
🥉Mistral dropped new Multilingual LLM, Mistral AI Small 24B, With Apache 2.0 License and Matching Top Open Models

Read time: 8 min 56 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Jan-2025):
🥉Mistral dropped new Multilingual LLM, Mistral AI Small 24B, With Apache 2.0 License and Matching Top Open Models
🏆 Tülu 3 405B is released, surpassing DeepSeek-V3 and on par with GPT-4o, fully open-source data, code, and recipes.
📡 Microsoft is rolling out “Think Deeper” to free Copilot Users with access to OpenAI’s o1 model
🗞️ Byte-Size Briefs:
ExaAILabs launches DeepSeek R1-powered web researcher, fully open-source.
OpenAI’s o1 ranks #1, DeepSeek-R1 #9 on AidanBench creativity test.
🧑🎓 Deep Dive Tutorial
🖥️ Using Qwen2.5-VL for Computer Use/Desktop Interaction
🥉Mistral dropped new Multilingual LLM, Mistral AI Small 24B, With Apache 2.0 License and Matching Top Open Models

🎯 The Brief
Mistral AI has released Mistral Small 3, a 24B parameter open-source model under Apache 2.0. It achieves 81% accuracy on MMLU and delivers 150 tokens/s, making it 3x faster than Llama 3.3 70B on the same hardware. Designed for low-latency, high-efficiency inference, it competes with larger models like Qwen 32B and GPT4o-mini while remaining lightweight enough for local deployment.
⚙️ The Details
→ 32k context window. Running Mistral-Small-Instruct-2501 on GPU requires 60 GB of GPU RAM. Utilizes a Tekken tokenizer with a 131k vocabulary size.
→ Mistral Small 3 is optimized for real-time inference, having fewer layers than competitors, ensuring fast forward passes. Instruct version support function calling
→ Unlike some competitors, it is not trained with RL or synthetic data, making it ideal as a base model for fine-tuning.
→ It supports local inference, running efficiently on RTX 4090 or Macbook (32GB RAM), making it accessible for hobbyists and privacy-sensitive applications.
→ Enterprise use cases include fraud detection (finance), customer triaging (healthcare), virtual assistants, and on-device command execution (robotics, automotive).
→ Available on Hugging Face, Kaggle, Ollama, Fireworks AI, and Together AI, with upcoming support for NVIDIA NIM, Amazon SageMaker, Groq, Databricks, and Snowflake.
→ Mistral AI reaffirms its commitment to Apache 2.0 licensing, moving away from MRL licensing, ensuring full model access, modification, and commercial use.
Running Mistral-Small-24B-Instruct-2501
1. Install Dependencies
pip install --upgrade vllm mistral_common2. Run as a Server
vllm serve mistralai/Mistral-Small-24B-Instruct-2501 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice3. Call API (Python)
import requests, json
url = "http://<your-server>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-24B-Instruct-2501"
messages = [{"role": "user", "content": "Give me 5 ways to say 'See you later' in French."}]
data = {"model": model, "messages": messages}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])4. Run Locally (Offline)
from vllm import LLM
from vllm.sampling_params import SamplingParams
llm = LLM(model="mistralai/Mistral-Small-24B-Instruct-2501", tokenizer_mode="mistral", tensor_parallel_size=8)
messages = [{"role": "user", "content": "Give me 5 ways to say 'See you later' in French."}]
sampling_params = SamplingParams(max_tokens=512, temperature=0.15)
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)5. Run with Ollama
ollama run mistral-small
ollama run mistral-small:24b-instruct-2501-q4_K_M # 4-bit quantization🏆 Tülu 3 405B is released, surpassing DeepSeek-V3 and on par with GPT-4o, fully open-source data, code, and recipes.
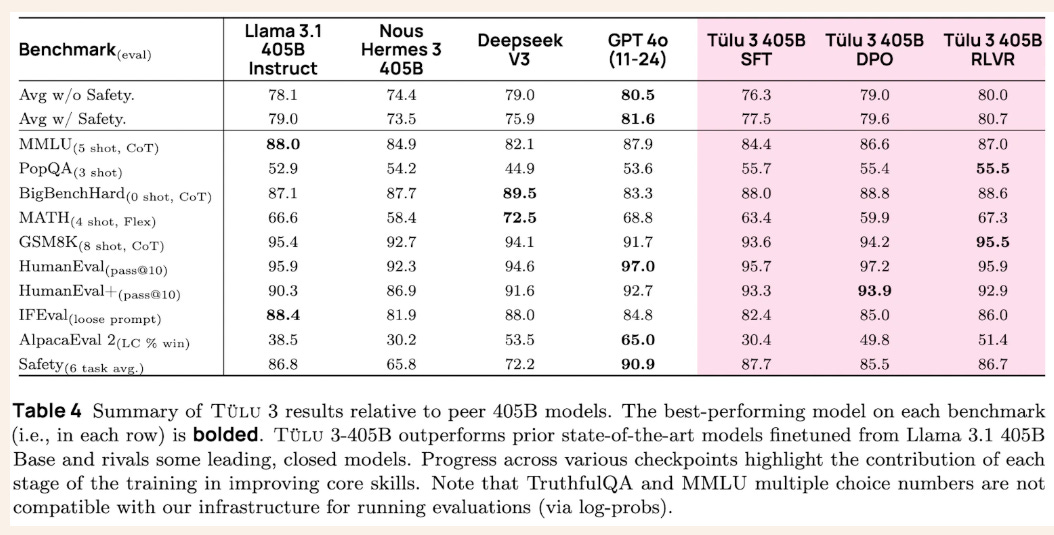
🎯 The Brief
Allen Institute for AI (Ai2) has dropped Tülu 3 405B, surpassing DeepSeek-V3 and performing on par with GPT-4o. It outperforms Llama 3.1 405B Instruct and Nous Hermes 3 405B in key benchmarks. The model scales Reinforcement Learning from Verifiable Rewards (RLVR), significantly improving MATH performance at 405B parameters, more so than at 70B or 8B. Permissive License with Llama 3.1 Community License Agreement.
⚙️ The Details
→ Tülu 3 405B is built using Llama 3 405B as a base and follows a structured post-training recipe, including Supervised Finetuning (SFT), Direct Preference Optimization (DPO), and RLVR.
→ RLVR (Reinforcement Learning with Verifiable Rewards) is a method to train LLMs on tasks with verifiable outcomes, like math problem-solving and instruction following. It assigns scalar rewards and updates the model policy using prompts, completions, and these rewards. RLVR scales efficiently at 405B using vLLM with 16-way tensor parallelism and 240 GPUs, optimizing performance through improved weight synchronization.
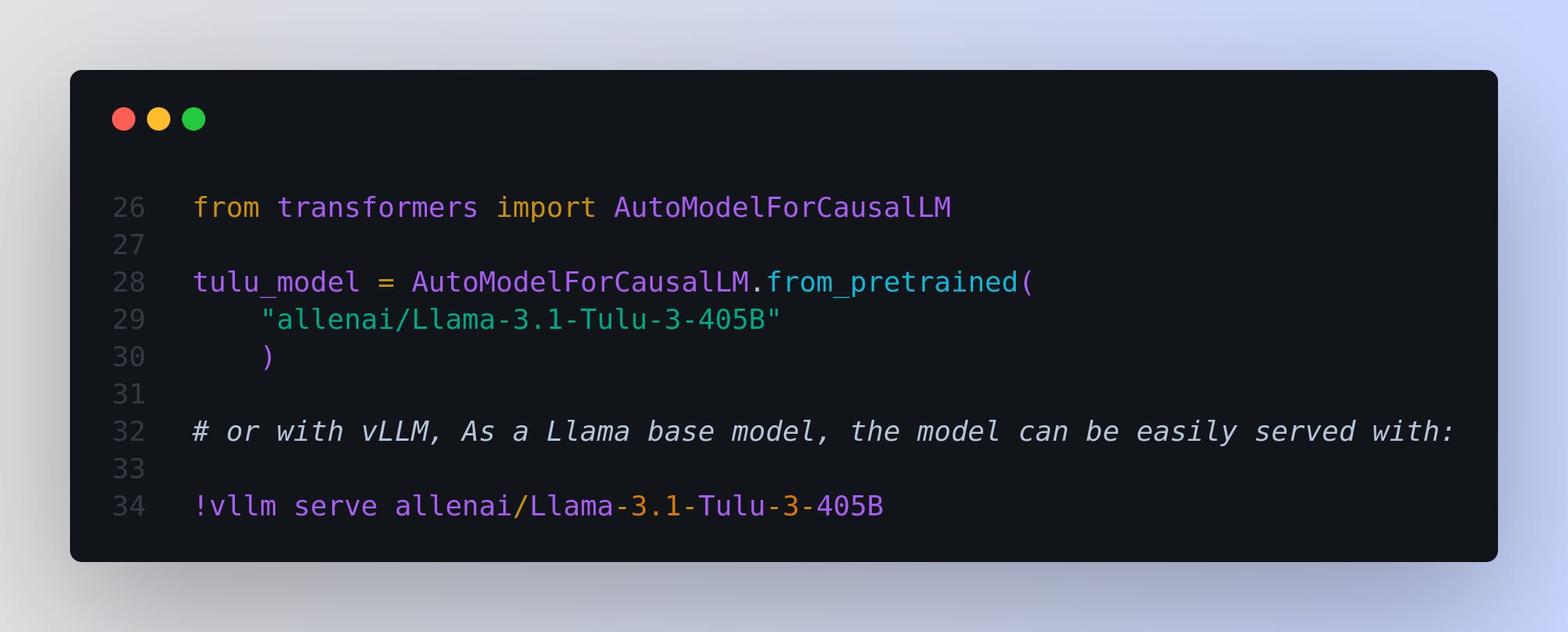
→ Deployment is on Google Cloud's Vertex AI, and the model is available on Hugging Face and Ai2 Playground. Below is an example code for using the model.
📡 Microsoft is rolling out “Think Deeper” to free Copilot Users with access to OpenAI’s o1 model

🎯 The Brief
Microsoft has expanded its "Think Deeper" feature in Copilot to free users on Android, iOS, and the web. Initially a Copilot Pro exclusive, this feature enables advanced reasoning using OpenAI's o1 model, providing step-by-step responses for complex tasks. However, free-tier users are limited to 3 queries per week, while Pro users have variable limits based on server load. The feature does not have real-time web access, relying on knowledge up to October 2023.
⚙️ The Details
→ "Think Deeper" is ideal for math problems, coding challenges, scientific analysis, and scenario planning. Free users get 3 queries per week, while Copilot Pro users have a dynamic cap (~50 per week) based on server demand. Checkout here.
→ Performance tests showed Think Deeper significantly improves response quality, integrating all prompt details instead of providing generic answers. Despite longer processing times, its ability to infer unstated needs makes it superior for structured reasoning tasks.
🛠️ DeepSeek R1 671B param model is now available on Azure AI Foundry and GitHub

🎯 The Brief
DeepSeek R1 is now available on Azure AI Foundry and GitHub, joining a catalog of 1,800+ AI models.
⚙️ The Details
→ Try, compare, and implement DeepSeek R1 671B in your code in the playground or via the API. Compare it to other models using side-by-side comparisons in GitHub Models.
→ Developers can access an inference API within minutes and test prompts in a playground. Microsoft also plans to offer distilled versions of DeepSeek R1 that can run locally on Copilot+ PCs,
→ Security features include red teaming, automated model behavior assessments, and compliance monitoring, ensuring safe and responsible AI deployment.
→ The model is available via a serverless endpoint, enabling quick deployment.
Click Model: Select a Model at the top left of the page.
Alternatively, in the dropdown menu, click View all models, click a model in the Marketplace, then click Playground.
🗞️ Byte-Size Briefs
ExaAILabs made a DeepSeek R1 powered web researcher. Fully free and open source, try it here. It uses Exa's API for web search and Deepseek R1 LLM for reasoning.
OpenAI's o1 is ranked at #1 and DeepSeek-R1 is at #9 on AidanBench.
AidanBench tests how creative and flexible a large language model (LLM) can be when answering open-ended questions. It measures how many unique and coherent answers an LLM can generate for a given question before it starts repeating itself or producing nonsensical output. Essentially, it gauges an LLM's ability to think outside the box and sustain creative thought. Aidenbench is highly correlated to model performance in agentic uses, because it measures diversity of generation, which is key to best-of-N performance and fully sampling the space of possible strategies to any given problem.
🧑🎓 Deep Dive Tutorial
🖥️ Using Qwen2.5-VL for Computer Use/Desktop Interaction

Qwen 2.5 VL is a Vision Language Model that can control your computer, similar to the @OpenAI operator, extract structured information from charts, and more!
It can recognize objects, text, and layouts within screenshots, allowing it to interpret what's displayed on the desktop.
Query processing: Users can ask questions about the screen content, like "What is the name of the document currently open?" or "Where is the 'Save' button?".
Action execution: Depending on the integration, it could potentially trigger basic actions like clicking on specific buttons or navigating to a particular file based on visual identification.
Contextual awareness: By analyzing the surrounding visual elements, Qwen2.5-VL can provide more relevant responses to queries.
This notebook showcases how to use Qwen2.5-VL to analyze a screenshot of a user's desktop based on a given query. This allows Qwen2.5-VL to assist users in real-time by understanding and responding to their on-screen environment.
The notebook demonstrates capturing a screenshot of your desktop, passing that image (and your text query) to Qwen2.5-VL, and returning an action coordinate that is visually overlaid on the image. The core workflow is:
Load and resize the screenshot.
Encode it (for API) or feed it directly (for local model).
Build a message containing the screenshot and query.
Send the request to the model.
Receive a JSON-like response, parse the “coordinate” value, and overlay a point on the image to indicate the UI element to be clicked or opened.
1. Setup
First, install the required dependencies:
!pip install git+https://github.com/huggingface/transformers
!pip install qwen-vl-utils qwen-agent openaiSet the DashScope API key to enable model inference:
import os
os.environ['DASHSCOPE_API_KEY'] = "your_api_key"2. Loading and Processing a Screenshot
The notebook does not include code for capturing screenshots. It assumes the image is preloaded and uses Qwen2.5-VL for computer screen understanding.
from PIL import Image
img = Image.open("screenshot.png") # Load an existing screenshotIf the model needs to highlight a detected UI element, a function is provided to draw a colored marker on the image.
3. Running Qwen2.5-VL on the Screenshot
The Qwen2.5-VL model is loaded and used for inference:
from qwen_agent import QwenVL
model = QwenVL(model_name="Qwen/Qwen2.5-VL")
query = "What application is open in this screenshot?"
output = model.infer(image=img, query=query)
print(output)The image (screenshot) and query are passed to the model.
The model returns a textual description of what is on the screen.
4. Highlighting Important Areas
Defining a utility function to annotate images. If the model detects UI elements like a button or an icon, the notebook includes a function to mark that position: :
def draw_point(image, point):
from PIL import ImageDraw
draw = ImageDraw.Draw(image)
draw.ellipse([point[0]-10, point[1]-10, point[0]+10, point[1]+10], fill="red")
return image
highlighted_img = draw_point(img, [200, 300])
highlighted_img.show()This function marks a detected point on the screenshot.
That’s a wrap for today, see you all tomorrow.