
ML Case-study Interview Q: Optimizing Payment Authorization Success Using Contextual Multi-Armed Bandits


Optimizing Payment Authorization Success Using Contextual Multi-Armed Bandits
Case-Study question
A large multinational offers payment services to thousands of businesses. They want to increase the probability that each initiated payment ends in a successful authorization. Multiple optimizations can be applied in the background (for example, deciding whether to enforce an authentication flow, formatting certain message fields, or instantly retrying a payment). The old solution used fixed A/B tests for each optimization. That approach had limitations when analyzing more nuanced payment features like card type, bank, or transaction amount. Real-world changes sometimes made the A/B outcomes obsolete, forcing frequent re-tests.
They now want a system that dynamically chooses the best optimization for each payment, using incoming payment features (contexts) and gathering real-time feedback (rewards). Your task: design a solution that automatically explores different options (actions) whenever uncertainty is high, but consistently exploits the best-known action when confidence in its success probability is high. Provide a thorough approach for modeling, training, and deploying this system in a production environment with low-latency constraints.
Explain how you would:
Identify the modeling strategy to map from payment context to success probability.
Manage the exploration vs. exploitation trade-off with a suitable multi-armed bandit approach.
Handle model training, validation, and real-time serving.
Evaluate results and react when the environment changes.
Ensure solutions scale without memory or latency bottlenecks.
Proposed detailed solution
Starting with a conceptual approach: treat each incoming payment as a separate round in a contextual multi-armed bandit environment. The context is the set of features describing the payment (for example, card type, transaction amount, bank). The action is the chosen optimization (for example, enforce authentication or skip it, or any other relevant optimization). The reward is a binary outcome (0 if authorization fails, 1 if it succeeds).
Use a classifier to estimate the probability of success for each (context, action). A gradient boosting model (like XGBoost) is a good candidate, given it efficiently handles mixed numeric and categorical features. Collect training data from historical payments or from real-time feedback loops. For the real-time feedback, log which action was chosen and its resulting reward.
Keep the following core objective in mind.
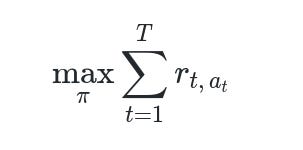
Where T is the number of payment attempts. r_{t, a_t} indicates the reward for action a_t at time t. The policy pi (π) defines how you map the payment context to an action.
When training the model, represent each optimization with a dedicated feature set (for instance, a one-hot vector showing which optimizations were chosen in the past). Combine this with other payment features (card type, issuer, user country, etc.). Use that to predict the probability of success. Adjust for any data imbalance by carefully weighting or sampling the data. Retrain periodically so the model adapts to shifting real-world behaviors (like banks changing their fraud filters).
Exploration vs. exploitation
Rely on an epsilon-greedy or softmax-based policy. For a fraction alpha (α) of the time, choose the best-known action (exploitation). For the remaining time, choose from the other actions with probabilities proportional to their predicted success probability (exploration). This ensures constant gathering of data on alternative actions, preventing stagnation and addressing changing conditions. During training, re-weight samples by the inverse probability of having selected that action in the live system. This mitigates bias from unbalanced exploration.
Production architecture
Organize code in notebooks for experimentation, then push stable versions into a code repository for reproducible pipelines. Use scheduling tools like Apache Airflow to trigger regular training. Track all training metadata (hyperparameters, model performance metrics) in something like MLflow. Store the final model artifact in a central repository.
Use a lightweight serving framework that loads the model into memory for near-instant inference (for example, a Python service exposing an API endpoint). Watch model size carefully, because large ensemble models can consume gigabytes of RAM. If memory becomes a bottleneck, consider dimension reduction, pruning, or alternative model architectures. Ensure enough hardware resources for high request throughput.
Real-time updates
When a payment arrives, generate predictions for all possible actions. Compute the best action with your chosen exploration-exploitation strategy. Log the (context, chosen action, reward). Next training cycle, feed that data back into the model, ensuring continuous improvement.
Monitoring and evaluation
Compare your new multi-armed bandit solution to the old A/B-based approach. Watch the uplift in conversion rates over time. If environment changes (for example, a new requirement from certain banks), the model should retrain promptly. Observe that performance might temporarily dip until the system gathers enough data on the new conditions and readjusts.
Example code snippet
Below is a Python-like pseudocode example of training a gradient boosting model with contextual bandits:
import xgboost as xgb
import numpy as np
import pandas as pd
# Suppose df has columns: [context_features..., action, reward, probability_of_action_taken]
# probability_of_action_taken is the exploration probability used earlier.
X = df.drop(["reward", "probability_of_action_taken", "action"], axis=1)
y = df["reward"]
# Re-weight each row by the inverse of the probability used to choose that action
sample_weights = 1.0 / df["probability_of_action_taken"]
model = xgb.XGBClassifier()
model.fit(X, y, sample_weight=sample_weights)
# Save or register model artifact in MLflow (optional pseudocode)
# mlflow.xgboost.log_model(model, "my_xgboost_model")
Keep logic to select the action inside the model’s predict function or in a separate policy function. Maintain clarity: predict probabilities, apply your exploration policy to choose an action, log the choice, and measure the reward.
Follow-up question 1
Explain how you might handle a situation where an action is rarely selected and the model never learns its true value.
Answer:
Use explicit exploration. Even if an action was historically chosen only 1% of the time, systematically pick it more often in the current exploration fraction. If the model is extremely uncertain for that action, temporarily elevate its exploration weight. This ensures enough samples to estimate its success probability. Consider an upper confidence bound (UCB) approach that boosts exploration for actions with sparse data. Over time, you gather enough data points to approximate the true performance.
Follow-up question 2
Explain in detail how you would update your policy if you discover a sudden shift in reward distribution, such as a bank changing rules.
Answer:
Schedule frequent retraining. A shift in the reward distribution means historical data loses relevance. Set short intervals (for instance, daily or weekly) to retrain the model using fresh data. Increase exploration rate temporarily to probe new patterns. Factor in time-based weighting so the newer data carries more importance. Continuously monitor performance metrics (like the aggregate conversion rate) for sudden drops. If a large drop is detected, trigger an immediate re-training job to adapt quickly.
Follow-up question 3
How do you validate a new model version before rolling it out fully?
Answer:
Reserve a portion of traffic for an online comparison against the existing model (a champion-challenger setup). Split incoming payments between the old and new models. Compare real-world conversion rates, adaptation speed, and latency. If performance significantly improves and latency is within acceptable bounds, gradually ramp up traffic to the new model. If issues emerge, revert to the old model and debug.
Follow-up question 4
What if the final model size becomes too big for memory constraints? How do you handle that in a low-latency environment?
Answer:
Prune the model or reduce its complexity. For gradient boosting, limit tree depth and the number of estimators. Apply techniques like feature selection or dimensionality reduction. Convert the model into a more compact format. Quantize feature values if possible, or switch to a smaller model class if the performance trade-off is acceptable. Keep the entire process in memory for latency reasons, but shrink the model footprint so it loads quickly and stays performant.
Follow-up question 5
Why not just use a traditional Reinforcement Learning library and skip custom bandit logic?
Answer:
Typical reinforcement learning libraries can be overkill and may introduce unneeded complexity. Large state spaces and complex value-function updates might exceed the immediate need. Contextual multi-armed bandits provide a simpler abstraction for this specific conversion optimization task. Reinforcement learning frameworks are useful if the environment has a long sequential decision chain and delayed rewards, which is less relevant here. Contextual bandits focus on immediate one-step actions and immediate rewards, making them easier to deploy quickly for payment optimization.