
🔥 Minimax Released World's First 4mn Context-Window Open-Sourced Model
MiniMax's 4mn-context LLM, Mistral's Codestral boost, Biden's datacenter order, ChatGPT's planner update, and Microsoft CoreAI—plus free Llama 3.3 and VFX upgrades.

Read time: 8 min 35 seconds
⚡In today’s Edition (14-Jan-2025):
🔥 MiniMax released world's first 4mn Context-window open-sourced model
🏆 Mistral AI launches Codestral 25.01 with 2x speed and a 95.3% FIM pass@1 score
📡 US President Biden signed an executive order opening federal land for development of gigawatt-scale datacenters
🛠️ ChatGPT’s unveiled new tasks feature transforming it into a handy planner for life’s recurring updates
Microsoft released big improvements in AutoGen, a very popular open source agentic framework
🗞️ Byte-Size Brief:
Together offers free Llama 3.3 70B model, rivaling 405B version.
AI firms pay $1-4/minute for influencer footage to train models.
Microsoft launches CoreAI division to unify AI platform, tools, and Copilot.
Adobe unveils TransPixar, enhancing VFX with realistic transparency effects.
🔥 Minimax Released World's First 4mn Context-Window Open-Sourced Model
🎯 The Brief
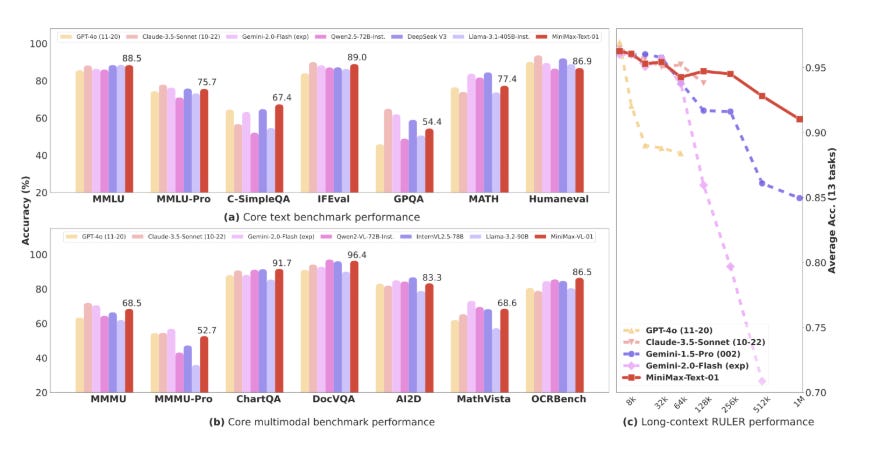
MiniMax released the MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, as open-source models to redefine long-context processing. With an unprecedented 4 million tokens context window for inference, it leverages a lightning attention mechanism and a Mixture of Experts (MoE) architecture. This innovation ensures efficiency with 456 billion parameters while activating only 45.9 billion per token. It rivals top-tier models like GPT-4o in both text and multi-modal tasks while offering 20-32x longer contexts.
⚙️ The Details
→ The MiniMax-01 series includes MiniMax-Text-01 for text-based tasks and MiniMax-VL-01 for vision-language capabilities. Both models have been open-sourced with a clear focus on advancing AI agent systems.
→ The standout feature is lightning attention, an optimized linear attention implementation, combined with a hybrid design using softmax attention every 8th layer to boost retrieval and extrapolation.
→ The model integrates 32 experts within an MoE architecture, balancing 456 billion total parameters to maintain performance with reduced computation.
→ MiniMax's long-context benchmarks, including Needle-In-A-Haystack retrieval, show 100% accuracy even with 4 million tokens. Performance remains on par with leading models in NLP and multi-modal tasks.
→ The MiniMax API offers very competitive pricing at $0.2 per million input tokens and $1.1 per million output tokens. Accessed the model here https://github.com/MiniMax-AI
→ MiniMax-01 is poised to support the anticipated surge in agent-related applications in the coming years, as agents increasingly require extended context handling capabilities and sustained memory.
How the ultra-long context window of 4 million tokens of the MiniMax-01 is achieved.
Read their detailed 68-page technical report here.
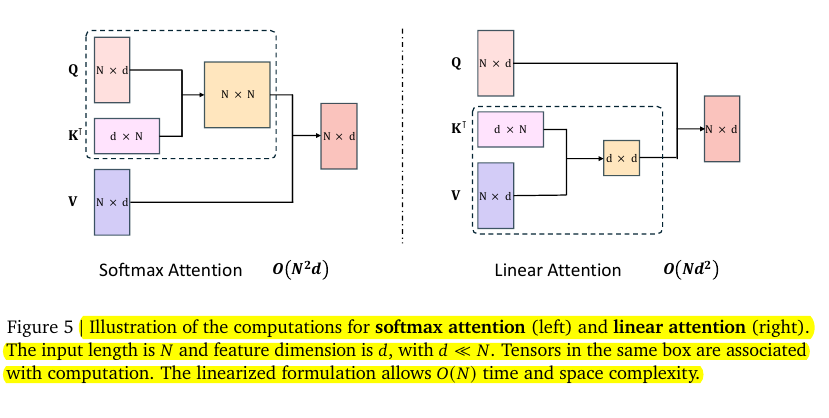
Lightning Attention is key to achieving the 4-million-token context window. It avoids the usual softmax structure by using a linear formulation that scales in proportion to sequence length. Traditional softmax attention grows computationally in a quadratic fashion, making it infeasible for ultra-long sequences.
→ They implemented a hybrid architecture combining linear and softmax attention, supported by innovative computation techniques.
Most layers use linear attention, but some layers keep softmax attention. This arrangement ensures the model still handles retrieval tasks while benefiting from lightning attention's efficiency. Without any softmax blocks, the model would struggle to recall specific parts of the input.
→ Varlen Ring Attention handles varying sequence lengths without large overhead. It applies a ring-based algorithm that divides sequences into segments. This design keeps the context window open-ended, so each segment can connect seamlessly while skipping unneeded computation.
→ LASP+ (Linear Attention Sequence Parallelism) removes bottlenecks caused by splitting the sequence across multiple GPUs. It optimizes the communication of partial intermediate states, turning serial steps into parallel tasks. This permits the model to process million-token sequences efficiently.
→ Efficient Kernels and Fused Operations reduce memory transfers. By merging multiple smaller memory-bound operations into a single pass, the system makes better use of GPU capacity. This is vital for huge context windows, where memory speed becomes a limiting factor.
→ Mixture of Experts (MoE) distributes large feed-forward components across parallel groups. By swapping tokens between these experts only when necessary, the model saves memory and bandwidth. This setup enables scaling up to massive token lengths without hitting hardware limits.
🏆 Mistral AI launches Codestral 25.01 with 2x speed and a 95.3% FIM pass@1 score
🎯 The Brief
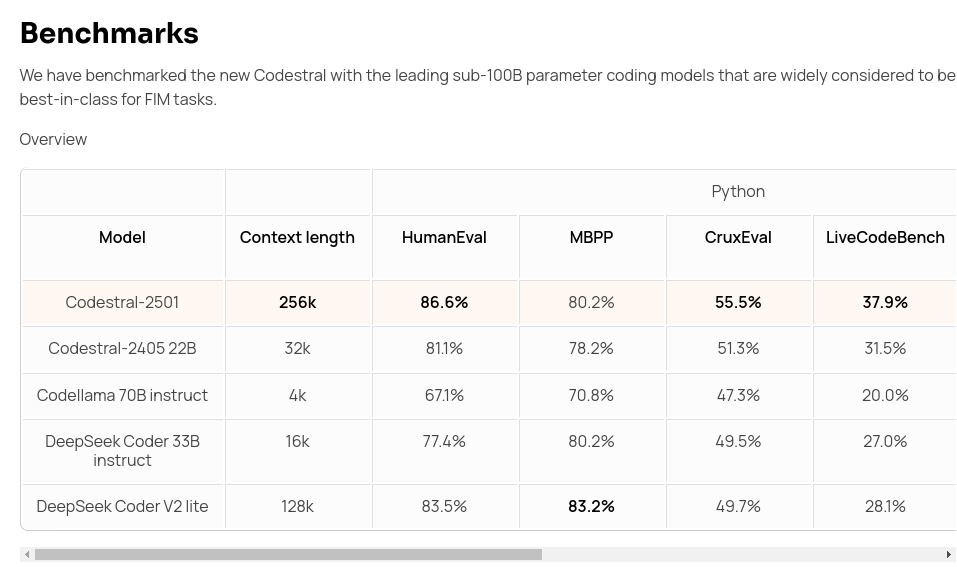
Mistral AI has released Codestral 25.01, a next-generation code generation model designed to improve developer productivity through faster and more precise code completion. This model excels in fill-in-the-middle (FIM) tasks, surpassing competitors with an average FIM pass@1 score of 95.3%, making it a significant upgrade over its predecessor and models like Codellama 70B and GPT-3.5 Turbo.
⚙️ The Details
→ Codestral 25.01 features an upgraded architecture and tokenizer, making it twice as fast as the previous version, Codestral 2405. It supports over 80 programming languages and is highly optimized for low-latency, high-frequency usage in tasks like code correction, FIM, and test generation.
→ Benchmark results show 86.6% on Python HumanEval and 87.96% on JavaScript FIM tests, outperforming larger models.
→ The model is available via Google Cloud Vertex AI and IDE plugins for VS Code and JetBrains, with broader platform support coming soon, including Azure AI Foundry and Amazon Bedrock.
→ Enterprise users can deploy the model locally via Continue.dev for VPCs and on-premises use, ensuring privacy and scalability.
📡 US President Biden signed an executive order opening federal land for development of gigawatt-scale datacenters

🎯 The Brief
The U.S. government has issued an executive order to fortify domestic AI leadership by building secure, clean-powered AI infrastructure, including data centers and energy systems, to enhance national security, economic competitiveness, and supply chain independence. This initiative mandates rapid development timelines and ensures that AI advancements are not reliant on foreign resources.
⚙️ The Details
→ The executive order mandates the development of AI infrastructure, including AI data centers, powered by clean energy such as nuclear, solar, wind, geothermal, and long-duration storage. It aims to have frontier AI data centers operational by 2027 on federal sites.
→ To prevent foreign dependencies, AI infrastructure projects must follow strict security guidelines covering cyber, supply chain, and physical security. Companies must report on any foreign capital involved.
→ The government requires federal agencies to identify at least three suitable federal land sites per department for AI centers and clean energy facilities. These sites must meet criteria such as proximity to transmission infrastructure and community approval.
→ Companies must finance infrastructure costs, including grid upgrades and environmental reviews, without increasing local consumer electricity costs.
→ Internationally, the U.S. plans to collaborate with allies on global AI infrastructure development, emphasizing secure, clean power deployment and best practices in permitting and innovation.
🛠️ ChatGPT’s unveiled new tasks feature transforming it into a handy planner for life’s recurring updates

🎯 The Brief
OpenAI has introduced a new "tasks" feature in ChatGPT for Plus, Team, and Pro users, enabling them to schedule reminders and recurring requests globally. For the first time, ChatGPT can manage tasks asynchronously on your behalf—whether it's a one-time request or an ongoing routine.
⚙️ The Details
→ Users can create reminders, like “Remind me when my passport expires,” and receive notifications on any enabled platform.
→ Recurring requests include daily news briefings and weekend plans customized by location and weather.
→ Tasks are accessible via the web app by selecting "go with scheduled tasks" and interacting through a dedicated tab or regular chats.
→ The feature allows scheduled web browsing but not continuous background searches or purchases, ensuring a controlled, limited autonomy. You can delegate ChatGPT to write new scifi stories in Canvas on a regular basis and get those in your inbox likes small tiny gifts!
→ Tasks do not yet support Advanced Voice Mode and are currently unavailable in the mobile app.
→ This feature signals OpenAI’s move toward more advanced AI systems like the rumored "Operator," designed for tasks like code writing and travel bookings.
→ OpenAI aims to refine tasks through user feedback before expanding it to the free tier and mobile platforms.
Microsoft released big improvements in AutoGen, a very popular open source agentic framework

🎯 The Brief
Microsoft released AutoGen v0.4, a complete redesign of the agentic AI framework that improves scalability, modularity, and debugging with an asynchronous, event-driven architecture. This update addresses user-reported limitations, enhances multi-agent collaboration, and adds cross-language support starting with Python and .NET, enabling more robust, distributed agentic workflows.
⚙️ The Details
→ The asynchronous messaging system allows agents to communicate using both event-driven and request/response patterns, supporting long-running and proactive tasks.
→ A modular architecture introduces pluggable components, letting users customize agents, tools, and memory while supporting complex distributed networks.
→ Debugging tools include built-in metric tracking, message tracing, and support for OpenTelemetry, improving observability and control over agent workflows.
→ The new AutoGen Studio enables rapid agent prototyping with features like real-time updates, mid-execution control, message flow visualization, and a drag-and-drop team builder.
→ Magentic-One is introduced as a generalist multi-agent system capable of solving a range of open-ended web and file-based tasks.
→ The new framework retains familiar APIs like AgentChat for ease of migration while adding support for streaming messages, pausing tasks, and restoring progress.
→ Future plans include expanded language support, improved first-party applications, and fostering a community-driven extension ecosystem.
🗞️ Byte-Size Brief
🦙 Llama 3.3 70B is now available on Together AI for free! The new 70B model delivers similar capabilities to the much larger Llama 3.1 405B model, with improved reasoning 🤔, math ➕➖, and instruction-following 🧠.
AI companies are paying content creators for their unpublished videos (between $1 and $4 per minute of footage), to train AI models, creating a new revenue stream for YouTubers and digital influencers.
Microsoft announced a new CoreAI division, integrating key engineering teams, to unify its AI platform and developer tools, focusing on accelerating development of its end-to-end Copilot stack and agentic applications.
Adobe’s TransPixar takes AI VFX to the next level. TransPixar’s transparency effects replace static visuals in AI-generated videos with realistic smoke, reflections, and glass, blending seamlessly into scenes. It extends existing video models using custom alpha-channel tokens and LoRA-based tuning, enabling impressive results with limited training data.