
ML Case-study Interview Question: Scaling Image-to-Animation Diffusion: Model Optimization and Global Traffic Management


Browse all the ML Case-Studies here.
Case-Study question
A large tech firm needs to launch a feature that generates short animations from single images with diffusion-based models. They must serve billions of people across different regions with minimal latency and high success rates. They want to optimize the model’s performance, reduce GPU usage, and manage global traffic so requests avoid inter-regional routing whenever possible. How would you design and implement a scalable solution that meets these constraints, while preserving animation quality?
Detailed Solution
Model Optimization
Halve the floating-point precision by moving from float32 to float16. This lowers memory consumption and speeds up inference. Use bfloat16 for stability. Handle temporal attention more efficiently by expanding the time dimension only after passing data through cross-attention’s linear projection layers. Reduce sampling steps with DPM-Solver, cutting the number of denoising steps without hurting image quality. Merge classifier-free guidance with step distillation to cut multiple passes down to a single pass in the U-Net, slashing inference time.
Example Code Snippet
import torch
# Example pseudo-code for combining guidance and step distillation
# Here we simulate multiple steps of teacher model with one step of student model
def teacher_step(x, cond):
# Teacher forward pass
return teacher_unet(x, cond)
def student_step(x, cond):
# Student forward pass
return student_unet(x, cond)
def distillation_training_step(x, cond):
teacher_output = []
for _ in range(teacher_steps):
x = teacher_step(x, cond)
teacher_output.append(x.detach())
# Single forward pass of student
x_student = student_step(x.clone(), cond)
loss = loss_fn(x_student, teacher_output)
loss.backward()
optimizer.step()
Torch scripting and freezing yield further speedups. Convert dynamic ops into static for simpler computational graphs. Switch to PyTorch 2.0-based compile features for advanced optimizations like context parallel and sequence parallel. This helps with multi-GPU inference as well.
Traffic Management
Use data from prior AI-based media launches to estimate GPU capacity. Deploy a specialized routing system that keeps requests in their home region unless capacity runs out. This avoids cross-region routing. Implement a retry approach with marginal execution delay and exponential backoff. This prevents queue build-up while reducing cascades of failures under spikes.
Example Code Snippet
def schedule_request(request, region_capacity):
# region_capacity is a dict of available GPU capacity per region
selected_region = find_local_region(request)
for retry_count in range(max_retries):
if region_capacity[selected_region] > 0:
# Place request here
region_capacity[selected_region] -= 1
return selected_region
else:
delay = compute_exponential_backoff(retry_count)
time.sleep(delay)
selected_region = pick_alternate_region(request, region_capacity)
raise RuntimeError("Failed to schedule request after retries.")
Combining All Pieces
Continually measure latency, GPU utilization, and success rates. Adjust the scale of distillation or the number of solver steps as needed. Fine-tune traffic routing thresholds to avoid overloading or cross-region slowdowns.
How Classifier-Free Guidance Works
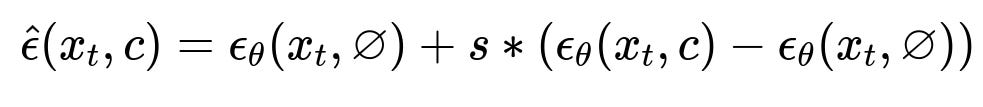
Here, x_{t} is the noisy image at time t. c is the conditioning (text, image prompt, or both). varnothing stands for the unconditional context. epsilon_{\theta} is the model’s prediction of the noise. s is the guidance scale. This equation blends unconditional and conditional predictions to push the generation toward your specified context.
Follow-up Question 1
What if the traffic management system causes one region to run significantly hotter than others for short intervals?
Use dynamic load balancing with near-real-time metrics. Continuously track GPU utilization in each region. Update the routing table more frequently during spikes, offloading partial traffic to nearby regions. Insert a minimal execution delay so requests do not all start simultaneously.
Follow-up Question 2
How do you ensure model precision does not degrade by moving from float32 to float16?
Rely on bfloat16, which maintains a large exponent range. Monitor distribution shifts via validation images. Keep a fallback path with higher precision if extremely fine-grained animation details are required for edge cases. Profile memory usage and peak performance to confirm gains.
Follow-up Question 3
How do you handle potential quality loss when you reduce sampling steps with DPM-Solver?
Train with enough step distillation to preserve image fidelity. Verify output with robust automated metrics and human evaluation. Fine-tune solver parameters such as noise scheduling and signal-to-noise ratio shaping. Gradually test lower step counts in production while monitoring user feedback.
Follow-up Question 4
How would you handle versioning if you want to deploy multiple U-Net variants?
Tag each U-Net variant with a unique identifier. Store them in a centralized model registry. Route some fraction of traffic to the new variant for canary testing. Gather performance and quality metrics. Switch traffic fully after confirming improvements. Roll back quickly by toggling routing to the previous stable version if issues arise.