
🤯 Microsoft’S New rStar-Math makes 7B Models To Outperform OpenAI’S o1-Preview At Math
Microsoft’s rStar-Math outperforms OpenAI in math, Cohere targets enterprises with North, LLMs fail in code reuse, plus Grok’s iOS launch, AI podcasts, and TSMC’s AI-driven surge.

Read time: 8 min 45 seconds
⚡In today’s Edition (10-Jan-2025):
🤯 Microsoft’S New rStar-Math Upgrades Small Models To Outperform Openai’S O1-Preview At Math
🏆 Cohere just launched ‘North,’ its biggest AI bet yet for privacy-focused enterprises
📡LLMs Struggle To Reuse Their Own Generated Code For Solving Complex Problems
🛠️ Elon Musk’s xAI launches iOS app for its Grok chatbot in the U.S.
🎧 Google Launched AI-Powered 'Daily Listen' Podcasts, Turn Your Discover Feed Into An Ai-Generated Podcast
🗞️ Byte-Size Brief:
VideoLAN demonstrates offline subtitle AI at CES 2025 – Local open-source models enable real-time multilingual translation.
Qwen Team launches Qwen-Chat unified Web UI – Supports Q&A, visual input, HTML previews, and upcoming voice/web search.
TSMC reports 33.9% AI-driven revenue surge in 2024
🧑🎓 Deep Dive Tutorial
LlamaIndex’s “Agentic Document Workflows”, Forget static lookups—ADW makes agents orchestrate, decide, and optimize across documents like a pro
🤯 Microsoft’S New rStar-Math Upgrades Small Models To Outperform Openai’S O1-Preview At Math
🎯 The Brief
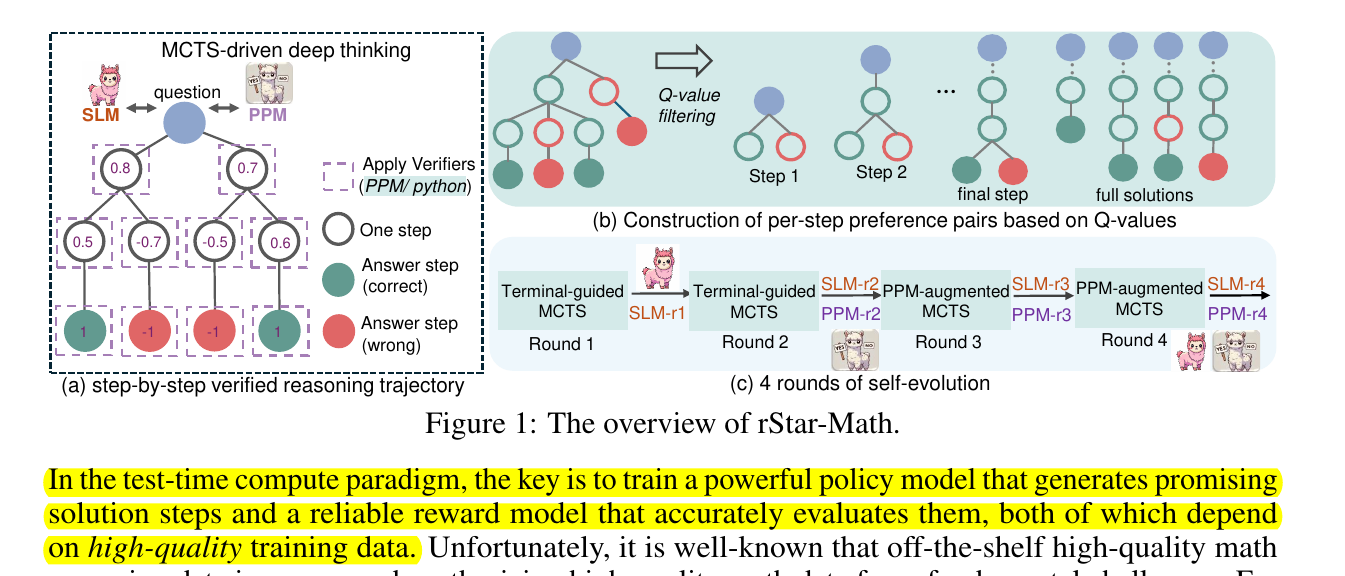
rStar-Math uses small language models (SLMs) (e.g., 1.5B, 3.8B, and 7B parameters) combined with a 7B Process Preference Model (PPM) can achieves performance comparable to much larger models like GPT-o1-mini and Qwen2.5-Math-72B-Instruct. And it surpasses OpenAI o1-preview in math reasoning by achieving 90% accuracy on the MATH benchmark and solving 53.3% of AIME 2024 problems. This approach uses MCTS-driven (Monte Carlo Tree Search) self-evolution and process reward modeling to generate verified reasoning data, showing that SLMs can self-improve without relying on massive distillation models.
How do they achieve this?
rStar-Math uses a math policy SLM for test-time search guided by an SLM-based process reward model. In this context, MCTS (Monte Carlo Tree Search) acts as a planning algorithm that explores different reasoning paths and evaluates their potential outcomes before selecting the most promising one.
This process involves building a search tree where each node represents a possible state or action, and edges represent transitions between states. The algorithm iteratively expands the tree by simulating and evaluating different paths, gradually refining its understanding of the problem and converging towards an optimal solution.
Overall the MCTS explores multiple branching solution paths and a process reward/ preference models that score and attribute steps that successfully contribute to correct math workings and answers.
⚙️ The Details
→ They first curate a dataset of 747k math word problems from publicly available sources. In each round (for four rounds), they use the latest policy model and PPM to perform MCTS, generating increasingly high-quality training data to train a stronger policy model and PPM for the next round.
→ rStar-Math introduces a code-augmented Chain of Thought (CoT) approach, involving MCTS, that generates step-by-step reasoning with executable Python code. Invalid steps are discarded, and the valid steps are scored by a process preference model (PPM).
→ The system performs four rounds of self-evolution, progressively improving the accuracy from 60% to 90.25%.
→ Key benchmarks showed that rStar-Math boosts Qwen2.5-Math-7B from 58.8% to 90% on MATH and 41.4% to 86.4% on Phi3-mini-3.8B.
→ On Olympiad-level math, it ranked among the top 20%, of high school competitors, solving 8 out of 15 problems on AIME 2024, outperforming most open-source models despite using only 7B-sized LLMs.
→ By relying on MCTS and smaller models, rStar-Math reduces the need for human annotations and large-scale distillation. Overall it shows so much alpha left in algo. With the right technique, we don't need massive models for complex tasks.
🏆 Cohere just launched ‘North,’ its biggest AI bet yet for privacy-focused enterprises
🎯 The Brief
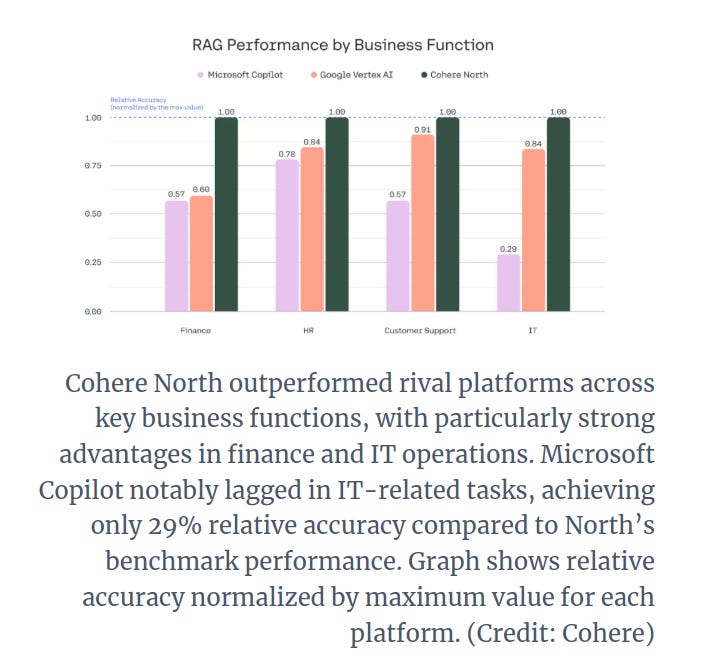
Cohere has launched North, a secure AI platform for enterprises, aiming to outshine Microsoft Copilot and Google Vertex AI in regulated industries like finance and healthcare. North is Cohere's secure enterprise AI platform combining LLMs, search, and automation for data control.
This release is significant due to its private cloud/on-premises options, advanced search automation, and focus on data security. Internal benchmarks reveal North's accuracy remained consistent in human evaluations, outperforming competitors in key business functions.
⚙️ The Details
→ North integrates LLMs, search tools, and automation into a privacy-centric workspace, designed to support enterprise operations like HR, finance, IT, and customer service.
→ The Compass search system processes documents, images, and spreadsheets, cutting task completion time by over 80% compared to manual processes.
→ North's flexibility enables enterprises to customize AI solutions without technical expertise, making it attractive to sectors previously hesitant due to data privacy concerns.
→ North is currently available through an early access program, targeting the finance, healthcare, manufacturing and critical infrastructure sectors.
→ Early adoption includes partnerships like Royal Bank of Canada for a banking-focused version of North.
📡LLMs Struggle To Reuse Their Own Generated Code For Solving Complex Problems
🎯 The Brief
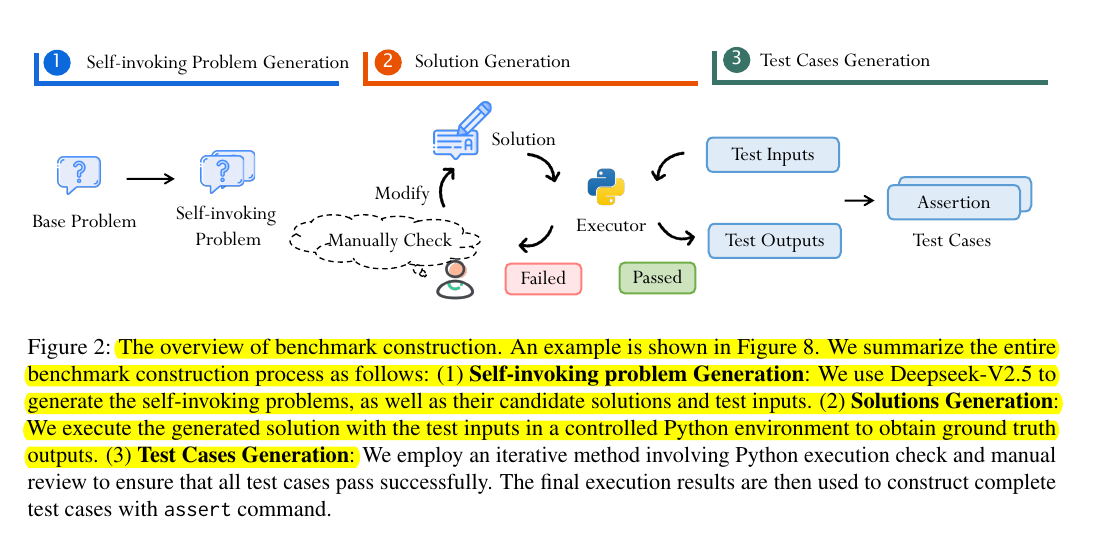
LLMs can spit out code fast, but when asked to recycle it, they hit a wall. Hence we needed a new bechmark for this. So new research introduced HumanEval Pro and MBPP Pro benchmarks to assess LLMs on self-invoking code generation. Benchmarks revealed that top LLMs like o1-mini dropped from 96.2% pass@1 on HumanEval to 76.2% on HumanEval Pro, underscoring gaps in reasoning capabilities.
⚙️ The Details
→ HumanEval Pro and MBPP Pro expand upon traditional coding benchmarks by requiring LLMs to solve base problems and reuse those solutions for more complex tasks.
→ Evaluations on 20+ LLMs, including GPT-4o, Claude-3.5-sonnet, and DeepSeekCoder, showed performance drops of 10-20% compared to simpler tasks.
→ Instruction-tuned models offered only marginal improvements over base models in self-invoking tasks, unlike traditional tasks where they perform better.
→ Self-invoking benchmark construction used DeepSeek-V2.5 to create problems, followed by iterative manual verification to ensure correctness.
→ The dominant failure types include AssertionErrors and NameErrors, highlighting issues with self-contained function calls and test case handling.
→ Findings emphasize the need for better training methods for complex reasoning and reusable code generation in LLMs.
🛠️ Elon Musk’s xAI launches iOS app for its Grok chatbot in the U.S.
🎯 The Brief
xAI has launched a standalone beta app for its Grok AI assistant, marking a significant shift away from its integration with X ( Twitter). This move positions Grok as a direct competitor to ChatGPT and Gemini by expanding its user base beyond X subscribers. The chatbot was previously available only through X.
⚙️ The Details
→ The new iOS app allows access to Grok 2, xAI’s latest AI model, without needing an X account or subscription. Users can log in via Apple, Google, X, or email and choose between free and premium tiers. There’s no update around when the app will be launched for Android users.
→ Key features include image generation, text summarization, and real-time web/X data access.
→ Grok’s search feature has improved, enabling it to reference older posts from any user on X.
→ This standalone launch aims to improve Grok’s visibility and broaden its market reach, as reliance on X previously limited its adoption. A potential Grok 3 release could further accelerate xAI's competitive edge.
→ The Musk-owned AI firm has raised huge amounts of money recently. Earlier in June last year, there was a $6 billion round and a $6 billion funding round again in December.
🎧 Google Launched AI-Powered 'Daily Listen' Podcasts, Turn Your Discover Feed Into An Ai-Generated Podcast
🎯 The Brief
Google has launched an experimental feature called "Daily Listen" within Search Labs, which turns users' Search and Discover feed history into personalized, AI-generated 5-minute podcasts. This feature aims to provide a more interactive and faster way for users to consume news. It reflects Google's broader strategy of integrating AI-driven content delivery across its platforms.
⚙️ The Details
→ The Daily Listen feature generates short podcasts summarizing stories tailored to users' interests based on their search activity and Discover feed.
→ Available only in the U.S., the feature is accessible to Android and iOS users who opt into Search Labs and appears as a widget beneath the Google app's search bar.
→ The audio player includes a rolling transcript, playback controls, and a "Related Stories" section linking additional content. Users can give thumbs-up/down feedback to refine their preferences.
→ Similar to NotebookLM's Audio Overviews, but instead of document summaries, it focuses on news stories and topics.
→ There is no timeline yet for a broader rollout, though prior experiments like AI Search Overviews suggest wider availability could follow.
🗞️ Byte-Size Brief
VideoLAN i.e. the famous VLC Play demonstrated in CES 2025 how its using local open-source AI models to enable offline subtitle generation and translation, turning your device into a multilingual assistant. This works without any cloud dependency, supports multiple languages, and showcases real-time performance at their CES 2025 Eureka Park booth.
Qwen Team launced Qwen-Chat, a unified Web UI to compare, interact, and test cutting-edge Qwen models with advanced features. It supports document uploads for Q&A, visual input handling, and HTML previews, with upcoming capabilities like web search, image generation, and voice interaction.
AI is becoming bigger and bigger. World’s largest chip manufacturer, Taiwan Semiconductor Manufacturing Company (TSMC)’s 33.9% revenue surge in 2024 reflects surging global AI chip demand. December alone saw a 57.8% revenue boost, with Q4 earnings surpassing expectations. Major clients like Apple and NVIDIA contributed to its dominance in supplying critical AI components.
🧑🎓 Deep Dive Tutorial
LlamaIndex’s “Agentic Document Workflows”, Forget static lookups—ADW makes agents orchestrate, decide, and optimize across documents like a pro
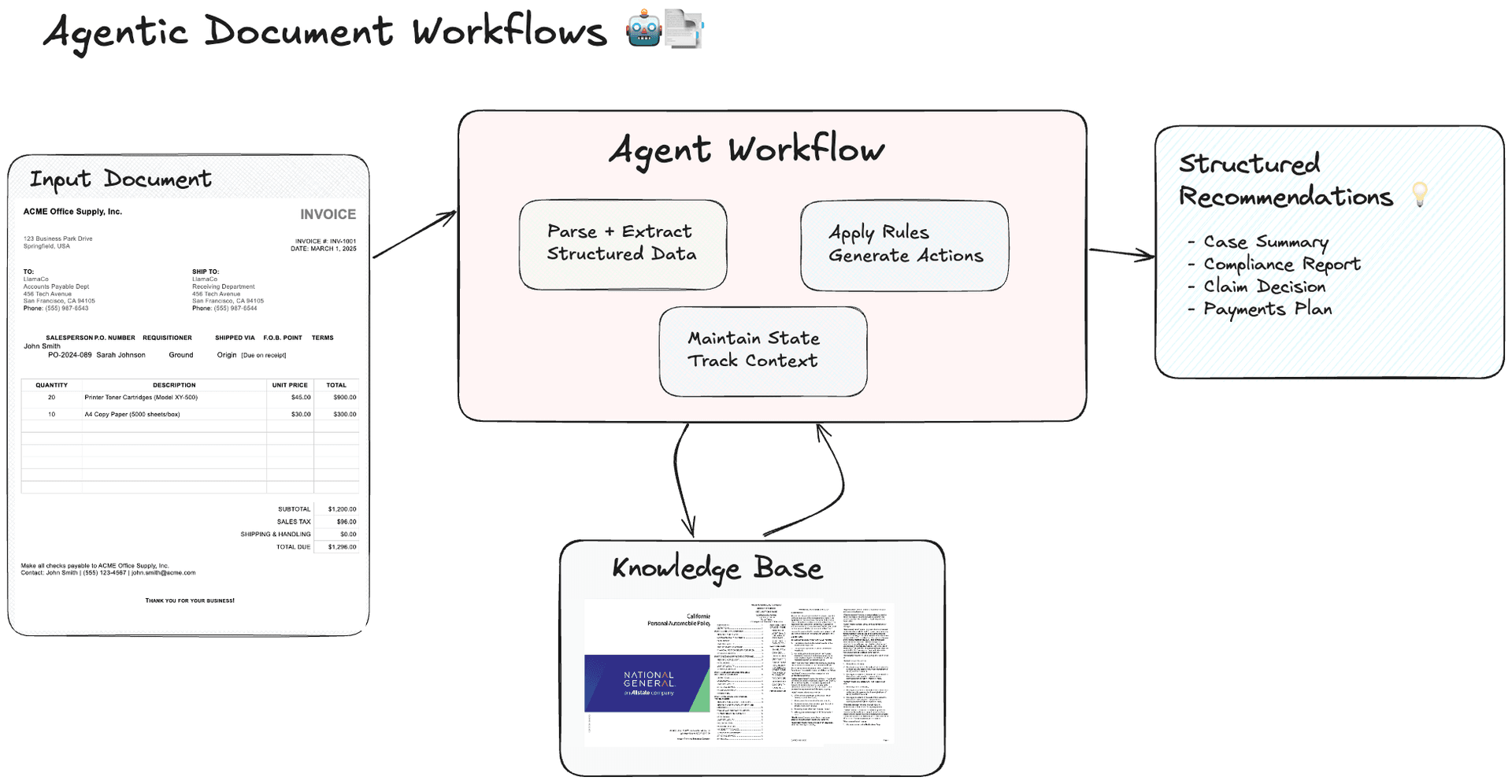
LlamaIndex's just announced Agentic Document Workflows (ADW) architecture. It enhances agent-based automation by going beyond basic RAG. ADW combines document parsing, state management, and action-driven orchestration, making it a game-changer for complex workflows like compliance review, patient case analysis, and claims processing.
→ ADW empowers agents to not only extract information but also apply business rules, maintain context, and coordinate multiple system components across document-centric processes.
→ The architecture is built with modular "document agents" that orchestrate tasks by parsing structured data via LlamaParse and retrieving reference materials from LlamaCloud. This enables multi-step processes that require deeper context retention and stateful decision-making.
→ Real-world use cases include:
Contract Review: The agent cross-references clauses against regulatory frameworks, surfacing compliance issues and generating actionable summaries.
Healthcare Summaries: It consolidates medical records, maintaining context across diagnoses and treatments to support physician decision-making.
Invoice Optimization: The agent aligns extracted payment terms with contract agreements, optimizing payment schedules based on vendor terms.
Claims Processing: It organizes data from multiple sources, presenting claims details while leaving final decisions to humans.
→ Unlike traditional RAG workflows focused on isolated query-answer steps, ADW treats documents as interconnected elements within broader business workflows, facilitating end-to-end automation while retaining human oversight for critical decisions.