
ML Case-study Interview Question: Automated Pipelines for Dynamic Streaming Recommendations and Custom Evaluation Metrics


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing and deploying machine learning models to personalize content on a streaming app’s main landing page. The app’s home screen features multiple shelves (or sections) that recommend different types of content, such as podcasts, playlists, and similar items. The goal is to boost engagement and ensure that the right content is recommended to each user. You have inherited three existing recommendation models from the previous team:
A Podcast Model that predicts which podcast shows a user might listen to.
A Shortcuts Model that predicts the next familiar item a user might want to resume.
A Playlists Model that predicts playlists for new listeners.
Your primary task is to improve these models, integrate them within the company’s ML pipelines, and ensure they stay up-to-date. The current system has these challenges:
Existing models sometimes fail to recommend newly published or newly created content because they do not see them in the original training data.
Model evaluation relies on limited A/B tests and standard metrics, but crucial heuristics-based baselines exist outside the main ML pipeline, making fair comparisons hard.
The workflow for training, deploying, and retraining models is labor-intensive, requiring manual processes and significant engineering overhead.
Ensuring that each model is evaluated against strong non-ML baselines and custom metrics is difficult because of tool limitations.
There is no automated CI/CD-style retraining pipeline, so stale models are common.
Propose a strategy to address these problems, explaining how you would:
Establish reliable baseline heuristics and compare them against trained ML models.
Integrate custom evaluation metrics (like NDCG@k or diversity measures) into your pipelines.
Create a system for automated model retraining and deployment (CI/CD).
Handle newly introduced content categories so that your models adapt and recommend them accurately.
Explain the reasoning behind each part of your solution, focusing on the practical steps needed to implement or improve these recommendation models in production.
Detailed solution
Establishing strong heuristics and baselines
Start with a robust heuristic as a quick baseline. Compare each trained ML model’s performance against that baseline. Ensure that the evaluation data and transformation logic are consistent between heuristic and ML approaches. For simpler heuristics, encode the heuristic’s outputs inside a “dummy” model for easy side-by-side comparisons using the same evaluation pipeline. For more complex heuristics, build a separate comparison pipeline that can load both ML and heuristic results for the same data.
Integrating custom evaluation metrics
Set up consistent offline evaluation. Use standard metrics like precision, recall, and accuracy, but also incorporate normalized discounted cumulative gain to highlight position relevance for top recommended items. Keep all transformations for metrics in the same environment, so they share transformations with the model. Use flexible Python-based approaches where possible to implement advanced metrics that might be unwieldy in built-in libraries.
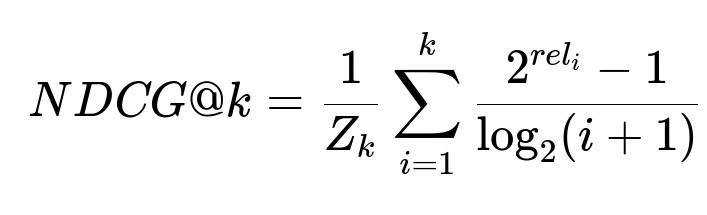
Here, k is the cutoff for top-k items to consider. rel_i is the relevance score for the item at position i in the recommended list. Z_k is the ideal discounted cumulative gain for the top-k items. The goal is to measure how well the recommended ranking aligns with true user preferences, emphasizing higher-ranked items more heavily.
Evaluate partial results on a dedicated internal dashboard that displays actual recommendations given specific user features. Inspecting real predicted outputs provides deeper insight than aggregate metrics alone.
Automating retraining and deployments
Set up a pipeline that schedules data extraction and feature transformations on a recurring basis. Label the data, split into training and test sets, and invoke model training. Add a check to compare the new model’s offline metrics with established thresholds (for example, an NDCG@k score exceeding your baseline or previous model). If it surpasses the threshold, automatically push the model to the serving environment.
Use an online model-serving platform or an internal service that supports:
Logging transformed features
Quickly loading new model versions
Rolling back if performance degrades
This eliminates manual intervention, reduces stale models, and cuts technical debt. When new content types emerge, ensure the features capturing them are properly logged and included in the next retraining cycles so the model learns these new categories.
Handling newly introduced content
Capture new categories in your feature pipeline. If the model has a known limitation of ignoring unseen categories at training time, schedule frequent retrains or supplement the pipeline with an approach that dynamically updates embeddings or item indices. Confirm that your data transformations and the main model can adapt, so users see recently introduced items in real time or with minimal delay.
Check the updated recommendations in the internal dashboard. If the model persists in suggesting only older, popular items, investigate potential feature-engineering or data coverage gaps. In urgent scenarios, overlay a fallback rule-based system to boost representation of newer categories until the retraining pipeline fully learns them.
Practical example of code integration
Use a Python-based ML pipeline with Kubeflow. Write a custom component for data loading, transformations, and splitting. Write a second component for model training (e.g., a scikit-learn or TensorFlow step). After training completes, store the model artifact. Write a third component for evaluation, using a Python script that computes NDCG@k for both the new model and the baseline. If the result passes a threshold, auto-deploy via the serving platform’s API.
Example structure in Python (simplified illustration):
def training_component(train_data_path, output_model_path):
# Train model
# Save model artifact
def evaluation_component(model_path, test_data_path):
# Load model
# Generate predictions
# Compute NDCG@k
# Compare with threshold
# Return deployment decision
def deployment_component(model_path, deploy_decision):
if deploy_decision:
# Push model to the serving environment
else:
# Keep old version
Use an orchestration tool like Kubeflow Pipelines to link these components. Schedule the pipeline to run weekly or daily, ensuring your model sees fresh data and newly introduced items.
What if the business wants fewer big experiments and more reliable offline results?
Offline metrics and dashboards provide quick iteration on model ideas. Rely on them for most comparisons to avoid running too many overlapping A/B tests. Confirm that offline metrics correlate well with real-world usage. When correlation is solid, smaller numbers of carefully planned A/B tests are enough to validate final changes.
How to handle non-ML solutions that keep outperforming ML?
Compare cost and complexity. If a non-ML heuristic consistently matches or outperforms ML while requiring less maintenance, consider that approach in production. Identify whether your training data or features are missing something. Investigate advanced feature engineering, better labeling, or more sophisticated architectures if a purely heuristic approach remains dominant. Be mindful of the overhead of ML if the improvement is negligible.
How to diagnose a model that gives repetitive recommendations to everyone?
Use a manual inspection dashboard. Input varied user features and see which recommendations appear. If the same content appears at the top for all users, investigate whether popularity is overly weighted or if the training set is too uniform. Improve your training procedure, incorporate diversity-based metrics, or penalize repeated items. Expand feature sets to reflect user preferences or local context.
How to ensure transformations in training and serving are consistent?
Store transformations in a single code repository or use a standardized library. If the transformations are complex and cannot be handled by frameworks like TensorFlow Transform, keep them in Python modules that are imported both by the training pipeline and the serving environment. Version these transformations carefully, so model versions align with the correct transformation code.
How to handle stale library versions and technical debt?
Plan a pipeline that retrains frequently. Lock your dependencies in well-defined environments or container images. Update them regularly. If the pipeline is standardized, refreshing library versions becomes simpler because you control changes in a single place rather than hacking them across multiple manual scripts.
How to address big-data performance concerns?
Keep transformations efficient. Use distributed data processing frameworks like Apache Beam or Spark for large training sets. Use caching for repeated tasks. If you have frequent retrains, schedule them during off-peak times or scale resources on demand to minimize pipeline runtime. Monitor metrics like pipeline execution time and memory usage.
How to demonstrate readiness for real production loads?
Deploy the final solution in a staged environment. Direct a small fraction of real user traffic to the new system initially. Track latency, memory usage, and success rates. If stable, increment traffic until all user requests are handled by the new system. Keep the old solution as a fallback for quick rollback.
How to unify metric tracking for multiple models?
Use a centralized internal UI or metric-logging system that records offline scores, online A/B test outcomes, and any custom metrics for each model version. Tag each model version with a unique ID. Use the platform’s built-in comparison features to see historical performance. This helps you spot performance regressions or confirm that a new approach is genuinely better.
How to design a strong interview answer for this case study?
Show clarity in mapping business needs (fresh and relevant content) to ML requirements (frequent retraining, flexible evaluations, robust baselines). Propose a pipeline-based solution. Emphasize consistent transformations and well-designed metrics. Illustrate the final CI/CD approach that cuts manual overhead. Demonstrate fallback strategies with heuristics for new or rare content. Ensure you highlight the best practices in production ML, including reproducibility, model logging, versioning, and rapid iteration.