
ML Case-study Interview Question: Architecting Scalable AI Customer Support with LLM Multi-Agent RAG Systems


Browse all the ML Case-Studies here.
Case-Study question
A large technology company wants to improve their customer support system with a next-generation AI messaging solution that handles over 60000 inbound messages daily. They plan to use large language models for routing conversations, collecting preliminary information, retrieving relevant documents, and generating structured outputs (like JSON) to automate many support tasks. They also face challenges with memory management, latency, structured response accuracy, multi-agent architectures, and retrieval augmented generation. They want you to propose a detailed end-to-end solution, including prompt design, model selection, fallback strategies when models fail, and guardrails for sensitive operations. They also want a plan for performance monitoring, testing, and continuous improvement. How would you architect and implement a system to solve these issues?
Detailed in-depth solution
Overall architecture
Build a multi-agent framework with a controller prompt that routes user messages to specialized task prompts. One agent deals with user topic classification, another agent handles knowledge search, and another manages conversation summarization. Use a retrieval augmented generation approach for domain-specific queries. A top-level controller orchestrates which specialized prompt gets invoked. Adopt strict guardrails for high-risk actions, with code-based transfers to human agents when uncertain.
Prompt design
Keep prompts concise. Make separate prompts for classification, self-help flows, structured output, or specialized tasks. Avoid a single large prompt for all tasks. Control the conversation transitions within the code to ensure the model never traps users in endless loops.
Memory management
Store the conversation in short-term buffers. Summarize older segments when they exceed context limits. Keep critical user information (domain name or account ID) in a structured store. Let the specialized prompts retrieve relevant context on demand. Maintain ephemeral memory for each sub-agent. Summarize or discard tool-output messages that are no longer needed.
Structured outputs
Use a low randomness setting to stabilize your structured responses, such as JSON. Validate the output. If invalid JSON is returned, retry or invoke a fallback routine. Consider a parallel prompt that returns only user-facing text, with a second prompt returning structured data.
Retrieval augmented generation
Give the model a tool that performs semantic searches over knowledge base embeddings. Let it call that search tool when it detects a need for specific information. Return only the most relevant content. Prune redundant or flowery text. Consider pre-compressing your knowledge articles into short vector-friendly representations.
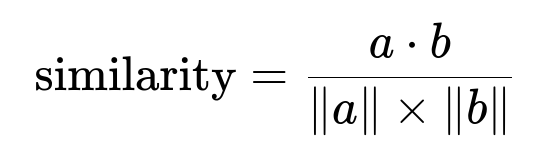
Where a and b are the embedding vectors of the query and document. Larger similarity indicates a closer match.
Reliability and latency
Use basic retries if a request fails. Limit calls to higher-powered models for critical tasks or in complex conversations. Handle timeouts by returning partial information and continuing asynchronously. Consider streaming responses to give quick partial updates.
Model selection
Pick a cost-effective model for routine tasks. Switch to a stronger model when the conversation grows longer or the request becomes more complex. If one provider is unavailable, switch to another. Keep track of latency and failure rates. Use deterministic conditions to route calls when you see reliability issues or usage spikes.
Guardrails
Use automated scans for personal data or offensive content. Enforce code-based triggers for transferring to human support if the model gets stuck or if the user explicitly asks for it. Block direct model actions that can harm user accounts. Default to human intervention if uncertain.
Testing and monitoring
Launch with frequent transcript reviews by multidisciplinary teams. Use synthetic test sets and real-world partial rollouts. Review transcripts daily in the early stage. Track metrics like model completion accuracy, user satisfaction, average handling time, and transfer rate. Iterate on prompts whenever you see user friction or error spikes.
Example code snippet
import requests
def call_model_api(prompt_data):
# Basic retry logic
for attempt in range(3):
try:
response = requests.post("https://api-model.com/v1/completions", json=prompt_data)
if response.status_code == 200:
return response.json()
except Exception:
pass
return None
def main_controller(user_message, conversation_history):
# Classify user intent with classification prompt
prompt_class = build_classification_prompt(user_message, conversation_history)
classification_result = call_model_api(prompt_class)
if not classification_result:
return "Sorry, something went wrong. Let me connect you to an agent."
# If classification indicates a routine task, handle with specialized prompt
if classification_result["intent"] in ["billing", "email", "hosting"]:
return handle_specialized_flow(user_message, conversation_history, classification_result["intent"])
# Otherwise, pass to human
return "Let me transfer you to a support agent."
Use a memory strategy that summarizes older messages as the conversation grows, but always keep recent context. Combine those summaries with relevant knowledge retrieved from your vector index.
Follow-up question 1
How can you handle a situation where the model consistently outputs invalid JSON, even after retries?
Use a stricter approach. Lower the temperature. Add system-level instructions forcing it to return valid JSON. Validate output with a JSON parser. If it fails repeatedly, return an error flag to the controller. Fall back on a simpler, well-tested routine or pass control to a specialized agent that only outputs JSON.
Follow-up question 2
How do you address repeated content from knowledge articles that waste tokens?
Pre-cluster overlapping content. Merge them into a single consolidated article. Summarize each cluster. Keep the final representation short. Let your retrieval mechanism feed only these compressed versions to the model. This reduces duplicated data and minimizes token usage.
Follow-up question 3
What if the conversation is long, but a small part of it is crucial for the next response?
Build a short summary of older turns. Keep important user attributes in dedicated variables. Provide the last few user and assistant turns verbatim to preserve recent context. Summarize or discard irrelevant text. Rely on the user’s explicit clarifications or references if the older text isn’t essential.
Follow-up question 4
How do you scale this approach to handle an even higher volume of messages?
Horizontally scale the stateless portions of the pipeline that handle classification or prompt generation. Maintain a replicated vector store or use sharding for retrieval. Run frequent load tests. Ensure you have fallback paths for model outages, including multiple model providers. Distribute traffic dynamically based on provider latency.
Follow-up question 5
Why does your multi-agent solution help compared to a single large prompt?
Each specialized agent has fewer instructions to parse, improving accuracy and reliability. You can tune each agent for its task. Fewer tokens per prompt lowers latency and cost. Decoupling tasks also makes debugging simpler because you can identify which specialized prompt failed rather than digging through a huge multi-purpose prompt.