
ML Case-study Interview Question: Two-Stage Personalized Search Ranking with Embeddings and Gradient Boosted Trees


Browse all the ML Case-Studies here.
Case-Study question
A large online marketplace hosts tens of millions of items from independent sellers. Many items have unique or unconventional attributes. The current search system retrieves items based on text matching (title, tags, etc.) and then ranks them using a standard gradient boosted decision tree model. The company wants to improve this system with personalized results for each user. They have historical user interactions (clicks, favorites, add-to-cart events, purchases), and they can build vector representations of listings using Term Frequency–Inverse Document Frequency, graph embeddings, or item-interaction embeddings. They also have various numerical features that describe user profiles. How would you design and deploy a two-stage personalized search pipeline that ranks items according to the user’s history and preferences? How would you handle new users with little interaction data, and how would you ensure latency does not become a bottleneck? Explain all steps, including the approach to generating vectors, handling multiple interaction types, building the final ranking model, and addressing engineering challenges.
Proposed Detailed Solution
The search system is split into two passes: candidate retrieval and ranking. During candidate retrieval, the system scans millions of listings to find the top few thousand items matching the query. Those items then go into the ranking stage, which applies a gradient boosted decision tree. The personalized approach augments the existing ranking features with additional user-specific features.
Candidate Retrieval
The first pass retrieves a manageable subset of relevant items. It looks at the query and listing text (e.g. titles, tags) plus standard signals like listing quality, recency, and perhaps category alignment. This pass yields thousands of candidate listings.
Ranking With Personalization
The second pass re-ranks the candidate set. Traditional features remain, such as listing popularity, listing price, recency, and click-through rate. The personalized system adds features that represent a user’s past behaviors and preferences:
Historical User Features Numerical descriptors that capture user-level statistics, such as number of visits, purchase frequency, fraction of items purchased that are vintage, average session length, and so on.
Contextual User Features Vector embeddings that encode the kinds of items a user interacted with. The system uses several embedding types:
Term Frequency–Inverse Document Frequency (Tf-Idf): Listings become sparse vectors based on word importance. The user embedding is the average of all listings the user interacted with.
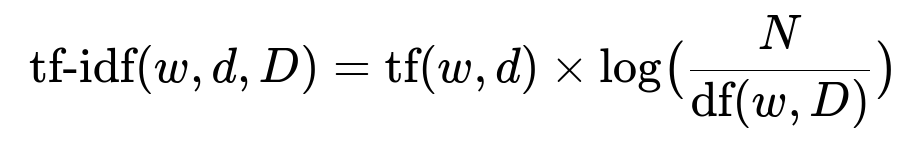
Here, w is a word in listing d, N is total number of listings in corpus D, tf(w,d) is word w’s count in d, and df(w, D) is the number of listings that contain w.
Interaction-Based Graph Embeddings: A sparse representation that uses interaction logs linking queries to listings. If multiple queries lead to the same listings, those listings share similar embedding coordinates. Averaging the embeddings of all listings a user interacted with yields a user-level embedding vector.
Item-Interaction Embeddings: A dense representation built by extending word2vec-like algorithms. Instead of sentences of words, the “sentences” are sequences of items, labeled by interaction type (click, favorite, etc.). The algorithm learns item embeddings that reflect co-occurrence patterns in user sessions. User embeddings are averages of all item embeddings the user interacted with.
The model can maintain multiple user embeddings by combining different interactions (clicks, favorites, add-to-carts, purchases) over different time windows (recent vs. lifetime). Each embedding captures a particular type of behavior. At ranking time, each candidate listing is compared to each relevant user embedding via similarity scores (e.g. Jaccard similarity, cosine similarity). These similarity scores become numeric inputs to the gradient boosted decision tree.
Handling New Users
When a user has minimal interaction history, the model must revert to a fallback. One approach is to initialize a default embedding as the mean of all user embeddings or use general popularity-based signals. As the user interacts more, the system updates the user embedding to reflect their personal tastes.
Caching and Latency
Because each user sees personalized results for a given query, the number of unique query-user combinations can grow quickly. This makes caching less efficient. Engineering optimizations include:
Partial caching for frequently repeated queries by user segments.
Real-time embedding vector lookups and similarity computations that efficiently handle vector data.
Storing precomputed user embeddings and carefully managing memory for large user populations.
Training
A gradient boosted decision tree with pairwise formulation or pointwise formulation is trained to predict user purchase probability (or any strong label). The model ingests standard ranking features plus the new personalized ones (historical user numeric stats, similarity scores between user embeddings and candidate listing embeddings). The model learns which features best predict purchases. Typically, the tree sees large improvements from the contextual embedding similarity features, especially when the user has extensive recent interactions.
Deployment
The system keeps user embeddings updated on a fixed schedule (e.g. daily or near real-time). The second-pass ranker looks up those embeddings each time the user runs a query. It computes the similarity with each candidate listing’s vector and then feeds the aggregated user historical features and contextual features into the gradient boosted tree. The system returns the top-ranked items.
No single embedding type suffices for all scenarios. Mixing text-based representations (Tf-Idf) with graph or item-interaction embeddings covers a broad range of user behaviors. Personalization is often stronger for users with a richer history. When a user’s needs deviate from their usual preferences, the query intent might differ from their past, so the ranker must balance personalization with the standard relevance signals.
How Do You Ensure the Embeddings Work for Different Interaction Types?
Dense embeddings like item-interaction embeddings can incorporate multiple interaction types into a single vector space. The system concatenates or merges representation from clicks, favorites, and purchases. The training process sees “token pairs” of (item, interaction-type), ensuring items that frequently co-occur under similar interaction types land in similar regions of embedding space. Another option is to create separate embeddings for each interaction type, then combine them at inference time.
Why Not Use Only Purchase Data for Building User Embeddings?
Purchase data is highly indicative of user preferences but sparse. Many users click or favorite items without always purchasing them, so restricting to purchases cuts out signals from items the user liked but did not buy. Mixing multiple signals captures a richer view of the user. When purchase signals are available, they carry higher weight during similarity calculations.
How Would You Train the Ranking Model to Accommodate All Personalization Features?
Construct training examples from past queries, items returned, and whether they were eventually purchased. For each example, compute user numeric features (average visits, digital vs. vintage ratio, etc.) and contextual similarity features (cosine similarity, Jaccard scores, etc.) between user embeddings and the item’s embedding. Feed these features into a gradient boosted decision tree. The model iteratively finds splits that maximize the likelihood of correctly ranking purchased items. Hyperparameter tuning includes:
Tree depth.
Learning rate.
Feature sub-sampling ratio.
How Do You Manage Cold Starts for Completely New Users?
Use general popularity-based ranking signals, fallback embeddings representing the global average user, or short-term context like the immediate session behavior. After a few clicks or favorites, the system updates the user’s embedding and begins personalizing. Another approach is to rely more heavily on the query’s textual relevance for first-time or low-engagement users.
How Would You Address Scalability for Millions of Users?
Store each user’s embedding in an efficient key-value store. Precompute embeddings on a schedule or compute them in streaming fashion if hardware permits. The ranking system pulls user embeddings at query time. Use approximate nearest neighbor libraries if needed for short-listing. Carefully monitor memory usage for embedding data.
How Do You Evaluate Success?
Track ranking metrics like normalized discounted cumulative gain (NDCG) and mean reciprocal rank (MRR) based on purchase signals. Measure how often users click fewer pages to find their items, or how quickly they add to cart. Check average order value changes, repeated buyer rates, and search satisfaction metrics. A/B test the personalized ranker vs. a control ranker, analyzing significance to confirm lift in conversion or other key metrics.