
ML Case-study Interview Question: ML-Powered Recommendation Pipeline for Driving Real-Time User Engagement.


Browse all the ML Case-Studies here.
Case-Study question
A leading platform wants to improve user engagement using a data-driven recommendation system. They have extensive user interaction logs, a large catalog of items, and many user profiles. They want to build an end-to-end pipeline for analyzing user behavior, extracting relevant features, training machine learning models for personalization, and deploying a real-time recommendation system. Propose a technical solution, discuss how you would build and optimize each component, and outline how to evaluate and iterate on the results.
Detailed Solution
Data Ingestion and Storage
The system collects interaction logs, item metadata, and user profile attributes. A robust data pipeline pulls raw logs from clickstreams, page views, and session events, storing them in a scalable data warehouse. Streaming tools such as Kafka or Pub/Sub handle real-time event collection. Historical data moves to distributed file systems for batch processing. Relational databases store user profiles and item details.
Feature Engineering
Features include session-based activity counts, dwell times, user demographic info, item popularity, and historical engagement. Combining statistical aggregations with domain-specific transformations provides a rich feature space. Categorical and textual attributes are converted into numerical representations. Null or sparse values require careful imputation or fallback strategies. Training sets split into time-based partitions to mirror real-world usage.
Model Architecture
Collaborative filtering and deep learning approaches capture user-item relationships. Matrix factorization is often a starting point. The prediction of user u on item i uses user embedding p_u and item embedding q_i.
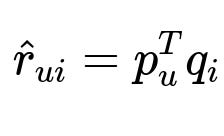
Here p_u is the learned embedding vector representing user u's latent preferences, and q_i is the learned embedding vector representing item i's latent attributes. The dot product p_u^T q_i estimates user u's affinity for item i.
One can train these embeddings by minimizing a loss that measures the deviation from known user-item interactions. Stochastic gradient descent updates p_u and q_i. Additional network layers (such as MLP) can be stacked on top of embeddings for more complex patterns.
Model Training and Evaluation
Training uses labeled data from explicit ratings or implicit clicks. Minibatch optimization processes a subset of data points in each iteration. Hyperparameters (embedding dimension, regularization weight, learning rate) are tuned. Overfitting is mitigated with L2 regularization on embedding parameters. Performance metrics include mean average precision, normalized discounted cumulative gain, or mean reciprocal rank. A holdout set or cross-validation ensures unbiased performance estimates.
Real-Time Serving
The prediction service loads trained embeddings or neural network weights. A fast in-memory lookup retrieves user and item representations. For each request, the model produces top-N ranked items. Low-latency environments require caching for frequently accessed items or precomputed candidate lists. Results might be re-ranked by recent context signals or business rules.
Iteration and Feedback Loop
Deployed models capture new user interactions in real time. Online learning frameworks or periodic retraining incorporate fresh data, ensuring the recommendations adapt. A/B testing checks if the updated model outperforms the baseline in key engagement metrics. These tests run until statistically significant results confirm a superior approach.
Follow-Up Questions and Answers
What challenges arise when training these recommendation models on sparse or imbalanced data?
Sparse data occurs because most users interact with only a small subset of items. Training on sparse data risks overfitting to popular items and underestimating niche items. Class imbalance means clicks or purchases on certain items can dominate. Mitigation involves negative sampling, data augmentation, or specialized sampling strategies to highlight rare interactions. Properly tuned regularization helps prevent embeddings from skewing toward popular categories. Reranking heuristics can encourage diverse recommendations.
How would you handle cold-start scenarios for new users or new items?
New users lack sufficient historical activity. A default embedding or demographic-based profile can be assigned. One approach is to capture attributes such as location, age group, or short-term interactions, enabling partial personalization. New items without interaction history get a generic item embedding plus side information from metadata or textual descriptions. As interactions accumulate, the system periodically retrains or updates item embeddings to reflect real usage patterns.
Why might deep neural networks outperform simple matrix factorization for certain recommendation tasks?
Matrix factorization captures linear interactions between users and items. Deep networks learn complex, nonlinear patterns, combining multiple signals (user embedding, item embedding, side features, contextual signals). This lets the model capture user preference shifts, item attribute correlations, or intricate user-behavior relationships. Well-designed architectures can integrate user demographics, item textual data, or images for more expressive representations.
How do you ensure real-time updates without causing downtime or stale recommendations?
A microservice architecture separates model training from inference. You keep a small server fleet running the current model while a new model trains offline. After validation, the new weights or embeddings load into a fresh inference cluster. A rolling release directs traffic to the updated cluster. Caching or streaming updates from user events can enrich the existing model. This avoids downtime and immediately incorporates new signals.
Show an example code snippet for generating recommendations after you have learned user and item embeddings.
Below is a simplified Python example using matrix factorization embeddings p_u and q_i. Suppose we have user_embeddings, item_embeddings, and a function to compute top recommendations.
import numpy as np
def recommend_items(user_id, user_embeddings, item_embeddings, top_k=5):
user_vector = user_embeddings[user_id]
scores = item_embeddings @ user_vector
ranked_items = np.argsort(-scores)
return ranked_items[:top_k]
# Example usage:
# user_id = 42
# top_items = recommend_items(user_id, user_embeddings, item_embeddings, 5)
# print(top_items)
This snippet illustrates a matrix multiplication-based recommendation. The embeddings are loaded from trained model outputs. Scores represent dot products between the user vector and item embeddings. Sorting by descending score yields the top-ranked items for the given user.
How do you measure success and iterate on the final system?
Offline evaluation uses metrics such as mean average precision, recall at K, and normalized discounted cumulative gain. Online A/B tests measure clickthrough rates or session durations from real users. Statistical confidence checks detect significant improvements. Incremental model updates occur based on performance results. The pipeline includes monitoring for distribution shifts or data drifts, prompting retraining or feature refinement.
How would you handle the engineering overhead of such a high-volume recommendation system?
A combination of batch processing for large-scale historical data and streaming ingestion for real-time user events is required. Automated workflows or orchestration tools manage data pipelines. Containerized deployments and microservices modularize development and deployment. Infrastructure as code or managed Kubernetes clusters maintain stable releases and scaling. CI/CD pipelines automate testing and rolling out new models without disrupting the user experience. Proper monitoring, logging, and alerting minimize downtime.
These approaches optimize data throughput, keep the system up to date, and maintain a seamless user experience. The pipeline is robust against high traffic, and it adapts to shifts in user preferences.