
ML Case-study Interview Question: AI Search for Billions of Designs with Multimodal Embeddings and Vector Search


Browse all the ML Case-Studies here.
Case-Study question
You are given a massive design-sharing platform that wants to build AI-powered search across all designs and published components. Users must be able to find any design or component through a screenshot, selection of layers, or text description. The system needs to scale to billions of designs while keeping costs low. Propose a strategy to index these designs, generate embeddings, store metadata, and perform AI-based vector search. Address details about the data pipelines, embedding model choice, infrastructure, cost optimization, indexing frequency, and cluster scaling. Offer practical ideas for how to merge semantic search with existing text-based search.
Detailed solution approach
AI-based search relies on generating numerical representations, called embeddings, for both text and images. A suitable multimodal embedding model can encode images and text into the same embedding space. The system compares a query embedding to indexed embeddings with nearest neighbor search.
Architecture and pipeline
A headless version of the product’s editor enumerates and renders every relevant frame or component into images. An asynchronous job runs on the server to:
Identify all frames or published components.
Render thumbnails and store them in an object store.
Send batched thumbnail URLs to a model inference endpoint.
Receive embedding vectors and write them, along with metadata, to a vector-capable search index.
Metadata gets saved in a NoSQL datastore. The pipeline triggers on file changes (debounced to avoid reprocessing too frequently). Batching and concurrency are used for efficiency in the thumbnailing and embedding steps.
Generating embeddings
A multimodal model (such as a CLIP-based variant) is fine-tuned on publicly available UI images. The model outputs vector embeddings for any given text or image. These embeddings go to an inference endpoint deployed in a cloud service. The queries from users also get converted to embeddings (by the same or a parallel model) so that everything resides in the same embedding space.
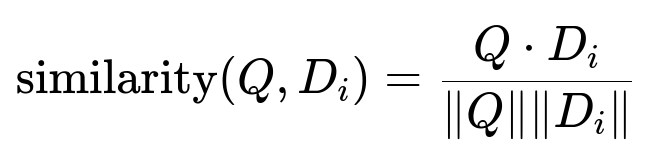
Where Q is the query embedding, and D_i is the embedding of item i.
Indexing and search
The system writes embeddings and metadata to a distributed vector index. A vector search (kNN or approximate nearest neighbor) retrieves items with embeddings closest to the query vector. A lexical engine (for text-based keywords) can run in parallel. The separate result sets merge with a rescaled scoring. High-precision text matches get a small boost. This approach balances older text-based matches with newer semantic matches.
Scaling and cost optimization
Mass indexing billions of items can be costly. The biggest expenses arise from rendering frames and writing large embeddings:
• Server-side C++ replaced higher-level logic to parse and thumbnail frames. • Thumbnails use software-based rendering on cheaper machine types, reducing GPU costs. • Indexing is debounced to avoid re-ingesting data repeatedly for small edits. • Vector quantization reduces the embedding footprint in the index. • The search cluster autoscales to handle diurnal traffic patterns.
Example Python snippet for batch embedding
import requests
import numpy as np
from PIL import Image
import io
def get_embeddings(image_urls, batch_size=32):
all_embeddings = []
for i in range(0, len(image_urls), batch_size):
batch = image_urls[i:i+batch_size]
# Prepare images in memory
images_data = []
for url in batch:
resp = requests.get(url)
img = Image.open(io.BytesIO(resp.content))
# Preprocessing, resizing, etc.
images_data.append(np.array(img))
# Send batch to embedding model endpoint
# Example pseudo-code for a hypothetical inference API
embeddings = send_to_model_endpoint(images_data)
all_embeddings.extend(embeddings)
return all_embeddings
This snippet shows how to batch and preprocess images before sending them to an inference endpoint. Parallel or async calls reduce end-to-end latency.
What are the key metrics you would track to measure if your AI search strategy is successful?
A robust AI search must be evaluated systematically. Metrics include:
Search relevance. Evaluate precision and recall using a test set with known relevant results.
Latency. Measure response times, including embedding generation for queries and retrieval times.
Index freshness. Track how quickly changes or newly published items are reflected in results.
Cost per 1K searches. Keep costs in check by monitoring GPU/CPU usage for inference, cluster size for indexing, and storage overhead.
Explain your experiments with offline tests (like precision@k) and real-world usage (like clickthrough rates or user satisfaction).
How would you handle merging lexical and semantic results when their raw scores are not on the same scale?
Using two separate indexes (one lexical, one vector) yields separate scores. Those scores are not directly comparable. A typical approach:
• Use min-max normalization to scale each index’s scores to a [0,1] range. • Assign a weight to each score. • Sum or combine them into a final score.
Exact text matches might receive a small boost to favor known canonical matches.
How do you handle partial updates to embeddings when a user renames a file or modifies a design?
The search index uses a document-based approach. If embeddings are not stored in the document source, an update might overwrite them. You must refetch the old embeddings from a NoSQL store, combine them with the updated metadata, and then update the document in the index. This preserves existing vectors and ensures new fields reflect the updated file metadata.
How would you reduce indexing overhead if 90% of these frames or components are rarely used?
Debouncing file changes is critical. Instead of immediately re-indexing with every save event, batch the changes. Another tactic is selective indexing for items that change frequently. Archive items that have not been opened or updated in a long time and serve them from a fallback index if needed.
How do you handle non-deterministic search results if replicas in the index return slightly different results?
Replica-based inconsistencies can arise from internal indexing errors or segment-level differences. Approaches include:
• Routing all queries for a single user session to the same replica. • Using consistent hashing for query distribution. • Ensuring consistent use of the same index segments. • Collaborating with the index provider to patch segment replication bugs.
How would you fine-tune a multimodal model without using private data?
Use public, domain-relevant datasets. For UI-based tasks, gather publicly licensed UI images or dummy components. Validate that no private or proprietary data is used. Fine-tuning focuses on bridging the domain gap so the model learns the style, structure, and vocabulary of typical designs without exposure to actual sensitive information.
How do you handle concurrency for high-traffic inference requests?
Deploy multiple inference worker processes behind a load balancer. Batching requests improves GPU utilization. As traffic grows, autoscale the deployment so the system can spin up more workers. Client-side micro-batching also reduces overhead if each request has a small payload.
Why might you consider approximate nearest neighbor search instead of exact kNN?
Exact kNN is expensive for large-scale systems with billions of embeddings. Approximate nearest neighbor search algorithms (like Hierarchical Navigable Small World graphs or Product Quantization) deliver faster lookups with a small recall drop. This is crucial when real-time latency is essential and index sizes grow large.
How would you secure user data while generating embeddings?
Frames or components might contain confidential information. Strictly sandbox the headless rendering environment. Strip user-sensitive text or placeholders during thumbnails if possible. Encrypt embeddings at rest. Restrict all inference traffic to private network endpoints. Enforce strong IAM rules on pipelines that process user data.
How would you handle multi-tenant isolation?
Store tenant-specific data in separate index segments or carry a tenant ID in each document. Filter results by tenant ID during search queries. For cross-organization searches, maintain an access control layer so only users with the right permissions see the data.
How do you ensure embeddings are backward-compatible if you later upgrade the model?
Version embeddings. Include the model version in the document. If the model is upgraded, store new embeddings in parallel with the old ones and gradually replace them. During the upgrade, handle queries from old embeddings seamlessly by still searching on the old index until re-embedding is complete.
What is the biggest challenge you would foresee in rolling out AI search to a small set of alpha users at enterprise scale?
A handful of power users might belong to many teams with extensive data, which forces near-complete indexing. This partial rollout does not save as much cost as you might expect. You must carefully plan the pipeline capacity and cost for large indexing tasks triggered by even a small user group.
How do you verify the model is not leaking private user content when returning search results?
Run an internal audit of the prompt-query logs to detect any direct text or snippet leaks. Thoroughly test boundary cases, such as searching for code or private text. Implement checks that confirm embeddings themselves do not reconstruct original data. Evaluate the vector outputs for potential inversion attacks, and place strict access controls on the final search results.
How would you handle a scenario where the nearest neighbor vector search results appear visually similar but are semantically irrelevant?
Include metadata in the indexing. Combine semantic similarity with constraints like color, text labels, or file context. This ensures that the system does not return visually similar but unrelated items. Optionally apply re-ranking methods that incorporate text matches or metadata weighting.
How would you handle edge cases where text queries require domain knowledge (e.g., a custom brand term)?
To capture brand or project-specific terms, combine lexical search with embeddings. Maintain a domain dictionary to explicitly link certain custom words or acronyms to the relevant items. A re-ranking step merges those results with the semantic search hits so brand-specific queries succeed without missing intangible brand context.
How would you approach performance testing for different OpenSearch cluster configurations?
Run load tests with realistic query concurrency. Vary instance sizes, replica counts, vector indexing types, and approximate search algorithms. Log CPU, memory, and I/O usage under stress. Track average latency, p95 latency, error rates, and maximum throughput. Use smaller subsets of real data to iterate on configurations, then scale up tests gradually.
How would you debug a partial index failure where some frames never appear in results?
Check pipeline logs at each stage. Ensure the headless rendering job completed successfully. Verify thumbnails exist in the object store and that the embedding job returned embeddings. Look for indexing logs in the search cluster. Confirm the cluster has no errors for those documents. If a mismatch in ID or source fields is found, correct it and reprocess.
How do you see embeddings evolving if your platform grows to 50 times the current data size?
Move to more advanced approximate methods. Consider deeper quantization or specialized GPU-based indexes. Possibly adopt hierarchical indexing, sharding, or region-based partitioning. Offload older or infrequently accessed data to slower tiers and keep the top 10% most-used designs in a high-performance index.
How do you plan to keep the system maintainable for a large data science team?
Segment the pipeline into standalone services (rendering, embedding, indexing). Keep clear APIs between them. Centralize logging and metrics for each stage. Document each service’s input, output, and operational constraints. Implement robust error handling, rollback, and reprocessing. Enforce version control on model checkpoints and pipeline logic.
How would you handle ephemeral or dynamic components that only exist briefly in a user session?
Skip indexing ephemeral data. If an item is short-lived, rely on local caching or memory-based searches. Only index items with a stable ID or persistent URL. This preserves index cleanliness and avoids large churn for items with minimal usage.
How do you validate that your search is not over-fitting to the training set?
Hold out a test set with data not seen during fine-tuning. Evaluate similarity results. Compare real usage metrics (like user satisfaction or search success rates) with offline test scores. If the system shows good offline metrics but poor real usage feedback, investigate domain mismatch or data drift.
How would you incorporate feedback loops to refine results?
Provide a feedback button or track user interactions. If users often click the third result instead of the first, treat that as a signal. Collect these signals to retrain the model. Gradually improve embeddings and re-rank logic. Add an A/B testing framework to measure changes in search relevance or speed.
How do you scale your approach if you add new AI features like text-to-design generation?
Generalize the pipeline with modular components for embedding, indexing, and inference. Store generator outputs in a versioned repository. Index newly generated designs similarly. Ensure existing embeddings are compatible or create a new indexing strategy specifically for generative data. Monitor cost because generative steps can be more expensive than search inference.
How would you address legal or compliance concerns?
Obtain all approvals for capturing or rendering user content. Provide an opt-out for sensitive files or data. Comply with data residency requirements and GDPR by partitioning data by region if necessary. Log all pipeline access. Maintain strong encryption of stored thumbnails and embeddings. Enable rigorous data deletion practices upon user request.
How do you handle future model deprecation?
Deprecate older models gradually. Mark them as legacy when a newer, more accurate or efficient model is ready. Migrate data in stages. Serve queries from both indexes until enough data is re-embedded. Remove the legacy model once usage is near zero or once all items have updated embeddings.
How do you mitigate the risk of hallucinated results?
Strictly filter answers or search snippets for correctness. If a user queries "rounded corner button," the system returns relevant components with a high degree of confidence. Do not auto-generate text about it beyond retrieval. Maintain guardrails in the final retrieval. Test thoroughly with corner cases to ensure the results match actual existing designs or components.