
ML Case-study Interview Question: Detecting Sophisticated Proxy Bots with Gradient Boosting and Behavioral Analysis.


Browse all the ML Case-Studies here.
Case-Study question
A global technology company faced sophisticated bot attacks that used vast pools of residential IP proxies and major cloud providers. Attackers rotated IP addresses to evade simple IP-based blocking. Attack traffic targeted critical endpoints such as login pages or voucher redemption flows. Blocking entire subnets introduced high false positives. Proxies made network-based detection challenging due to legitimate devices sharing the same residential IPs. Proposals to use a machine learning model were made to identify bot traffic and preserve real-user access. You are asked to design a robust solution end to end. How would you:
Detect and classify automated traffic from a fast-changing pool of IPs.
Handle training data acquisition and labeling, considering missed attacks from feedback and known bad traffic.
Combine behavioral and network signals into reliable features.
Evaluate false positives and ensure legitimate users remain unaffected.
Deploy and maintain the model in production with continuous improvements.
Describe the process, the machine learning approach, and how you would refine the model to handle evolving bot tactics.
Detailed Solution
Data Collection and Labeling
Data came from a high-volume HTTP request stream. Attackers leveraged residential proxies that mask or rotate IP addresses and also used cloud providers. Training sets included known malicious requests from previously flagged campaigns, customer-reported missed attacks, and known good human traffic. Validation sets included distinct time windows and attacks not in the training set. High-confidence ground truth was derived from heuristic detections and manual reports.
System engineers stored all request logs in a large columnar database. Data pipelines built with Apache Airflow fetched and filtered these logs via SQL queries. They combined features from multiple sources, such as single request properties (method, user-agent, TLS version) and inter-request patterns (aggregates of requests per IP, global or ASN-level rates).
Feature Engineering
Single request features captured fields like user-agent, cookie structure, JavaScript signals, and request method. Inter-request features captured request density from specific IPs or ASNs, session transitions, velocity, and distribution of HTTP methods. Network latency signals helped differentiate proxied versus direct connections. Global features leveraged large-scale aggregates, such as how often the same IP or fingerprint was seen across all protected domains.
Residential proxies often show short bursts of high-intensity traffic during suspicious periods, then vanish. Legitimate home users behind the same IP might only make a handful of requests. This required a per-request classification approach that combined multiple signals, rather than outright IP bans, to avoid false positives.
Model Architecture and Training
Engineers used a gradient boosting library (CatBoost) for robust handling of categorical variables (like user-agent) and to capture non-linear interactions. They orchestrated the training pipeline with Airflow DAGs, which ran steps to:
Fetch training and validation data subsets.
Train the CatBoost model with careful hyper-parameter tuning.
Compare metrics against the prior active model.
Check feature importance and distribution to avoid overfitting.
Validate on specialized subsets (e.g., suspicious endpoints, large ASNs, outliers).
They gradually introduced newly trained models in shadow mode to see real-time performance without affecting production decisions.
Example Gradient Boosting Formula
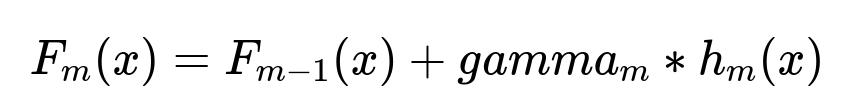
Here, m represents the iteration index, gamma_{m} is the learning rate or step size for iteration m, and h_{m}(x) is the newly fitted weak learner (decision tree). The final prediction is the sum of all incremental updates added over each iteration.
Engineers systematically repeated training runs over multiple days of logs to ensure consistency and generalization. They then evaluated the new model on high-volume traffic to verify both improved detection of residential-proxy bots and minimal false positives.
Production Deployment
Engineers shipped the model behind an inference service. Requests triggered feature extraction, then the model returned a score. If above a threshold, the traffic was marked suspicious, potentially requiring additional authentication. When testing showed reduced missed attacks and stable false positive rates, they activated the model for all users.
They set up continuous monitoring of detection rates, false positive reports, and real-time metrics on how many suspicious requests were flagged. Additional improvements included:
Fine-tuning thresholds by region or endpoint to handle local network quirks.
Periodic re-training on fresh data to keep pace with new proxy techniques.
Auto-update features so customers automatically received new model versions.
Potential Follow-up Questions
How do you handle rapid rotation of IP addresses by attackers?
Attackers switched IP addresses frequently to bypass naive rate limits. Training data must consider that many IP addresses might appear only briefly. Engineers combined local and global features. Single IP-based decisions were insufficient, so the model aggregated signals from user-agent patterns, cookies, TLS fingerprints, and request behaviors. Even if IP changed, suspicious user-agents or abnormal request sequences helped the model classify bots quickly.
How do you manage false positives in residential networks where legitimate and proxied traffic originate from the same IP?
Engineers avoided broad IP bans. They used per-request classification to let real users through. They studied timing, user interaction signals, and velocity patterns to identify bots. Cloud-based detections sometimes used fingerprinting to track suspicious sessions across IP transitions. This approach let legitimate users maintain normal site access.
How would you tune CatBoost hyper-parameters for large-scale traffic?
They started with standard search methods (grid search or Bayesian optimization). For each candidate set of hyper-parameters, they measured metrics like precision, recall, and overall AUC on large validation subsets. They used early stopping to prevent overfitting. They also monitored training speed, memory usage, and model complexity.
How do you ensure training data captures evolving patterns?
They retrained regularly with data from new malicious campaigns discovered by heuristics or user reports. Each re-training pass integrated these fresh samples to keep the model relevant. They also audited the distribution of known benign versus malicious data to maintain balanced coverage.
How do you deploy in shadow mode without impacting real traffic?
Engineers made two versions of the model available: the active production model and the new candidate. Real traffic was scored by the active model for official decisions. The candidate model ran in parallel to log its scores only, enabling offline evaluation. If the candidate model showed better detection with acceptable false positives, it replaced the active one.
How do you address performance constraints when scoring 46 million requests per second?
They deployed the model on highly optimized inference servers close to the edge. Engineers condensed features into lightweight numerical or categorical form for minimal overhead. They also cached certain features or partial computations. Horizontal scaling with parallel inference clusters maintained low latency.
How did the solution specifically detect residential proxy patterns?
Engineers observed that proxied requests often had unique latency signatures, abnormal network routes, and suspicious burst activity. They supplemented these with session-based signals. Residential IP addresses hosting proxy software typically showed low genuine activity but large, sudden spikes. Training data from known proxy networks helped the model learn such signatures.
What if bot operators mimic normal browser patterns more closely?
Sophisticated bots can emulate realistic browser fingerprints, but subtle discrepancies remain. High-fidelity browser integrity checks, JavaScript-based tests, and real-time user interaction signals can reveal automation. The model also leveraged uncommonly repeated TLS signatures, mismatch in expected headers, or improbable user-agent patterns. No single feature was decisive, but the combination often flagged synthetic traffic.
That concludes a comprehensive solution strategy for this case study.