
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
CoT prompting can actually hurt LLM performance in some tasks.


CoT prompting can actually hurt LLM performance in some tasks.
The paper shows LLMs and humans share similar limitations when forced to explain their thinking
Identifies specific scenarios where asking LLMs to explain reduces their accuracy.
i.e. When thinking out loud makes both AI and humans mess up.
Original Problem 🤔:
Chain-of-Thought (CoT) prompting, while widely used with LLMs, can sometimes reduce model performance. However, there's no clear understanding of when and why this happens.
Solution in this Paper 🔧:
→ Identifies tasks where CoT reduces performance by examining cases where verbal thinking hurts human performance
→ Tests if these human cognitive limitations translate to LLMs using two criteria:
Tasks where verbal thinking hurts human performance
Constraints governing human performance apply to LLMs
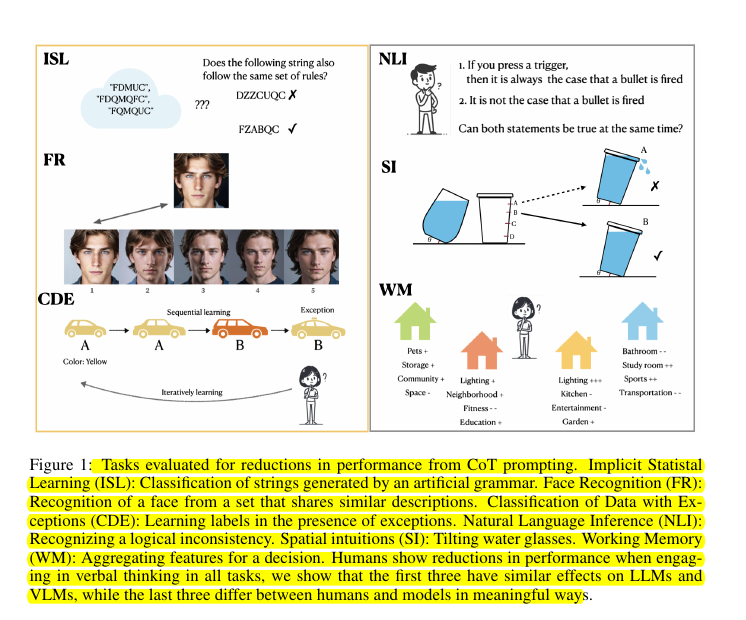
→ Evaluates six representative tasks:
Implicit statistical learning
Face recognition
Classification with exceptions
Logical inconsistency
Spatial intuition
Working memory tasks
Key Insights 🎯:
→ CoT significantly reduces performance when both criteria are met:
Up to 36.3% accuracy drop in implicit statistical learning
Consistent performance drops in facial recognition
331% increase in learning iterations for exception-based classification
→ When only the first criterion is met but constraints differ between humans and LLMs, CoT either improves performance or shows no significant impact
→ Understanding human cognitive limitations helps predict when CoT might be detrimental
Results 📊:
→ OpenAI o1-preview: 36.3% absolute accuracy drop vs GPT-4o in statistical learning
→ Face Recognition: Performance decrease across all six vision-language models tested
→ Exception Learning: CoT increased learning iterations by up to 331%
→ Tasks with mismatched human-LLM constraints: No significant performance reduction
🔍 How does the paper determine which tasks will show reduced performance with CoT?
It identifies tasks based on two key criteria:
(i) verbal thinking/deliberation hurts human performance in these tasks, and
(ii) the constraints governing human performance generalize to AI models.
They test six representative tasks - three where both criteria are met and three where only criterion (i) is satisfied.
💡 The broader implications
→ CoT is not universally beneficial and can significantly harm performance in specific scenarios
→ Understanding human cognitive limitations can help identify cases where CoT might be detrimental
→ The parallel between human verbal thinking and model CoT reasoning exists but isn't exact - shared constraints between humans and models are crucial for the parallel to hold.