
ML Case-study Interview Question: Hybrid Conversational AI: Integrating LLM Chain-of-Thought with Workflow Tools


Case-Study question
You are hired as a Senior Data Scientist at a major online platform that connects travelers and hosts worldwide. The platform has an internal Conversational AI system named "Automation Platform," which was originally built using static, predefined conversational workflows. These workflows help automate interactions between customer support agents and guests/hosts, reducing repetitive tasks. However, the company now wants to integrate Large Language Models (LLMs) into its conversational system to make the conversations more flexible, intelligent, and context-aware. They also want to keep some of the original workflow logic for use cases where strict rules or numeric validations matter. The goal is to achieve a hybrid approach that combines LLM-driven dialogue with traditional workflows and incorporates guardrails to reduce hallucinations. Please propose a solution architecture that addresses:
How you would integrate an LLM-based chain-of-thought mechanism with existing workflow components to handle queries that require third-party tool executions (for example, checking a reservation status).
How you would design context management so the LLM receives relevant data (like customer history).
How you would implement guardrails to moderate content and mitigate incorrect or risky outputs.
How you would measure the system’s performance and reliability at scale.
How you would iterate on prompts and handle fast experimentation without breaking production.
Provide as many technical details as possible and explain how each part of your architecture would interact with others.
Detailed Solution
The solution fuses LLM reasoning with the original workflow system. It exposes existing workflows as "tools" that the LLM can call. It stores contexts from user sessions in a specialized component and has a guardrails layer that monitors communications. It also tracks performance metrics like latency and conversation success. Below is a breakdown:
Overall Architecture
The system receives an incoming customer inquiry. It forwards the user message and historical data to a chain-of-thought workflow. The chain-of-thought uses an LLM to decide whether to produce a direct response or call a tool. Tools represent any curated business logic, such as a booking validation workflow. After each tool call, the chain-of-thought receives the tool’s results and decides the next step. Once the final reply is ready, the conversation is updated in a database for observability.
Chain-of-Thought Workflow
Chain-of-thought is a loop of reasoning steps. The LLM orchestrates calls to internal workflows. It can request information or updates via these tools. The LLM text describes which tool to call and why. The system then executes that tool, obtains results, and feeds them back to the LLM. This continues until the LLM produces a final user-facing answer.
To illustrate the general principle of a language model’s next-token generation, consider the probability of a text sequence x = (x1, x2, ..., xn). We compute the joint probability using the chain rule of probability in text-based form for inline math:
P(x1, x2, ..., xn) = P(x1) * P(x2|x1) * ... * P(xn|x1, x2, ..., x(n-1))
Below is a core formula that drives the next-token selection in an LLM, shown in big H1 font:
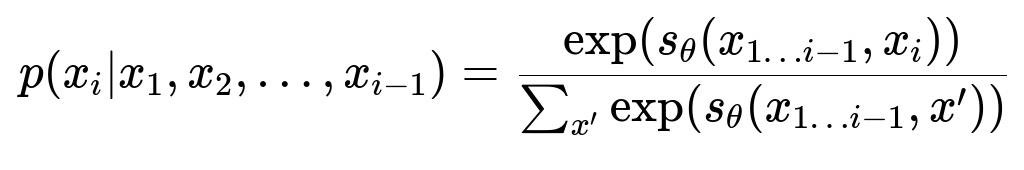
Here, p(...) is the probability for the ith token conditioned on the previous tokens, and s_theta(...) is the model’s scoring function. This is crucial for generating chain-of-thought responses because the system picks tokens that maximize the probability of valid intermediate reasoning steps.
Context Management
A context manager fetches all relevant data for each request. It might pull user roles, recent conversation history, and transaction data. It stores that information in a runtime context, which the chain-of-thought references in each turn. If the LLM asks, "What was the user’s last booking?" the system calls the relevant tool using pre-configured business logic. The context manager updates the record with the booking details. The LLM then uses that updated context in its next step.
Guardrails
A guardrails framework inspects messages both from and to the LLM. It checks for content policy violations and suspicious requests. It also monitors the LLM’s attempts to call restricted tools. If the LLM tries to produce inappropriate language or unauthorized tool calls, the guardrails framework intercepts and corrects or blocks them. For instance, a content moderation guardrail can route questionable output to a fallback script.
Observability and Measurements
The platform must log each LLM interaction with metadata: latency, token usage, and success metrics. This data is stored in an analytics warehouse. A set of dashboards monitors average response times, percentage of calls that required tool usage, and conversation completion rates. If a conversation fails (for example, the user abandons the flow or the LLM times out), it is tracked. This data pinpoints performance bottlenecks.
Rapid Iteration
A "playground" environment helps developers test prompts against a staging LLM. They can adjust prompts or chain-of-thought instructions without impacting production. A versioning system promotes stable changes into production after A/B tests. When prompts or reasoning logic prove beneficial, they replace older versions with minimal disruption.
Example Python Snippet
Below is a simple Python code snippet that shows a minimal chain-of-thought loop. It uses an LLM to decide whether to call a tool.
def chain_of_thought_loop(llm, user_message, tools, context):
conversation_context = context.get_context_data(user_message)
while True:
llm_input = create_prompt(conversation_context)
llm_output = llm.generate(llm_input)
if llm_output["action"] == "FINAL_ANSWER":
return llm_output["content"]
elif llm_output["action"] == "CALL_TOOL":
tool_name = llm_output["tool_name"]
params = llm_output["tool_params"]
tool_result = tools[tool_name](**params)
conversation_context["tool_result"] = tool_result
else:
# fallback or error handling
return "Sorry, something went wrong"
This snippet highlights how the loop sets up the LLM call, interprets the LLM’s response for a requested tool, executes it, and then updates context for subsequent steps.
Follow-up question 1
How would you handle cases where the LLM outputs references to non-existent tools or tries to call them in the wrong order?
Answer: Guardrails would capture requests to call non-existent or disallowed tools. They would parse each call request from the LLM, cross-check against a list of registered tools, and block or correct invalid calls. For example, if the LLM tries to call “update_payment_details” when only “cancel_reservation” and “create_inquiry” are registered, the guardrails framework would intercept and either return an error or instruct the LLM to try again. A specialized error-handling policy might supply a brief message telling the LLM which tools are allowed. This also applies to workflow ordering. If a particular tool requires prior authentication, but the LLM calls it prematurely, the system intercepts and instructs the LLM to authenticate first.
Follow-up question 2
In large-scale deployments, how would you manage latency and token usage while providing high accuracy?
Answer: Reducing prompt length is key. Instead of sending an entire conversation history, the context manager includes only essential data, such as the last few user messages, domain-specific parameters, and the relevant historical entries. This reduces token usage. We can also apply caching. If the same user or scenario recurs, store partial chain-of-thought results and skip repeated computations. To manage high throughput, we can shard requests across parallel LLM instances or fine-tuned endpoints. Then track average latency in real time. If performance degrades, gracefully degrade the system by reverting to simpler flows for non-critical requests. We might also limit or throttle the chain-of-thought steps so it doesn’t keep calling tools in an extended loop.
Follow-up question 3
How would you test your prompts and chain-of-thought logic before releasing to production?
Answer: A staging environment mirrors production endpoints, data, and guardrails. We feed test queries into the chain-of-thought workflow. Then we compare outputs with expected or known-correct results. If there is a known workflow for verifying booking data, we ensure the LLM consistently calls the correct tool. We monitor for errors or incomplete reasoning steps. We also run user acceptance tests where real or simulated user sessions measure accuracy, coverage, and user satisfaction. Once stable, we do an incremental rollout to a small fraction of traffic. We gather performance data. If all checks pass, we proceed to full release.
Follow-up question 4
How would you address hallucination or ungrounded responses from the LLM?
Answer: We can insert a grounding step that tells the LLM to cite evidence from recognized tools or from context data. If the LLM’s final reply includes unsupported claims, the guardrails catch these with a mismatch check. For example, a business rule states “the final answer must reflect either the user context or a valid tool’s result.” If the LLM response has content not matching context or tool outputs, the system instructs the LLM to re-check the data. Another strategy is to feed the final answer through a retrieval-based check or a smaller verification model that flags improbable statements.
Follow-up question 5
Could you describe a fallback mechanism if the LLM fails or times out?
Answer: If the LLM does not respond within a defined timeout, the system calls a legacy workflow. This workflow is the same static, rule-based process that existed before the LLM integration. It may not produce highly nuanced answers, but it guarantees coverage of core tasks. This approach ensures no user request is left unanswered. The system logs the LLM failure for later analysis. If repeated failures happen, the platform might shift traffic away from the LLM-based pipeline until stability is restored.
These solutions balance the need for dynamic, context-aware AI responses and the reliability of proven workflows. The guardrails, context management, tool integration, and chain-of-thought help the platform scale with minimal risks.