


MiniMax-01 blows the competition out of the water with its massive 4 million token context window. This allows it to analyze documents hundreds of pages long in a single pass! This would be an ideal model for agent use or long context understanding with great cost-efficiency and performance!
Notably, MiniMax-Text-01 achieved 100% accuracy on the Needle-In-A-Haystack task with a 4-million-token context.
But how did they achieve this feat?
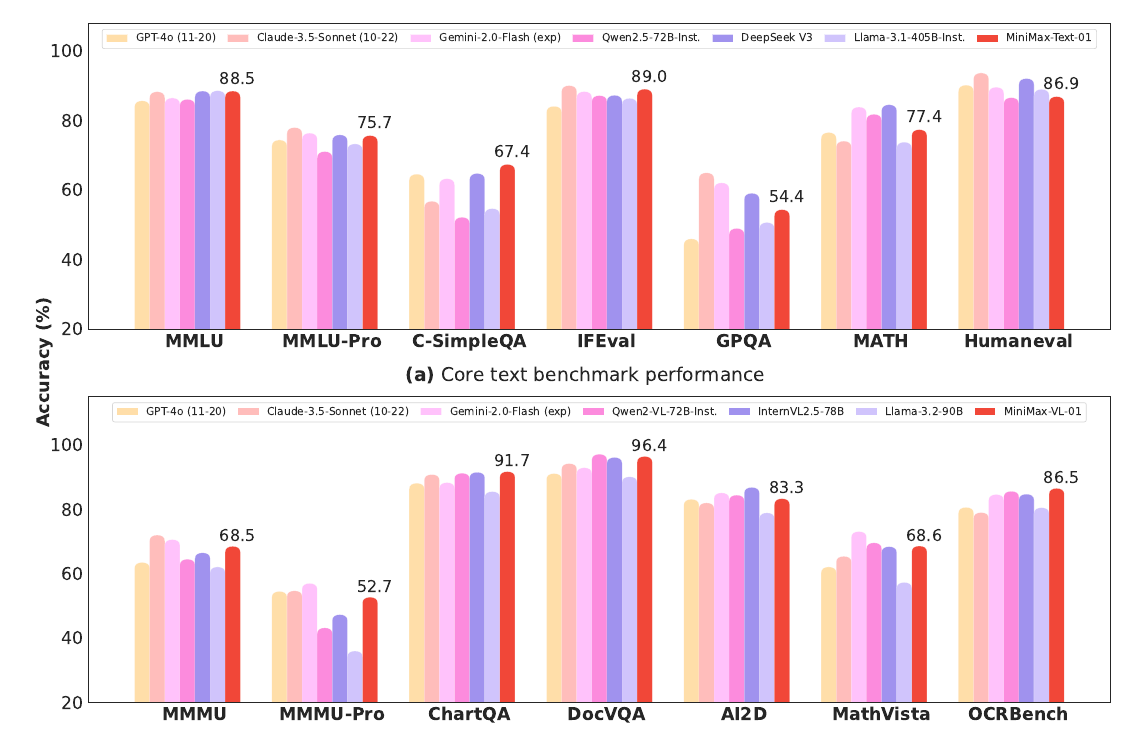
MiniMax released the MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, as open-source models to redefine long-context processing. With an unprecedented 4 million tokens context window for inference, it leverages a lightning attention mechanism and a Mixture of Experts (MoE) architecture. This innovation ensures efficiency with 456 billion parameters while activating only 45.9 billion per token. It rivals top-tier models like GPT-4o in both text and multi-modal tasks while offering 20-32x longer contexts.
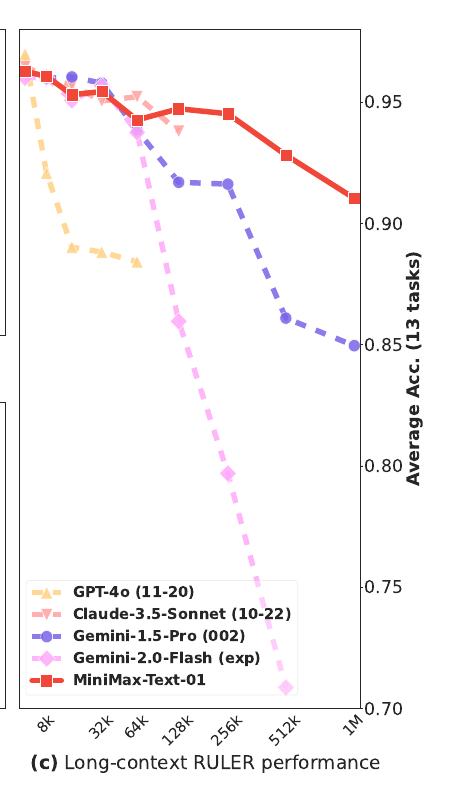
MiniMax-Text-01 maintains higher accuracy even with a 1M-token context window, outperforming others like Claude-3.5 and Gemini models, which show steep declines beyond 256K tokens.
Lightning Attention was one of the most important secret-sauce to achieving the 4-million-token context window.

It avoids the usual softmax structure by using a linear formulation that scales in proportion to sequence length. Traditional softmax attention grows computationally in a quadratic fashion, making it infeasible for ultra-long sequences.
This breakthrough is made possible by an intricate combination of architectural design, efficient memory strategies, and optimized attention mechanisms.
All 3 Key Innovations contribution to the 4mn Context Window

Lightning Attention Mechanism: MiniMax-01 replaces the standard softmax attention used in transformers with lightning attention, a custom implementation of linear attention that scales with near-linear complexity instead of quadratic. Unlike softmax attention, where the computational cost grows quadratically with the sequence length, lightning attention reduces this to a linear cost by restructuring the matrix operations.
Hybrid Attention Layering: Instead of relying solely on linear attention, the model intersperses softmax attention blocks after every 7 layers of lightning attention. This hybrid design improves the model's ability to handle tasks requiring precise token-to-token interactions while retaining the efficiency of linear attention.
How it Works: Lightning attention quickly handles long ranges by compressing interactions into efficient matrix products. However, it sometimes struggles with tasks needing exact matching of tokens. Adding a softmax block every few layers injects sharper, more localized attention, which boosts the model’s retrieval and inference quality, especially for complex queries.
Why it Matters: Relying solely on linear attention often weakens the model’s ability to recall specific facts. Softmax attention is excellent at fine-grained relationships but quickly becomes expensive on very long sequences. By combining the two, the model supports extremely large windows without losing the detailed focus required for challenging tasks.Mixture of Experts (MoE): The model uses a Mixture of Experts (MoE) strategy with 32 expert subnetworks. Each token is routed to only a few experts, meaning only a subset of parameters is activated per token, allowing the model to maintain high capacity without activating all 456 billion parameters at once.
Implementation Details
Efficient All-to-All Communication: A core challenge in MoE-based systems is the overhead from routing tokens to different GPUs. MiniMax-01 introduces an Expert Tensor Parallel (ETP) strategy, which partitions expert weights across GPUs and enables concurrent communication. This avoids significant idle time and allows computations to overlap with communication, effectively doubling efficiency.
Lightning Attention Forward Pass: The key innovation in lightning attention is the avoidance of the slow
cumsumoperation often used in linear attention. Instead, a tiling strategy divides matrices into smaller "blocks." Each block is computed separately to ensure linear scaling.
Here’s a simplified view of the lightning attention implementation:
# Pseudo-code example of Lightning Attention forward pass
for t in range(num_blocks):
Q_block, K_block, V_block = load_blocks(Q, K, V, t)
intra_block_output = (Q_block @ K_block.T) * mask @ V_block
inter_block_update += K_block.T @ V_block
output[t] = intra_block_output + Q_block @ inter_block_updateExplanation: The code iterates over smaller blocks (
num_blocks). For each block, it computes local (intra-block) attention and then updates the global (inter-block) summary matrix. The result is a constant computational cost for each iteration, independent of the total sequence length.Why this matters: By processing the sequence in blocks, the memory overhead is kept low, allowing longer sequences without hitting GPU memory limits. The inter-block matrix avoids the need to recompute expensive key-value products for earlier tokens.
Handling Long Contexts Efficiently
Varlen Ring Attention: For training sequences that reach millions of tokens, padding-based approaches are wasteful. MiniMax-01 introduces varlen ring attention, a mechanism that dynamically partitions the input into smaller groups. This avoids padding by ensuring that shorter sequences don’t cause empty computations.
Data Packing for Sequences: Instead of treating each long sequence as a single unit, MiniMax-01 concatenates multiple shorter sequences during training. These concatenated sequences form a single long stream, reducing computational waste by maximizing GPU utilization.
Memory Partitioning and Quantization: MiniMax-01 employs 8-bit quantization for weights during both training and inference. This significantly reduces memory usage, enabling it to fit larger sequences without degrading model performance.
Hybrid Layer Benefits
Why mix lightning and softmax attention? Linear attention mechanisms like lightning attention perform exceptionally well for long-context summarization and general token interactions but may struggle with fine-grained, local dependencies. To address this, the design alternates every eighth layer with a softmax-based attention layer, known for its precise handling of close-range interactions.
Rotary Positional Embeddings (RoPE): To support extrapolation to long sequences, MiniMax-01 applies RoPE to half of the attention heads. This embedding method encodes positional information in a way that supports length generalization without causing numerical instability.
Mixture of Experts (MoE) Efficiency
Top-2 Routing: Each token is routed to the top 2 experts based on its gating score, which helps distribute the computational load. By ensuring that only a fraction of experts are activated per token, the overall computational cost remains manageable.
Load Balancing: One major challenge with MoE is preventing some experts from being overloaded while others remain underutilized. MiniMax-01 uses a global router inspired by GShard to ensure that tokens are evenly distributed across experts, avoiding routing collapse.
Inference Optimizations
On-Chip Caching: During inference, MiniMax-01 utilizes prefix caching, where intermediate attention states from previous contexts are stored in faster SRAM instead of recomputing them. This significantly speeds up the inference process for incremental updates.
Sequence Parallelism: The model partitions extremely long sequences across multiple GPUs using Linear Attention Sequence Parallelism (LASP). This method enables GPUs to handle different parts of the sequence concurrently without excessive memory duplication.
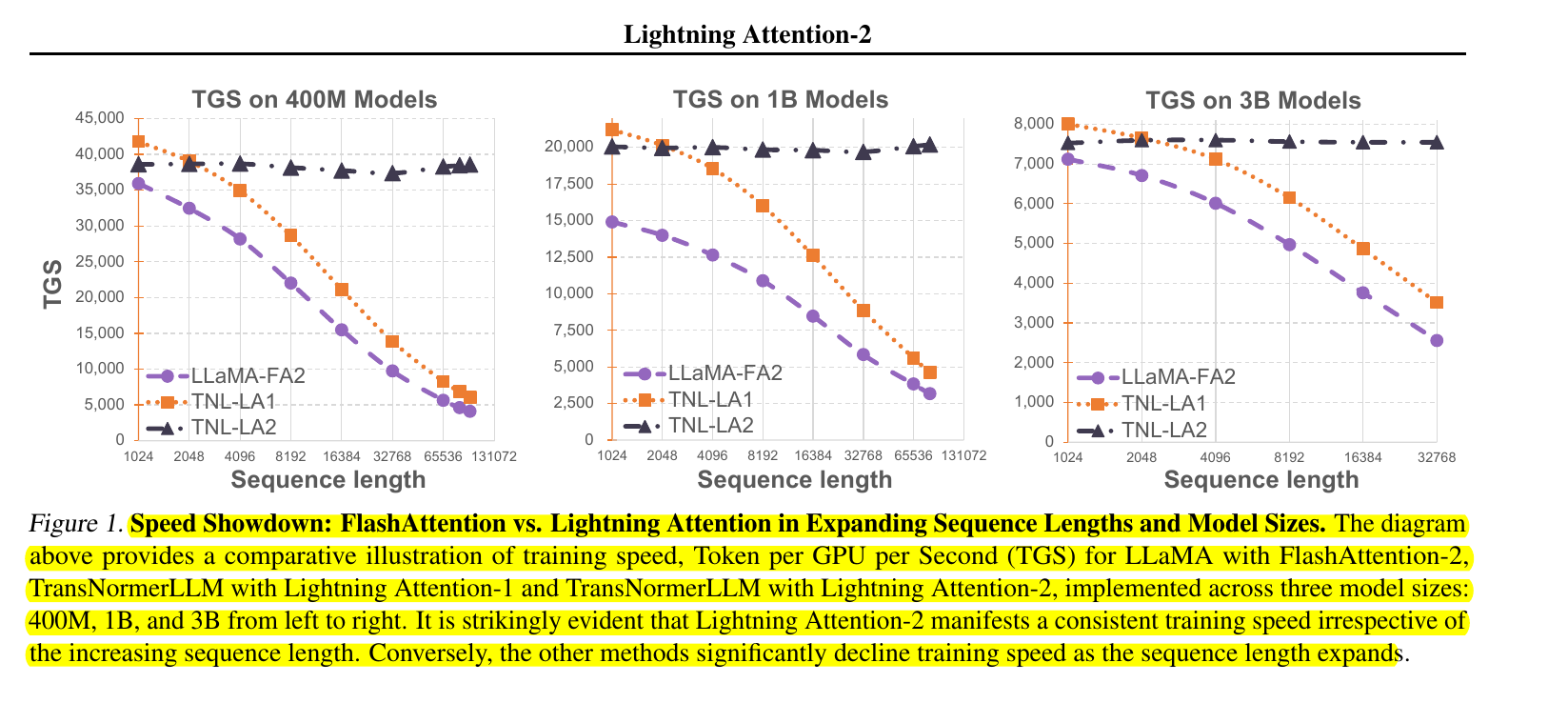
More on Lightning Attention-2 and how it achives Linear complexity

Lightning Attention-2 (LA2) is a new type of attention mechanism that is much more efficient. It's like having a bigger, better short-term memory that can handle a lot more information without getting overloaded.
Here's how it works in simple terms:
Tiling: LA2 divides the input data into smaller chunks called "tiles." This makes it easier to manage and process.
Intra- and Inter-block Calculations: LA2 performs calculations within each tile ("intra-block") and between tiles ("inter-block"). This "divide and conquer" strategy is key to its efficiency.
Left and Right Products: LA2 uses different types of calculations (left and right products) for intra- and inter-block computations. This is a bit like using different tools for different parts of a job. The left product is used for computations within a tile, while the right product is used for computations between tiles. This is important because the right product allows for a recursive calculation that is much more efficient for long sequences.
GPU Optimization: LA2 is designed to work well with the hardware that powers LLMs (GPUs). It's like having a well-organized workspace where everything is within easy reach.
By combining tiling, intra- and inter-block calculations, and the recursive right product, LA2 achieves linear complexity. This means that the computational cost increases in direct proportion to the input size, not quadratically as in traditional attention mechanisms.
→ Divide the sequence. The model takes the query-key-value (QKV) representations for a large sequence and splits them into smaller blocks (for example, a block size of 256 tokens). Each block can then be processed locally (intra-block) while still maintaining information about the already processed blocks (inter-block).
→ Two-part calculation. Within a single block: • Intra-block (left-product): The block looks at only the tokens inside it, building “local attention” without having to recompute any large attention matrix.
• Inter-block (right-product): After finishing a block, it summarizes all previous blocks into a compact key–value prefix. The next block uses that prefix to “look back” at earlier tokens but does so efficiently by referring to just the compact summaries instead of the entire raw data from previous blocks.
→ Why it’s linear. Traditional softmax attention forms a giant matrix of size (sequence length) x (sequence length), which grows quadratically. In contrast, lightning attention organizes computations so that each block has a fixed cost. When you move to the next block, you only update a small prefix (like an ongoing summary), rather than recomputing attention with every token. This design ensures the total cost scales roughly in direct proportion to the number of tokens, not squared.
→ No repeated full-sequence scans. During inference, if the model generates tokens one at a time, it just keeps updating its “prefix” representation. This avoids the usual slow step of re-checking all previous tokens in detail.
→ Better memory efficiency. By only storing and reusing partial sums, the approach does not blow up in memory usage when sequences become extremely large (e.g., millions of tokens). Each block’s computation is mostly self-contained plus a small overhead for referencing earlier data.
Overall, lightning attention makes it practical to handle context windows in the range of millions of tokens, since the computations and memory usage remain tractable, even as the input length grows.
Concluding thought
The MiniMax-01's ability to process 4 million tokens relies on a combination of efficient attention mechanisms, expert-based load distribution, and clever use of memory and computation parallelism. Lightning attention and hybrid-layer designs overcome the limitations of both softmax and pure linear attention, while the Mixture of Experts reduces the active parameter count to keep computation feasible. Together, these innovations make it possible to work with massive context lengths while keeping training and inference costs manageable. The result is a highly scalable model architecture optimized for real-world AI agent tasks requiring ultra-long memory and comprehension capabilities.