
🏆 MiniMax's M2.1 is out now, the absolute best scoring open-source model
MiniMax drops M2.1 (top open-source scores), Poetiq hits 75% ARC-AGI-2 with GPT-5.2 Pro , xAI ships Grok Collections API, plus prompt-injection risks and Meta’s PE-AV.
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-Dec-2025):
🏆 MiniMax’s M2.1 is out now, the absolute best scoring open-source model.
👏 Poetiq with GPT-5.2 Pro with x-High reasoning effort, reported 75% on ARC-AGI-2 on the public evaluation set for under $8 per task, about 15pp above the prior public-eval best.
⚡ xAI just launched the Grok Collections API
🌐 OpenAI’s new study says AI-powered browsers could always remain vulnerable to prompt injection attacks.
🛠️ The U.K.’s National Cyber Security Centre also warned that prompt injection attacks against generative AI apps may never be fully eliminated.
👨🔧 Meta open-sourced Perception Encoder Audiovisual (PE-AV)
🏆 MiniMax’s M2.1 is out now, the absolute best scoring open-source model.
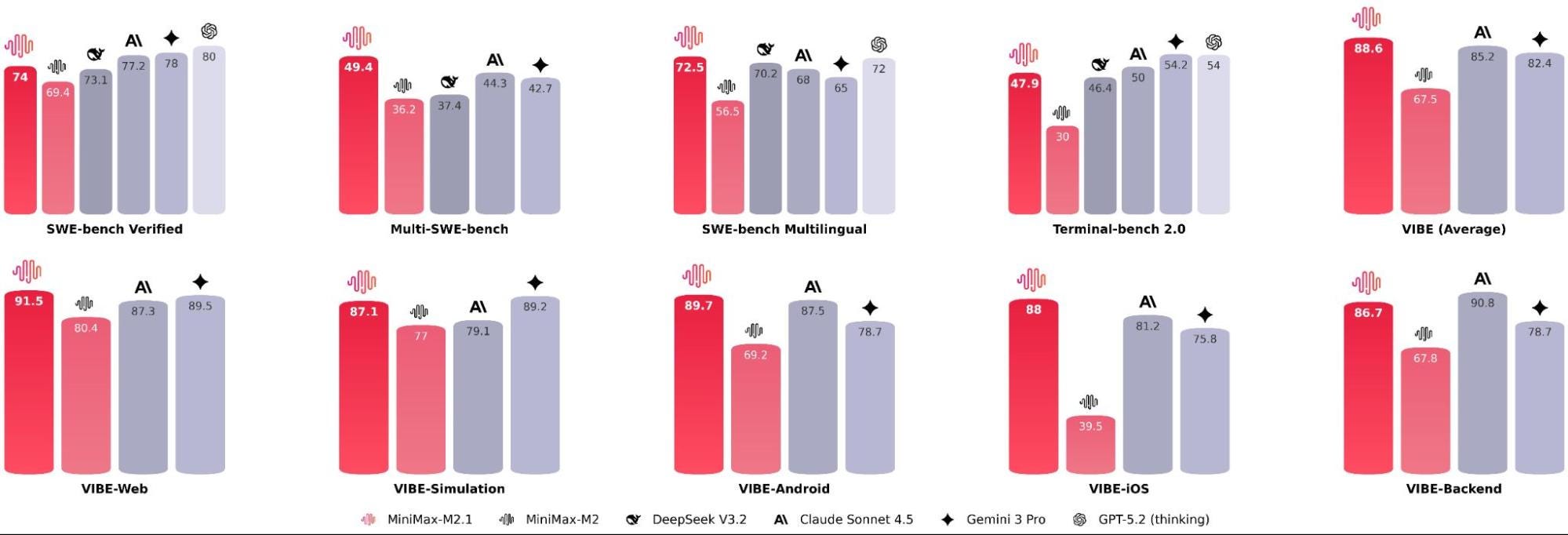
MiniMax released MiniMax M2.1, and it’s a serious attempt to build an AI-native, real-world programming engine — one that works across languages, tools, agents, and the messy constraints of the office. devs are calling it Claude vibes for 10% of the bill.
Its a 10B-activated Multi-language Coding & Agent focused SOTA model, exceeding many leading closed-source models.
Multi-language Coding SOTA: 72.5% on SWE-Multilingual (exceeds Claude Sonnet 4.5 and Gemini 3 Pro), with systematic improvements across Rust / Java / Golang / C++ / Kotlin / Objective-C / TypeScript / JavaScript
AppDev & WebDev: Major upgrades for native Android & iOS development, plus stronger web aesthetics + realistic scientific simulations. Scoring 88.6% on VIBE-Bench — exceeding Claude Sonnet 4.5 and Gemini 3 Pro
Its the first OSS model series with systematic Interleaved Thinking. It lets MiniMax M2 save and update its plan after each action, keeping it on track, fixing mistakes, and finishing complex tasks reliably.
Excels at integrating “composite instruction constraints” (as seen in OctoCodingBench), ready for office automation tasks.
Faster responses, more concise reasoning, and significantly reduced token consumption compared to M2
M2.1 demonstrates excellent performance across various coding tools and Agent frameworks — consistent and stable results in Claude Code, Droid (Factory AI), Cline, Kilo Code, Roo Code, BlackBox, and more. It also provides reliable support for Context Management mechanisms like Skill[.]md, Claude[.]md / agent[.]md / cursorrule, and Slash Commands.
M2.1 is no longer just “better at coding” — it also provides more detailed and well-structured answers in everyday conversations, technical documentation, and writing scenarios.
Multilingual coding that actually holds up in real projects
Agent-level tool use for long, autonomous workflows
A true digital employee for complex office tasks
Used it for a few hours already, and it’s seriously impressive.
M2.1 can create production-grade and visually refined projects, e.g. a native Android App with smooth motion and playful UI effects, a minimalist and clean homepage using asymmetric design, or an elegant landing page for any brand with a clean and modern aesthetic.
The agentic features feel way ahead, and the generated deep research report quality really shows it.
How to Use
The MiniMax-M2.1 API is now live on the MiniMax Open Platform: https://platform.minimax.io/docs/guides/text-generation
All Coding Plan packages are equipped with the MiniMax M2.1 model:
Its product MiniMax Agent, built on MiniMax-M2.1, is now publicly available:
👏 Poetiq with GPT-5.2 Pro with x-High reasoning effort, reported 75% on ARC-AGI-2 on the public evaluation set for under $8 per task, about 15pp above the prior public-eval best.

On the more controlled “verified” ARC-AGI-2 evaluation, OpenAI reports GPT-5.2 Pro at 54.2%, so Poetiq’s 75% is not a claim about the base model alone, it is a claim about a scaffolded system on a public set. Poetiq’s own description of the wrapper is an iterative loop that gets the model to propose a concrete solution, check it against feedback, refine it, and stop early via self-auditing to keep the number of model calls low. The Poetiq ARC-AGI solver guides the underlying model (GPT-5.2 in this case) to write code that can solve each individual problem, then runs that code, checks it for correctness, corrects the code if it’s wrong, and then combines multiple independent runs like that to gain confidence in the final response.
⚡ xAI just launched the Grok Collections API

Earlier RAG setups often break on long, dense docs because chunking loses structure, and retrieval misses the exact table cell, clause, or code symbol the answer depends on. Collections says it uses optical character recognition (OCR) plus layout-aware parsing so extracted text keeps structure like PDF layout, spreadsheet hierarchy, and code syntax.
On retrieval, it offers semantic search for meaning, keyword search for exact terms, and hybrid search that combines both with either a reranker model or reciprocal rank fusion. Pricing: Free first week of indexing & storage, then $2.50 / 1K searches.
Grok Collections beat Gemini 3 Pro and GPT-5.1 on key retrieval tasks, pulling more accurate context from documents during search. It also states user data stored on Collections is not used for model training unless the user consents. This looks most useful for product teams that want reliable table, contract, and code lookups without building infra, but the strongest numbers are labeled internal, so external replication will matter.
So whats the difference with the regular API ?
The regular Grok API is mainly “give the model a prompt, get text back,” while the Collections API is “store your files, search them, then have Grok answer using what was found.” With the regular Grok API, if you want the model to use your documents, you typically paste the relevant text into the prompt each time or you build your own retrieval-augmented generation (RAG) layer that searches your docs first.
Collections is that RAG layer packaged as a managed service, where you upload files once, it parses them, indexes them, and later you run searches against the collection. It explicitly focuses on messy enterprise formats, using optical character recognition (OCR) plus layout-aware parsing so the index keeps structure from PDFs, spreadsheets, and code instead of flattening everything into plain text.
🌐 OpenAI’s new study says AI-powered browsers could always remain vulnerable to prompt injection attacks.

So their Atlas is adding automated reinforcement learning red teaming to find and patch exploits faster. Prompt injection is hidden text that tries to override the user’s instructions and hijack the agent.
Atlas agent mode can view pages and take clicks and keystrokes, so untrusted content can steer real actions inside the browser. OpenAI compares this to scams and social engineering, and does not expect a complete fix.
Its automated attacker is a large language model (LLM) trained with reinforcement learning (RL) by rewarding successful injections end-to-end. The attacker can test a candidate injection in a simulator that returns the victim agent’s reasoning and action trace.
That richer feedback helps it craft multi-step exploits over 10 to 100+ actions, beyond older bots that mainly force a string or a single tool call. One found exploit seeds the inbox with a malicious email so the agent sends a resignation note instead of an out-of-office reply.
OpenAI says it rolls these attacks into adversarial training plus broader safeguards, then ships an updated agent model quickly. Overall, agentic browsers live in a difficult space, combining some autonomy with a lot of access. So the general recommendations is to aim to reduce exposure by limiting logged-in access and slowing things down with confirmation checks.
🛠️ The U.K.’s National Cyber Security Centre also warned that prompt injection attacks against generative AI apps may never be fully eliminated.

SQL injection works by smuggling attacker text into a language where the engine has a real instruction versus data boundary, so parameterized queries can force inputs to stay data. Inside an LLM prompt there is no built-in “this part is code” marker, only token-by-token prediction, so untrusted text can steer behavior instead of just being processed.
That makes indirect prompt injection especially nasty, because the attacker can hide instructions in emails, documents, web pages, or tool outputs that the model later reads and follows. OWASP now lists prompt injection as the top LLM risk, which is a signal that it shows up across many real app designs.
A safer mental model is confused deputy, where the model can be coaxed into spending the app’s privileges, so defenses should clamp tools, data access, and side effects with deterministic checks. Microsoft’s guidance also leans on defense-in-depth, including clearly separating untrusted content and monitoring tool calls for suspicious sequences.
👨🔧 Meta open-sourced Perception Encoder Audiovisual (PE-AV)

so the same backbone can do cross-modal search in any direction with just dot products. Older audio-text or video-text encoders often align only 2 modalities well, so cross-modal queries like “find the video for this sound” can be brittle or domain-limited.
PE-AV extends Meta’s Perception Encoder (PE) stack with explicit audio, video, and fused audio-video towers, plus text projections that are specialized for different query pairings. On the audio side it uses a DAC-VAE (discrete audio codec variational autoencoder) to turn waveforms into tokens at about 40ms steps, then learns fusion features that can be matched with dot products against audio, video, or text embeddings.
To get captions at scale, the paper describes a 2-stage pipeline where an LLM merges weak audio captioners and video captioners into 3 caption types, then a Perception Language Model (PLM) style decoder helps refine them for tighter audio-visual correspondence. Empirically, it shows up as large jumps on broad benchmarks like AudioCaps R@1 35.4 to 45.8 and VGGSound accuracy 36.0 to 47.1, plus smaller but real gains on video like Kinetics-400 76.9 to 78.9.
That’s a wrap for today, see you all tomorrow.