4 lands on Hugging Face, GRPO powers top RLHF open models, new multilingual embeddings drop, Musk forecasts synthetic data reliance, Tesla’s humanoid robots scale to 100k+.

Read time: 7 min 58 seconds
⚡In today’s Edition (9-Jan-2025):
🪟 Microsoft Finally Made Phi-4 Available On Hugging Face With Commecially Usable License
🏆 GRPO: The RLHF Method Behind Both The Best Open-Source Models (Deepseek And Qwen)
📡 New Open Multilingual Embedding Models, Kalm-Embedding, Dropped On Huggingface With MIT License
🗞️ Byte-Size Brief:
Elon Musk predicts synthetic data dependency from here onwards as AI reaches knowledge limits.
Tesla plans to scale Optimus humanoid robot production to 100,000+ units.
Salesforce halts 2025 software engineer hiring due to AI-driven productivity boost.
DeepSeek-V3 available for local CPU, runs 600B+ params with 2-bit quants.
Prime Intellect releases METAGENE-1, 7B model for planetary pathogen detection.
Google AI Studio launches PWA for desktop, iOS, Android with native app feel.
🧑🎓 Deep Dive Tutorial
LangChain presents blueprint for structured report generation using Llama 3.3 with NVIDIA's NIM microservices
🪟 Microsoft Finally Made Phi-4 Model Available On Hugging Face With Commecially Usable License

🎯 The Brief
Microsoft has released its 14B-parameter Phi-4 LLM as fully open-source on Hugging Face with MIT license for commercial use. This move makes this high-performing model, which outperforms larger counterparts like GPT-4o and Gemini Pro 1 on math and reasoning tasks, widely accessible to developers and businesses.
⚙️ The Details
→ Phi-4 was initially available only on Microsoft's Azure AI Foundry but is now fully accessible via Hugging Face, with its weights openly available for download. The MIT license allows commercial adaptation without restrictions.
→ The model excels at mathematical reasoning and code generation, scoring over 80% on benchmarks like MATH and MGSM, outperforming larger models. It also demonstrates strong performance in HumanEval for functional code generation.
→ Trained on 9.8 trillion tokens, Phi-4 uses curated synthetic datasets focused on math, coding, and logic, alongside multilingual content (8%) but optimized primarily for English. What sets Phi-4 apart is its streamlined architecture.
→ Phi-4’s Performance Highlights:
• Scoring over 80% in challenging benchmarks like MATH and MGSM, outperforming larger models like Google’s Gemini Pro and GPT-4o-mini.
• Superior performance in mathematical reasoning tasks, a critical capability for fields such as finance, engineering and scientific research.
• Impressive results in HumanEval for functional code generation, making it a strong choice for AI-assisted programming.
→ I highly recommend the Phi-4 Technical Report. It goes into a great amount of detail into what it takes to use synthetic data from a large model to power level a small one. It also goes over how to clean data inputs for reliability. It's incredibly involved. Having such a restricted set of inputs does seem to come at a cost, but each iteration of phi has overall gotten much better.
→ The release of Phi-4 under the MIT License opens up countless possibilities. Basically, you can do whatever you want as long as you include the original copyright and license notice in any copy of the software/source. Businesses can now use it for commercial applications, and developers can fine-tune it for specific needs without requiring permission from Microsoft.
🏆 GRPO: The RLHF Method Behind Both The Best Open-Source Models (Deepseek And Qwen)
🎯 The Brief
DeepSeek-AI introduced Group Relative Policy Optimization (GRPO), an advanced RLHF method that replaces traditional PPO's value function with group-based score averaging to enhance math reasoning while minimizing memory usage. This innovation significantly boosted performance, achieving 51.7% on MATH and 88.2% on GSM8K, surpassing even larger models in open-source rankings.
⚙️ The Details
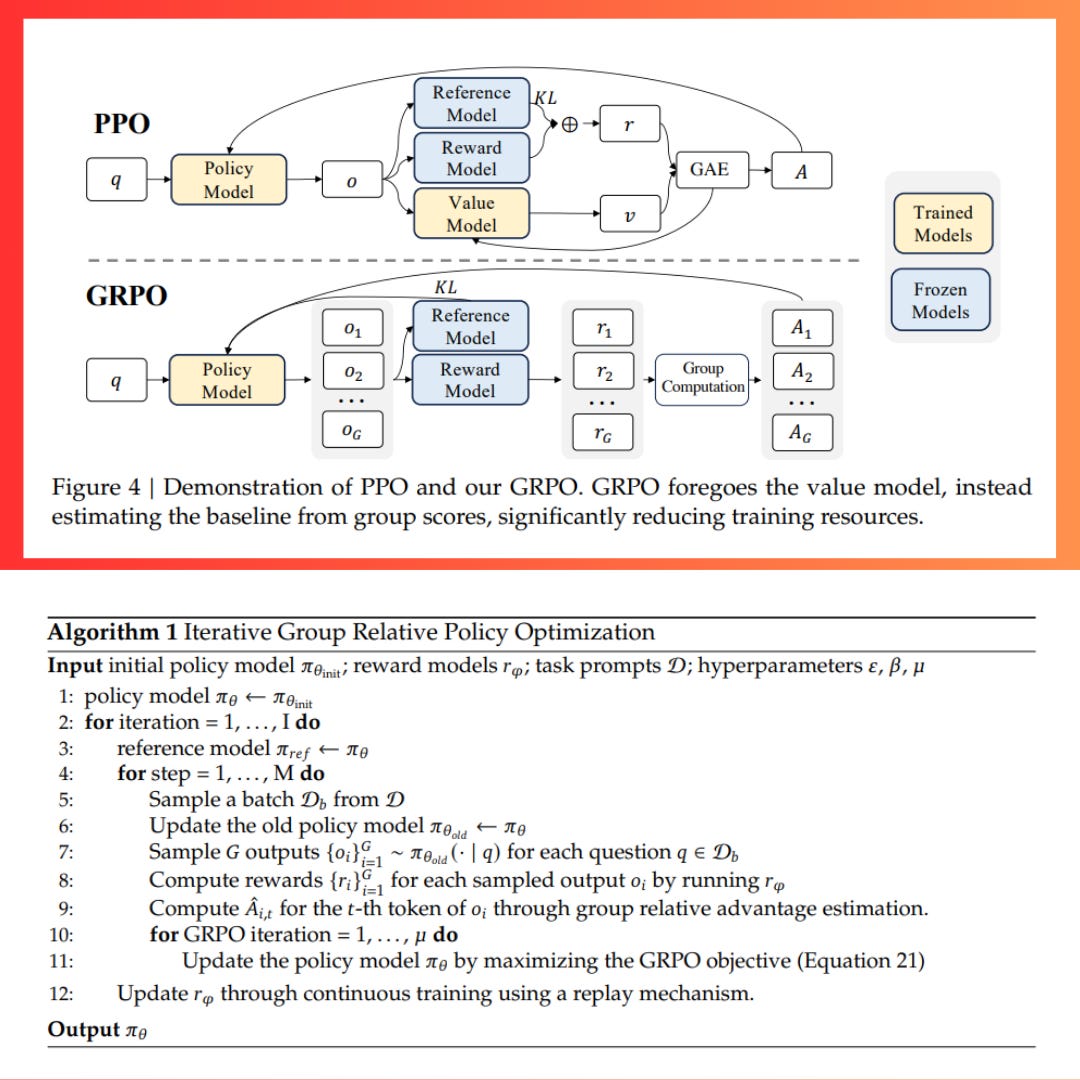
→ GRPO was introduced in the DeepSeekMath Paper last year to improve mathematical reasoning capabilities with less memory consumption, but is now used in an online way also to improve Truthfulness, Helpfulness, Conciseness
→ GRPO improves reinforcement learning by forgoing the critic model, using multiple outputs per input question to compute a baseline from average rewards, and adding a KL divergence term directly into the loss.
→ Unlike PPO, it avoids the overhead of training a separate value model, making training more efficient without sacrificing performance.
→ DeepSeekMath-Instruct 7B, tuned with GRPO, achieved significant gains: +5.3% on GSM8K (from 82.9% to 88.2%) and +4.9% on MATH (from 46.8% to 51.7%).
→ RLHF experiments also showed improvements in out-of-domain tasks, like CMATH (+4.2%), demonstrating that the reinforcement learning approach enhanced both in-domain and general mathematical reasoning.
→ GRPO's unified training framework worked with both outcome and process supervision, ensuring high performance across reasoning types.
📡 New Open Multilingual Embedding Models, Kalm-Embedding, Dropped On Huggingface With MIT License
🎯 The Brief
Harbin Institute of Technology released KaLM-Embedding, a multilingual embedding model based on Qwen2-0.5B, emphasizing higher-quality training data and synthetic persona-based examples for diverse embeddings. This model achieves a strong 64.53 average MTEB score, surpassing comparable open models.
⚙️ The Details
→ First note that Embedding models in LLMs transform text into numerical vectors, capturing semantic meaning for various downstream tasks. This new KaLM-Embedding is built with a focus on cleaner, more diverse data, incorporating 550k synthetic samples distilled from LLMs to improve robustness.
→ It adopts ranking consistency filtering to remove noise and false negatives, ensuring higher-quality embeddings.
→ The model uses semi-homogeneous task batch sampling to enhance training efficiency.
→ Achieving 64.13 on C-MTEB and 64.94 on MTEB, it sets a new benchmark for open-source multilingual models under 1B parameters. The MTEB (Massive Text Embedding Benchmark) score measures the performance of embedding models across a wide range of tasks, including semantic search, clustering, classification, and retrieval in multiple languages.
→ Supports flexible embeddings through Matryoshka Representation Learning. Matryoshka Representation Learning refers to a technique where a single large embedding can be “sliced” into smaller, lower-dimensional embeddings without needing to retrain the model. The full-size embedding can be scaled down by extracting meaningful subspaces of different sizes. This allows flexible dimension embeddings—the same model can efficiently serve tasks requiring embeddings of different sizes (e.g., 1024-d, 768-d) depending on computational needs or constraints, which is particularly useful in resource-constrained applications like edge devices or multilingual tasks. KaLM-Embedding’s use of this approach enables dynamic adaptability while preserving strong performance across tasks.
→ Released under MIT license, KaLM-Embedding is integrated into Hugging Face sentence-transformers, making it easily accessible.
🗞️ Byte-Size Brief
In an interview Elon Musk said, "Cumulative sum of human knowledge has been exhausted in AI training. That happened, basically, last year.” So from here onwards Synthentic data will be a large part of any AI training. He also said, "Any cognitive tasks that doesn't involve atoms, AI will be able to do that in max 3-4 years"
Tesla is aiming to build several thousand of its Optimus humanoid robots this year. “Assuming things go well, we’ll 10x that output next year (2026), so we’ll aim to do maybe 50,000-100,000 humanoid robots next year, and then 10x it again the following year.” - Elon Musk
Salesforce’s CEO Marc Benioff says that the company will not hire software engineers in 2025 citing a significant productivity boost from AI. In my opinion we are going to see this trend increasingly more, as with more and more powerful AI, there will be less need for Junior level Devs. On this note, earlier in Oct-2024, Google CEO revealed that AI is responsible for generating over 25% of new code at Google.
You can now run DeepSeek-V3, the world's best open-source model on your own local device. Unsloth uploaded DeepSeek V3 GGUF 2, 3 ,4, 5, 6 and 8-bit quants. Minimum hardware requirements to run Deepseek-V3 in 2-bit: 48GB RAM + 250GB of disk space for 2-bit. And this is with pure CPU and llama.cpp, which is quite incredible given the huge model size of 600Bn+ parameter.
Prime Intellect released METAGENE-1, state-of-the-art 7B parameter Metagenomic Foundation Model. Enabling planetary-scale pathogen detection and reducing the risk of pandemics in the age of exponential biology.
Google AI Studio now installable on desktop, iOS, and Android as Progressive Web App (PWA). This update eliminates the need to access the platform via a browser, offering a more seamless experience for users who frequently interact with Google AI Studio and its Gemini with Vision features. Just install the platform directly onto their devices. PWAs function like native apps but are built using web technologies. Once installed, users can launch Google AI Studio from their home screen or desktop without opening a browser.
🧑🎓 Deep Dive Tutorial
LangChain presents blueprint for structured report generation using Llama 3.3 with NVIDIA's NIM microservices
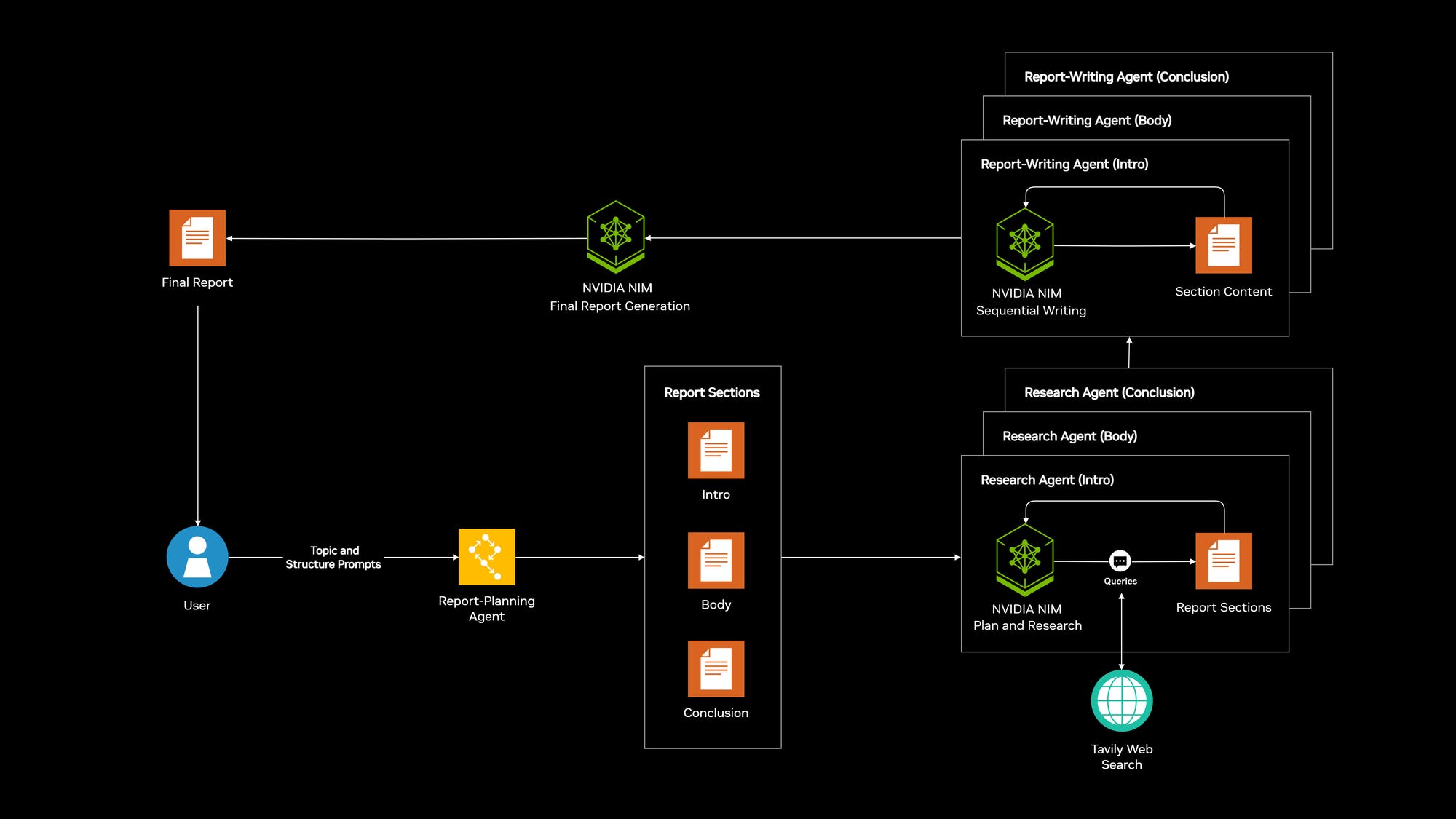
This blog explains NVIDIA and LangChain’s AI blueprint for structured report generation.
By leveraging the community models supported by NVIDIA NIM microservices, this will enable enterprises to deploy their AI agents anywhere, on cloud or data center, reducing reliance on 3rd-party-hosted inference and significantly cutting costs.
📚 Key Technical Takeaways
The blueprint is built on the LangGraph and the NVIDIA AI Enterprise platform and is comprised of the following:
NVIDIA NIM microservices: Offers optimized, low-latency model deployment across cloud, datacenter, or on-premise, addressing high inference costs and improving throughput.
Open-source LLM integration: Supports Mistral AI and Llama models, enabling fine-tuning, increased transparency, and privacy control over sensitive data.
LangGraph framework: Provides fine-grained control to design multi-step workflows for complex agent tasks, using efficient smaller models.
On-premise deployment options: LangGraph and LangSmith offer secure, on-premise agent execution to meet compliance and data governance needs.
LangSmith monitoring: Tracks performance, identifies bottlenecks, and supports debugging through comprehensive testing pipelines.