Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
Mini-Omni2 packs vision, speech, and interruption capabilities into a lightweight open-source package.


Mini-Omni2 packs vision, speech, and interruption capabilities into a lightweight open-source package.
Original Problem 🔍:
GPT-4o represents a milestone in multi-modal LLMs, but its technical details remain undisclosed. Existing open-source models often focus on specific functionalities, lacking a unified approach for text, vision, and speech capabilities.
Solution in this Paper 🛠️:
• Introduces Mini-Omni2, an open-source multi-modal LLM with vision, speech, and duplex capabilities
• Employs CLIP ViT-B/32 for visual encoding and Whisper-small for audio encoding
• Utilizes Qwen2-0.5B as the base language model
• Implements a three-stage training process for modality expansion and alignment
• Proposes a command-based interruption mechanism for flexible interactions
Key Insights from this Paper 💡:
• Demonstrates the feasibility of creating an open-source GPT-4o-like model
• Highlights the importance of modality alignment in multi-modal LLMs
• Showcases the potential of command-based interruption for natural interactions
Results 📊:
• Maintains comparable speech recognition accuracy to base Whisper model
• Achieves 4.8% WER on LibriSpeech test-clean (vs 4.4% for Whisper-small)
• Demonstrates capabilities in multi-modal question answering and real-time voice interaction
• Open-sources model and datasets for future research
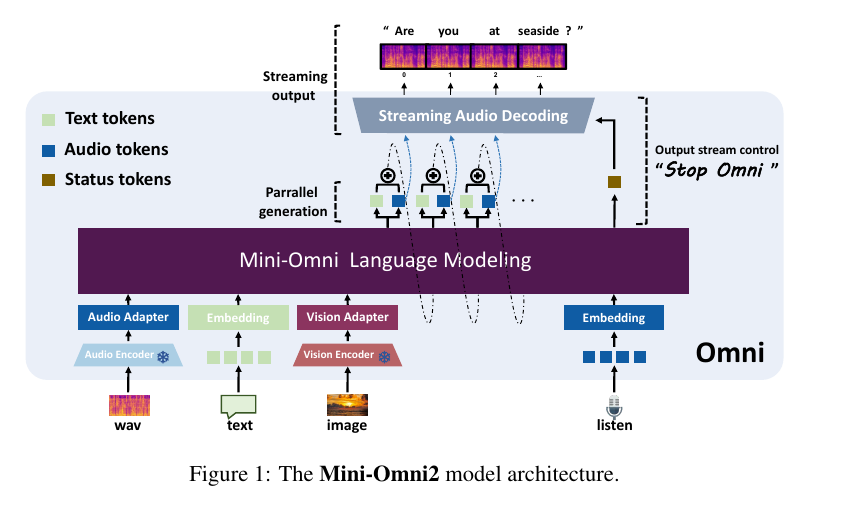
🧠 The Mini-Omni2 model architecture consists of:
A visual encoder using the CLIP ViT-B/32 model
An audio encoder using the Whisper-small model
The Qwen2-0.5B base model as the foundational language model
A multi-layer vocabulary construction for parallel generation of text and audio tokens
Adapters to align features from different modalities