Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
"Any Model Can Talk" - Mini-Omni First open-source end-to-end multimodal model with audio input/output


"Any Model Can Talk" - Mini-Omni First open-source end-to-end multimodal model with audio input/output
Bridges text and speech modalities, enabling fluid voice interactions with minimal computational resources.
Original Problem 🔍:
Current language models lack real-time voice interaction capabilities. Existing approaches use cascaded text-to-speech systems with high latency or end-to-end methods that still require waiting for text generation, hindering integration into daily applications.
Key Insights from this Paper 💡:
• Text-instructed speech generation enables direct audio reasoning
• Batch-parallel strategies boost performance and reasoning capabilities
• "Any Model Can Talk" training method allows rapid speech adaptation
• VoiceAssistant-400K dataset facilitates speech output fine-tuning
Solution in this Paper 🛠️:
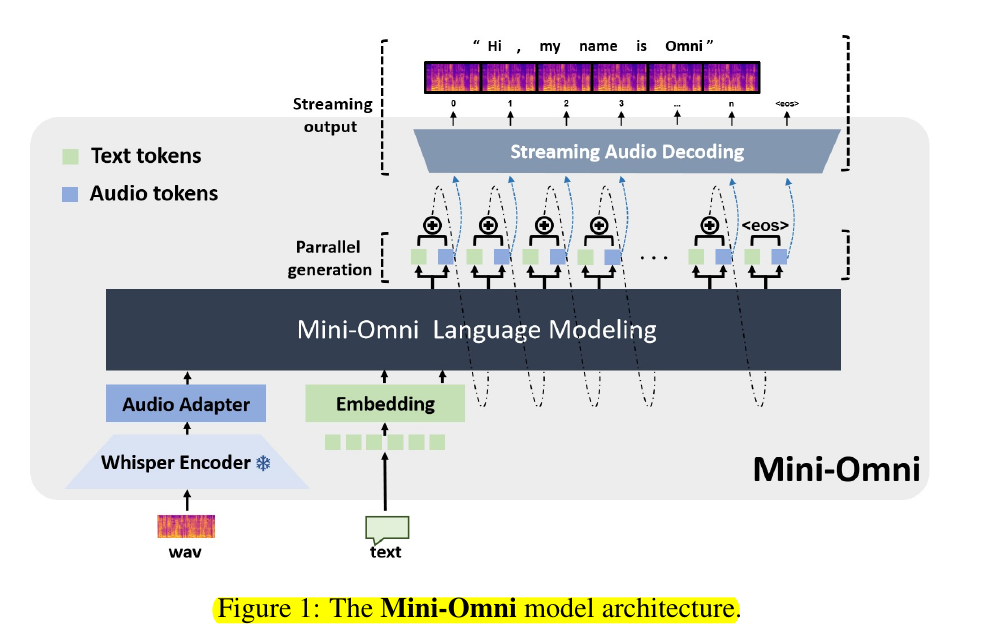
• Text-instruct parallel generation: Simultaneously outputs text and audio tokens
• Text-delay parallel decoding: Generates multiple audio token layers in one step
• Batch parallel decoding: Enhances reasoning by leveraging text-based capabilities
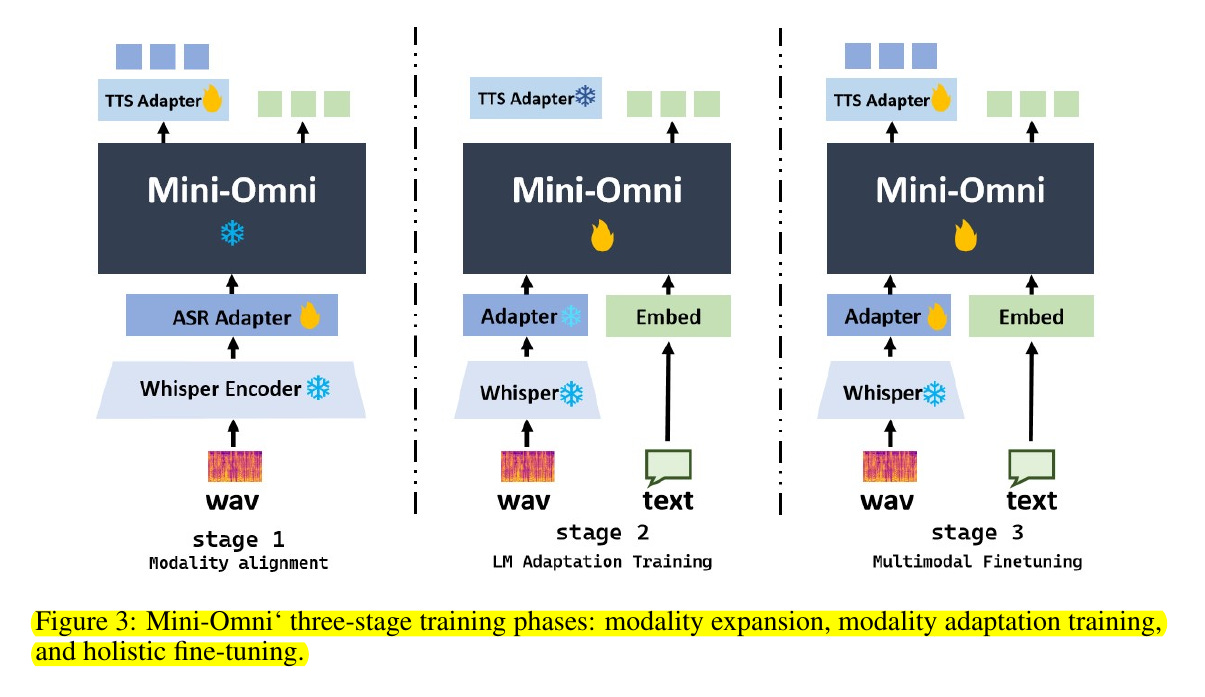
• Three-stage training: Modality alignment, adaptation, and multi-modal fine-tuning
• SNAC audio encoder: 8 layers of codebooks for high-quality audio processing
Results 📊:
• ASR performance on LibriSpeech test-clean: 4.5 WER (vs 3.4 for Whisper-small)
• Achieves real-time speech interaction with only 0.5B parameters
• Preserves original model's language capabilities
• Enables streaming output with high model and data efficiency