
🇨🇳 MiniMax-M2 model from a Chinese start-up, is the new king of open source LLMs (especially for agentic tool calling).
China's MiniMax-M2 beats all open LLMs, OpenAI restructures under Microsoft, and NVIDIA pushes AI infra with BlueField-4, Solstice, and Equinox builds.
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (29-Oct-2025):
🇨🇳 MiniMax-M2 model from a Chinese start-up, is the new king of open source LLMs (especially for agentic tool calling).
📢 Today’s Sponsor: Luna from Pixa AI just launched - A leap forward in speech-to-speech model that feels like a human, with ultra-low latency (~600ms).
🤝 OpenAI Completes For-Profit Transition, Pushing Microsoft Above $4 Trillion Valuation.
🏆 Microsoft played so well with the OpenAI deal.
🏭 Nvidia Reveals BlueField-4 DPU (Data Processing Unit), Packed With 64-Core Grace CPU For AI Data Centers.
🏛️ NVIDIA, Oracle, and the US Department of Energy will build Solstice with 100,000 Blackwell GPUs at Argonne plus Equinox with 10,000 Blackwell GPUs, aiming at 2,200 exaflops of AI performance for open science.

🇨🇳 MiniMax-M2 model from a Chinese start-up, is the new king of open source LLMs (especially for agentic tool calling).
World’s highest intelligence-to-cost ratio
200k input and 128k output tokens, so it can handle long codebases or logs without cutting off the response.
100 Tokens per second throughput,
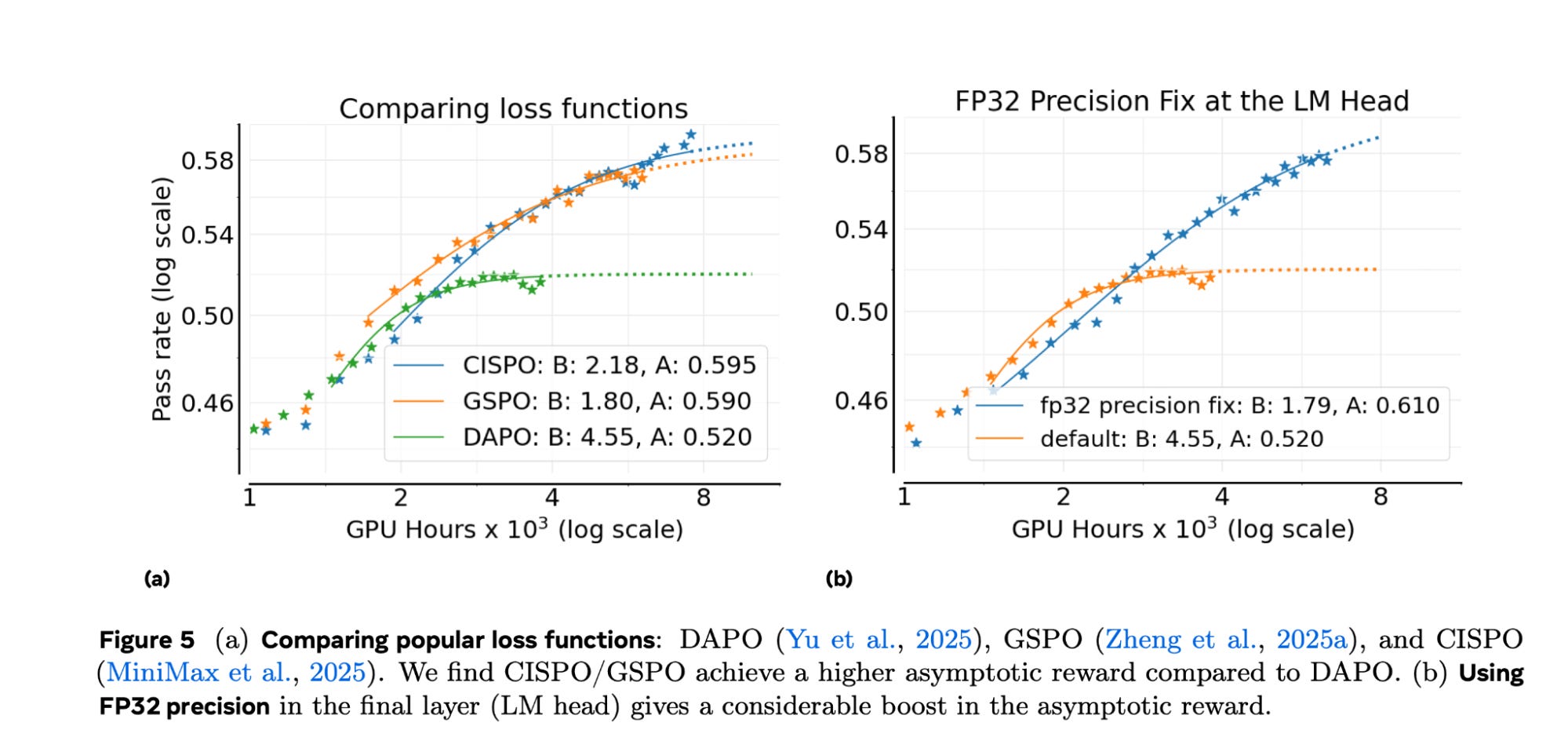
Ranks in the global top 5 on skills like math, science, and coding, and uses a scaling method called CISPO to achieve better efficiency.
A 2-week free trial for developers worldwide for a limited time.
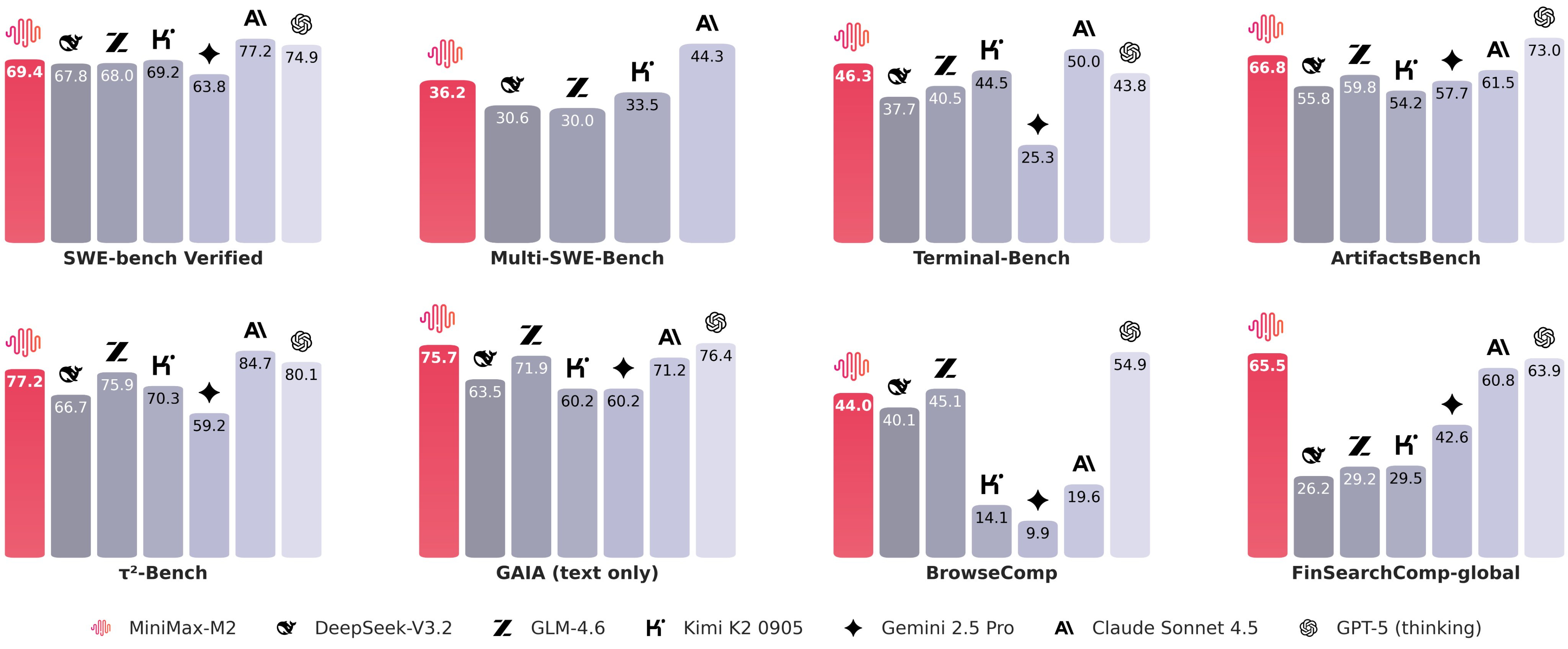
M2 is designed for real agent workflows, meaning it can edit multiple files, run code, debug, and fix tests automatically, which helps it perform well on benchmarks like Terminal-Bench and SWE-Bench.
It supports planning and executing tool chains across a shell, browser, Python, and Model Context Protocol (MCP) tools, allowing it to log evidence and self-correct during long runs.
On BrowseComp, it shows recovery skills similar to top commercial systems, while on Xbench-DeepSearch and FinSearchComp-Global, it ranks #2, showing strong multi-hop and financial search ability.
MiniMax’s scaling algorithm CISPO (featured in Meta’s “The Art of Scaling Reinforcement Learning Compute for LLMs”) underpins this efficiency.
Minimax M2 Ranked #2 globally on Xbench-DeepSearch (right after GPT-5) and #2 on FinSearchComp-Global (just behind Grok-4). M2 is purpose-built for multi-hop, domain-specific, and retrieval-heavy reasoning.
From shells to browsers to Python and MCP tools, M2 plans and executes complex toolchains autonomously—retrieving hard-to-find info, maintaining traceable evidence, and self-correcting as it goes.
In BrowseComp, M2 demonstrates deep reasoning and recovery ability comparable to top-tier proprietary models.
M2 handles full end-to-end development workflows: multi-file edits, code-run-debug loops, and automated test-based fixes. It performs exceptionally on Terminal-Bench and (Multi-)SWE-Bench, proving both benchmark and production value.
Availability:
- MiniMax API Access
- Available across Claude Code, Cursor, Cline, Kilo Code, Roo Code, Grok CLI, Gemini CLI, and more
📢 Today’s Sponsor: Luna from Pixa AI just launched - A leap forward in speech-to-speech model that feels like a human, with ultra-low latency (~600ms).

They trained on millions of hours of speech, music, and emotional dialogue, then compressed everything with an in-house neural codec called Candy. Resulted in a unified model that generates speech, soundscapes, and music in realtime. No silos—just seamless, immersive vibes.
Emotion-first expressiveness: Smooth shifts between playful, soothing, or empathetic tones.
Ultra-low latency (~600ms): Fluid, real-time conversation.
High-fidelity output: Really clear voice and immersive audio.
Unified generation: Speech, sound, and music from one model.
The big deal is fine control of melody, timing, and timbre in real time, so Luna can sing or speak with rhythm while still sounding like the same person.
Their codec (Candy) keeps fine timing and timbre details, which is why Luna can hold a melody and still sound like a person. Because the model is unified, it can switch between speech, soundscapes, and music in realtime, no brittle pipelines.
Luna sings naturally by generating audio tokens conditioned on content tokens plus a predicted F0 melody and beat grid, while a stable speaker embedding preserves timbre and cross attention aligns everything during streaming decoding.
Pixa is a voice AI research lab working on speech to speech foundational models. They are building these models focused on real connection, not just call-center automation.
Their internal evaluations claim Luna outperforms leading real-time systems, including OpenAI’s.
ASR WER (Automatic Speech Recognition Word Error Rate). It is the % of words the recognizer transcribes incorrectly, lower is better: Luna scored 5.24% WER (beats Deepgram Nova’s 8.38% & ElevenLabs’ 5.81%)
TTS WER: Luna got 1.3% (tops Sesame’s 2.9% & GPT-4o TTS’s 3.2%)
MOS Naturalness: (Mean Opinion Score for Speech Naturalness. It is a listener rating of how natural the speech sounds on a 1 to 5 scale, higher is better). Luna achieved 4.62 (edges out GPT-realtime’s 4.15)
🤝 OpenAI Completes For-Profit Transition, Pushing Microsoft Above $4 Trillion Valuation.

This is after months of talks with California and Delaware Attorneys General before approval. So OpenAI turned its for-profit subsidiary into a public-benefit corporation, of which Microsoft will own 27%. The conversion will grant OpenAI’s nonprofit parent a stake in the for-profit worth $130 billion, with the ability to get more ownership as the for-profit becomes more valuable.
Signed a new deal that keeps Microsoft as the exclusive cloud and API partner until an independent panel verifies OpenAI’s claim of AGI, while locking in Microsoft’s rights to OpenAI’s products and models through 2032. Microsoft now owns 27% of OpenAI Group PBC, a stake valued around $135B, which cements tight integration of OpenAI tech into Microsoft products while OpenAI gains more flexibility on partnerships.
Exclusivity ends after AGI is verified, but Microsoft keeps usage and ownership rights for everything built pre-AGI, and its rights also cover post-AGI models through 2032 with safety guardrails. OpenAI committed an extra $250B of Azure spend, and Microsoft dropped its right of first refusal to be OpenAI’s compute provider, which gives OpenAI room to shop for non-Azure compute in the future.
OpenAI can co-develop some products with other companies, keep API products exclusive to Azure, ship non-API products on any cloud, and even release some open-weight models that meet capability limits. Microsoft can pursue AGI on its own or with other partners, and if it uses OpenAI IP before AGI is declared, training runs are capped by large compute thresholds compared to today’s systems.
OpenAI can now provide API access to US national security customers regardless of cloud, and Microsoft’s IP rights exclude OpenAI’s consumer hardware. The nonprofit now called the OpenAI Foundation holds an about $130B stake in the for-profit OpenAI Group PBC. This setup lets the nonprofit keep strong influence over the for-profit arm.
The number can sit next to Microsoft’s stake, where Microsoft holds about 27% valued at about $135B, since both the Foundation and Microsoft can own different chunks at the same time. In practice, this means profits or exit proceeds would be split by ownership percentage, and board control or veto rights can be structured so the Foundation can push for safety and public-benefit goals.
🏆 Microsoft played so well with the OpenAI deal.

Microsoft now holds 27% worth $135B. Earlier Microsoft has invested $13.8 billion in OpenAI, so with Tuesday’s deal implying that Microsoft had generated a return of nearly ten times its investment.
Under the new capital structure, OpenAI Foundation owns 26%, the controlling non-profit that hires and fires the board. Employees + other investors: 47% combined.
Sam Altman: 0% equity.
And Microsoft’s IP rights for both models and products are extended through 2032 and now include models post-AGI. Microsoft’s IP rights to research, defined as the confidential methods used in the development of models and systems, will remain until either the expert panel verifies AGI or through 2030, whichever is first. Research IP includes, for example, models intended for internal deployment or research only.
Microsoft keeping OpenAI’s intellectual-property rights for both products and models through 2032 “is the most important aspect” of the revised agreement. Also, Microsoft remains entitled to receive 20% of OpenAI’s revenue until an independent expert panel verifies that AGI has been achieved.
🏭 Nvidia Reveals BlueField-4 DPU (Data Processing Unit), Packed With 64-Core Grace CPU For AI Data Centers.

A DPU, or Data Processing Unit, is a special type of processor made to handle the heavy data movement and network-related work inside a data center. It sits alongside CPUs and GPUs inside servers, but it takes care of things like networking, storage management, and security, which normally would use up CPU resources.
BlueField-4 sits on each server and offloads network, storage, and security so GPUs stay focused on token generation and inference. Designed to offload and accelerate networking, storage and security workloads from the server’s host CPU, BlueField-4 is set to debut in Nvidia’s Vera Rubin rack-scale platforms next year.
ConnectX-9 SuperNICs add ultralow-latency 800Gb/s Ethernet for Spectrum-X networks, optimizing RoCE and keeping performance consistent under load. Native DOCA microservices run as containers on the DPU and compose services via service function chaining, so teams layer networking, storage, telemetry, and firewalls without host changes.
Security relies on the Advanced Secure Trusted Resource Architecture for zero trust isolation and software-defined control independent of the host. Ecosystem support spans major server, storage, security, and cloud vendors, and current DOCA apps move to BlueField-4 unchanged with higher throughput.
Early availability lands in 2026 as part of NVIDIA Vera Rubin platforms. For trillion token workloads and heavy retrieval, shifting data and security off the host reduces CPU stalls, lowers tail latency, and returns more GPU time to generation. Partners like VAST Data are already running their entire storage stack directly on BlueField hardware.
🏛️ NVIDIA, Oracle, and the US Department of Energy will build Solstice with 100,000 Blackwell GPUs at Argonne plus Equinox with 10,000 Blackwell GPUs, aiming at 2,200 exaflops of AI performance for open science.

The US’s strong push—100,000 NVIDIA Blackwell GPUs—marks the beginning of agentic AI-based science at Argonne National Laboratory, available to public researchers.
These systems target large training and fast reasoning for research in areas like materials, climate, and biology, and they are framed as the DOE’s flagship AI infrastructure for public researchers. Solstice is positioned as the main engine, while Equinox is a smaller companion expected in H1-2026, giving teams a staged path to ramp workloads.
Training will rely on Megatron-Core, which is NVIDIA’s library for splitting giant models and data across many GPUs using tensor and pipeline parallelism so utilization stays high and training remains stable. Inference will rely on TensorRT, which compiles models into highly optimized kernels so latency drops and throughput rises, enabling interactive agents and large batch science jobs on the same cluster. Argonne’s tie-in to facilities like the Advanced Photon Source means models can sit close to instruments, analyze streams in real time, and trigger follow-ups without the usual data-movement delays.
That’s a wrap for today, see you all tomorrow.
https://arxiv.org/abs/2510.22115
Maybe also do a readout on this!